/config.json`.
>
> For the AvalancheGo node configuration options, see the AvalancheGo Configuration page.
This document describes all configuration options available for Subnet-EVM.
## Example Configuration
```json
{
"eth-apis": ["eth", "eth-filter", "net", "web3"],
"pruning-enabled": true,
"commit-interval": 4096,
"trie-clean-cache": 512,
"trie-dirty-cache": 512,
"snapshot-cache": 256,
"rpc-gas-cap": 50000000,
"log-level": "info",
"metrics-expensive-enabled": true,
"continuous-profiler-dir": "./profiles",
"state-sync-enabled": false,
"accepted-cache-size": 32
}
```
## Configuration Format
Configuration is provided as a JSON object. All fields are optional unless otherwise specified.
## API Configuration
### Ethereum APIs
| Option | Type | Description | Default |
| ---------- | ---------------- | ------------------------------------------------ | ----------------------------------------------------------------------------------------------------- |
| `eth-apis` | array of strings | List of Ethereum services that should be enabled | `["eth", "eth-filter", "net", "web3", "internal-eth", "internal-blockchain", "internal-transaction"]` |
### Subnet-EVM Specific APIs
| Option | Type | Description | Default |
| ------------------------ | ------ | -------------------------------------------------- | ------- |
| `validators-api-enabled` | bool | Enable the validators API | `true` |
| `admin-api-enabled` | bool | Enable the admin API for administrative operations | `false` |
| `admin-api-dir` | string | Directory for admin API operations | - |
| `warp-api-enabled` | bool | Enable the Warp API for cross-chain messaging | `false` |
### API Limits and Security
| Option | Type | Description | Default |
| ---------------------------- | -------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------------ |
| `rpc-gas-cap` | uint64 | Maximum gas limit for RPC calls | `50,000,000` |
| `rpc-tx-fee-cap` | float64 | Maximum transaction fee cap in AVAX | `100` |
| `api-max-duration` | duration | Maximum duration for API calls (0 = no limit) | `0` |
| `api-max-blocks-per-request` | int64 | Maximum number of blocks per getLogs request (0 = no limit) | `0` |
| `http-body-limit` | uint64 | Maximum size of HTTP request bodies | - |
| `batch-request-limit` | uint64 | Maximum number of requests that can be batched in an RPC call. For no limit, set either this or `batch-response-max-size` to 0 | `1000` |
| `batch-response-max-size` | uint64 | Maximum size (in bytes) of response that can be returned from a batched RPC call. For no limit, set either this or `batch-request-limit` to 0. Defaults to `25 MB` | `1000` |
### WebSocket Settings
| Option | Type | Description | Default |
| -------------------- | -------- | ------------------------------------------------------------------ | ------- |
| `ws-cpu-refill-rate` | duration | Rate at which WebSocket CPU usage quota is refilled (0 = no limit) | `0` |
| `ws-cpu-max-stored` | duration | Maximum stored WebSocket CPU usage quota (0 = no limit) | `0` |
## Cache Configuration
### Trie Caches
| Option | Type | Description | Default |
| ----------------------------- | ---- | -------------------------------------------------------------------------- | ------- |
| `trie-clean-cache` | int | Size of the trie clean cache in MB | `512` |
| `trie-dirty-cache` | int | Size of the trie dirty cache in MB | `512` |
| `trie-dirty-commit-target` | int | Memory limit to target in the dirty cache before performing a commit in MB | `20` |
| `trie-prefetcher-parallelism` | int | Maximum concurrent disk reads trie prefetcher should perform | `16` |
### Other Caches
| Option | Type | Description | Default |
| ------------------------------ | ---- | ------------------------------------------------------------- | ------- |
| `snapshot-cache` | int | Size of the snapshot disk layer clean cache in MB | `256` |
| `accepted-cache-size` | int | Depth to keep in the accepted headers and logs cache (blocks) | `32` |
| `state-sync-server-trie-cache` | int | Trie cache size for state sync server in MB | `64` |
## Ethereum Settings
### Transaction Processing
| Option | Type | Description | Default |
| ----------------------------- | ----- | ------------------------------------------------------------- | -------------------- |
| `preimages-enabled` | bool | Enable preimage recording | `false` |
| `allow-unfinalized-queries` | bool | Allow queries for unfinalized blocks | `false` |
| `allow-unprotected-txs` | bool | Allow unprotected transactions (without EIP-155) | `false` |
| `allow-unprotected-tx-hashes` | array | List of specific transaction hashes allowed to be unprotected | EIP-1820 registry tx |
| `local-txs-enabled` | bool | Enable treatment of transactions from local accounts as local | `false` |
### Snapshots
| Option | Type | Description | Default |
| ------------------------------- | ---- | --------------------------------------- | ------- |
| `snapshot-wait` | bool | Wait for snapshot generation on startup | `false` |
| `snapshot-verification-enabled` | bool | Enable snapshot verification | `false` |
## Pruning and State Management
### Basic Pruning
| Option | Type | Description | Default |
| ---------------------- | ------ | ---------------------------------------------------------- | ------- |
| `pruning-enabled` | bool | Enable state pruning to save disk space | `true` |
| `commit-interval` | uint64 | Interval at which to persist EVM and atomic tries (blocks) | `4096` |
| `accepted-queue-limit` | int | Maximum blocks to queue before blocking during acceptance | `64` |
### State Reconstruction
| Option | Type | Description | Default |
| ------------------------------------ | ------ | ---------------------------------------------------------------- | ------- |
| `allow-missing-tries` | bool | Suppress warnings about incomplete trie index | `false` |
| `populate-missing-tries` | uint64 | Starting block for re-populating missing tries (null = disabled) | `null` |
| `populate-missing-tries-parallelism` | int | Concurrent readers for re-populating missing tries | `1024` |
### Offline Pruning
| Option | Type | Description | Default |
| ----------------------------------- | ------ | ------------------------------------------- | ------- |
| `offline-pruning-enabled` | bool | Enable offline pruning | `false` |
| `offline-pruning-bloom-filter-size` | uint64 | Bloom filter size for offline pruning in MB | `512` |
| `offline-pruning-data-directory` | string | Directory for offline pruning data | - |
### Historical Data
| Option | Type | Description | Default |
| ------------------------------- | ------ | --------------------------------------------------------------------------------------- | ------- |
| `historical-proof-query-window` | uint64 | Number of blocks before last accepted for proof queries (archive mode only, \~24 hours) | `43200` |
| `state-history` | uint64 | Number of most recent states that are accesible on disk (pruning mode only) | `32` |
## Transaction Pool Configuration
| Option | Type | Description | Default |
| ----------------------- | -------- | ------------------------------------------------------------------- | ------- |
| `tx-pool-price-limit` | uint64 | Minimum gas price for transaction acceptance | - |
| `tx-pool-price-bump` | uint64 | Minimum price bump percentage for transaction replacement | - |
| `tx-pool-account-slots` | uint64 | Maximum number of executable transaction slots per account | - |
| `tx-pool-global-slots` | uint64 | Maximum number of executable transaction slots for all accounts | - |
| `tx-pool-account-queue` | uint64 | Maximum number of non-executable transaction slots per account | - |
| `tx-pool-global-queue` | uint64 | Maximum number of non-executable transaction slots for all accounts | - |
| `tx-pool-lifetime` | duration | Maximum time transactions can stay in the pool | - |
## Gossip Configuration
### Push Gossip Settings
| Option | Type | Description | Default |
| ---------------------------- | ------- | ------------------------------------------------------------ | ------- |
| `push-gossip-percent-stake` | float64 | Percentage of total stake to push gossip to (range: \[0, 1]) | `0.9` |
| `push-gossip-num-validators` | int | Number of validators to push gossip to | `100` |
| `push-gossip-num-peers` | int | Number of non-validator peers to push gossip to | `0` |
### Regossip Settings
| Option | Type | Description | Default |
| ------------------------------ | ----- | -------------------------------------------- | ------- |
| `push-regossip-num-validators` | int | Number of validators to regossip to | `10` |
| `push-regossip-num-peers` | int | Number of non-validator peers to regossip to | `0` |
| `priority-regossip-addresses` | array | Addresses to prioritize for regossip | - |
### Timing Configuration
| Option | Type | Description | Default |
| ----------------------- | -------- | ------------------------ | ------- |
| `push-gossip-frequency` | duration | Frequency of push gossip | `100ms` |
| `pull-gossip-frequency` | duration | Frequency of pull gossip | `1s` |
| `regossip-frequency` | duration | Frequency of regossip | `30s` |
## Logging and Monitoring
### Logging
| Option | Type | Description | Default |
| ----------------- | ------ | ----------------------------------------------------- | -------- |
| `log-level` | string | Logging level (trace, debug, info, warn, error, crit) | `"info"` |
| `log-json-format` | bool | Use JSON format for logs | `false` |
### Profiling
| Option | Type | Description | Default |
| ------------------------------- | -------- | ----------------------------------------------------------- | ------- |
| `continuous-profiler-dir` | string | Directory for continuous profiler output (empty = disabled) | - |
| `continuous-profiler-frequency` | duration | Frequency to run continuous profiler | `15m` |
| `continuous-profiler-max-files` | int | Maximum number of profiler files to maintain | `5` |
### Metrics
| Option | Type | Description | Default |
| --------------------------- | ---- | -------------------------------------------------------------------- | ------- |
| `metrics-expensive-enabled` | bool | Enable expensive debug-level metrics; this includes Firewood metrics | `true` |
## Security and Access
### Keystore
| Option | Type | Description | Default |
| ---------------------------------- | ------ | -------------------------------------------------------- | ------- |
| `keystore-directory` | string | Directory for keystore files (absolute or relative path) | - |
| `keystore-external-signer` | string | External signer configuration | - |
| `keystore-insecure-unlock-allowed` | bool | Allow insecure account unlocking | `false` |
### Fee Configuration
| Option | Type | Description | Default |
| -------------- | ------ | ------------------------------------------------------------------ | ------- |
| `feeRecipient` | string | Address to send transaction fees to (leave empty if not supported) | - |
## Network and Sync
### Network
| Option | Type | Description | Default |
| ------------------------------ | ----- | ------------------------------------------------------------ | ------- |
| `max-outbound-active-requests` | int64 | Maximum number of outbound active requests for VM2VM network | `16` |
### State Sync
| Option | Type | Description | Default |
| ---------------------------- | ------ | ------------------------------------------------------- | -------- |
| `state-sync-enabled` | bool | Enable state sync | `false` |
| `state-sync-skip-resume` | bool | Force state sync to use highest available summary block | `false` |
| `state-sync-ids` | string | Comma-separated list of state sync IDs | - |
| `state-sync-commit-interval` | uint64 | Commit interval for state sync (blocks) | `16384` |
| `state-sync-min-blocks` | uint64 | Minimum blocks ahead required for state sync | `300000` |
| `state-sync-request-size` | uint16 | Number of key/values to request per state sync request | `1024` |
## Database Configuration
> **WARNING**: `firewood` and `path` schemes are untested in production. Using `path` is strongly discouraged. To use `firewood`, you must also set the following config options:
>
> * `pruning-enabled: true` (enabled by default)
> * `state-sync-enabled: false`
> * `snapshot-cache: 0`
Failing to set these options will result in errors on VM initialization. Additionally, not all APIs are available - see these portions of the config documentation for more details.
| Option | Type | Description | Default |
| ------------------------- | ------ | --------------------------------------------------------------------------------------------------- | ------------ |
| `database-type` | string | Type of database to use | `"pebbledb"` |
| `database-path` | string | Path to database directory | - |
| `database-read-only` | bool | Open database in read-only mode | `false` |
| `database-config` | string | Inline database configuration | - |
| `database-config-file` | string | Path to database configuration file | - |
| `use-standalone-database` | bool | Use standalone database instead of shared one | - |
| `inspect-database` | bool | Inspect database on startup | `false` |
| `state-scheme` | string | EXPERIMENTAL: specifies the database scheme to store state data; can be one of `hash` or `firewood` | `hash` |
## Transaction Indexing
| Option | Type | Description | Default |
| --------------------- | ------ | ---------------------------------------------------------------------------------------- | ------- |
| `transaction-history` | uint64 | Maximum number of blocks from head whose transaction indices are reserved (0 = no limit) | - |
| `tx-lookup-limit` | uint64 | **Deprecated** - use `transaction-history` instead | - |
| `skip-tx-indexing` | bool | Skip indexing transactions entirely | `false` |
## Warp Configuration
| Option | Type | Description | Default |
| ------------------------- | ----- | ----------------------------------------------------- | ------- |
| `warp-off-chain-messages` | array | Off-chain messages the node should be willing to sign | - |
| `prune-warp-db-enabled` | bool | Clear warp database on startup | `false` |
## Miscellaneous
| Option | Type | Description | Default |
| -------------------- | ------- | -------------------------------------------------------------------------------------------------------------------------- | --------------------- |
| `airdrop` | string | Path to airdrop file | - |
| `skip-upgrade-check` | bool | Skip checking that upgrades occur before last accepted block ⚠️ **Warning**: Only use when you understand the implications | `false` |
| `min-delay-target` | integer | The minimum delay between blocks (in milliseconds) that this node will attempt to use when creating blocks | Parent block's target |
## Gossip Constants
The following constants are defined for transaction gossip behavior and cannot be configured without a custom build of Subnet-EVM:
| Constant | Type | Description | Value |
| --------------------------------------- | -------- | ------------------------------------------ | -------- |
| Bloom Filter Min Target Elements | int | Minimum target elements for bloom filter | `8,192` |
| Bloom Filter Target False Positive Rate | float | Target false positive rate | `1%` |
| Bloom Filter Reset False Positive Rate | float | Reset false positive rate | `5%` |
| Bloom Filter Churn Multiplier | int | Churn multiplier | `3` |
| Push Gossip Discarded Elements | int | Number of discarded elements | `16,384` |
| Tx Gossip Target Message Size | size | Target message size for transaction gossip | `20 KiB` |
| Tx Gossip Throttling Period | duration | Throttling period | `10s` |
| Tx Gossip Throttling Limit | int | Throttling limit | `2` |
| Tx Gossip Poll Size | int | Poll size | `1` |
## Validation Notes
* Cannot enable `populate-missing-tries` while pruning or offline pruning is enabled
* Cannot run offline pruning while pruning is disabled
* Commit interval must be non-zero when pruning is enabled
* `push-gossip-percent-stake` must be in range `[0, 1]`
* Some settings may require node restart to take effect
# X-Chain Configs
URL: /docs/nodes/chain-configs/x-chain
This page describes the configuration options available for the X-Chain.
In order to specify a config for the X-Chain, a JSON config file should be
placed at `{chain-config-dir}/X/config.json`.
For example if `chain-config-dir` has the default value which is
`$HOME/.avalanchego/configs/chains`, then `config.json` can be placed at
`$HOME/.avalanchego/configs/chains/X/config.json`.
This allows you to specify a config to be passed into the X-Chain. The default
values for this config are:
```json
{
"checksums-enabled": false
}
```
Default values are overridden only if explicitly specified in the config.
The parameters are as follows:
### `checksums-enabled`
*Boolean*
Enables checksums if set to `true`.
# Avalanche L1 Configs
URL: /docs/nodes/configure/avalanche-l1-configs
This page describes the configuration options available for Avalanche L1s.
# Subnet Configs
It is possible to provide parameters for a Subnet. Parameters here apply to all
chains in the specified Subnet.
AvalancheGo looks for files specified with `{subnetID}.json` under
`--subnet-config-dir` as documented
[here](https://build.avax.network/docs/nodes/configure/configs-flags#subnet-configs).
Here is an example of Subnet config file:
```json
{
"validatorOnly": false,
"consensusParameters": {
"k": 25,
"alpha": 18
}
}
```
## Parameters
### Private Subnet
#### `validatorOnly` (bool)
If `true` this node does not expose Subnet blockchain contents to non-validators
via P2P messages. Defaults to `false`.
Avalanche Subnets are public by default. It means that every node can sync and
listen ongoing transactions/blocks in Subnets, even they're not validating the
listened Subnet.
Subnet validators can choose not to publish contents of blockchains via this
configuration. If a node sets `validatorOnly` to true, the node exchanges
messages only with this Subnet's validators. Other peers will not be able to
learn contents of this Subnet from this node.
:::tip
This is a node-specific configuration. Every validator of this Subnet has to use
this configuration in order to create a full private Subnet.
:::
#### `allowedNodes` (string list)
If `validatorOnly=true` this allows explicitly specified NodeIDs to be allowed
to sync the Subnet regardless of validator status. Defaults to be empty.
:::tip
This is a node-specific configuration. Every validator of this Subnet has to use
this configuration in order to properly allow a node in the private Subnet.
:::
### Consensus Parameters
Subnet configs supports loading new consensus parameters. JSON keys are
different from their matching `CLI` keys. These parameters must be grouped under
`consensusParameters` key. The consensus parameters of a Subnet default to the
same values used for the Primary Network, which are given [CLI Snow Parameters](https://build.avax.network/docs/nodes/configure/configs-flags#snow-parameters).
| CLI Key | JSON Key |
| :--------------------------- | :-------------------- |
| --snow-sample-size | k |
| --snow-quorum-size | alpha |
| --snow-commit-threshold | `beta` |
| --snow-concurrent-repolls | concurrentRepolls |
| --snow-optimal-processing | `optimalProcessing` |
| --snow-max-processing | maxOutstandingItems |
| --snow-max-time-processing | maxItemProcessingTime |
| --snow-avalanche-batch-size | `batchSize` |
| --snow-avalanche-num-parents | `parentSize` |
#### `proposerMinBlockDelay` (duration)
The minimum delay performed when building snowman++ blocks. Default is set to 1 second.
As one of the ways to control network congestion, Snowman++ will only build a
block `proposerMinBlockDelay` after the parent block's timestamp. Some
high-performance custom VM may find this too strict. This flag allows tuning the
frequency at which blocks are built.
### Gossip Configs
It's possible to define different Gossip configurations for each Subnet without
changing values for Primary Network. JSON keys of these
parameters are different from their matching `CLI` keys. These parameters
default to the same values used for the Primary Network. For more information
see [CLI Gossip Configs](https://build.avax.network/docs/nodes/configure/configs-flags#gossiping).
| CLI Key | JSON Key |
| :------------------------------------------------------ | :------------------------------------- |
| --consensus-accepted-frontier-gossip-validator-size | gossipAcceptedFrontierValidatorSize |
| --consensus-accepted-frontier-gossip-non-validator-size | gossipAcceptedFrontierNonValidatorSize |
| --consensus-accepted-frontier-gossip-peer-size | gossipAcceptedFrontierPeerSize |
| --consensus-on-accept-gossip-validator-size | gossipOnAcceptValidatorSize |
| --consensus-on-accept-gossip-non-validator-size | gossipOnAcceptNonValidatorSize |
| --consensus-on-accept-gossip-peer-size | gossipOnAcceptPeerSize |
# AvalancheGo Config Flags
URL: /docs/nodes/configure/configs-flags
This page lists all available configuration options for AvalancheGo nodes.
# AvalancheGo Configs and Flags
This document lists all available configuration options for AvalancheGo nodes. You can configure your node using either command-line flags or environment variables.
> **Note:** For comparison with the previous documentation format (using individual flag headings), see the [archived version](https://gist.github.com/navillanueva/cdb9c49c411bd89a9480f05a7afbab37).
## Environment Variable Naming Convention
All environment variables follow the pattern: `AVAGO_` + flag name where the flag name is converted to uppercase with hyphens replaced by underscores.
For example:
* Flag: `--api-admin-enabled`
* Environment Variable: `AVAGO_API_ADMIN_ENABLED`
## Example Usage
### Using Command-Line Flags
```bash
avalanchego --network-id=fuji --http-host=0.0.0.0 --log-level=debug
```
### Using Environment Variables
```bash
export AVAGO_NETWORK_ID=fuji
export AVAGO_HTTP_HOST=0.0.0.0
export AVAGO_LOG_LEVEL=debug
avalanchego
```
### Using Config File
Create a JSON config file:
```json
{
"network-id": "fuji",
"http-host": "0.0.0.0",
"log-level": "debug"
}
```
Run with:
```bash
avalanchego --config-file=/path/to/config.json
```
## Configuration Precedence
Configuration sources are applied in the following order (highest to lowest precedence):
1. Command-line flags
2. Environment variables
3. Config file
4. Default values
# Configuration Options
### APIs
Configuration for various APIs exposed by the node.
| Flag | Env Var | Type | Default | Description |
| ----------------------- | --------------------------- | ---- | ------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--api-admin-enabled` | `AVAGO_API_ADMIN_ENABLED` | bool | `false` | If set to `true`, this node will expose the Admin API. See [here](https://build.avax.network/docs/api-reference/admin-api) for more information. |
| `--api-health-enabled` | `AVAGO_API_HEALTH_ENABLED` | bool | `true` | If set to `false`, this node will not expose the Health API. See [here](https://build.avax.network/docs/api-reference/health-api) for more information. |
| `--index-enabled` | `AVAGO_INDEX_ENABLED` | bool | `false` | If set to `true`, this node will enable the indexer and the Index API will be available. See [here](https://build.avax.network/docs/api-reference/index-api) for more information. |
| `--api-info-enabled` | `AVAGO_API_INFO_ENABLED` | bool | `true` | If set to `false`, this node will not expose the Info API. See [here](https://build.avax.network/docs/api-reference/info-api) for more information. |
| `--api-metrics-enabled` | `AVAGO_API_METRICS_ENABLED` | bool | `true` | If set to `false`, this node will not expose the Metrics API. See [here](https://build.avax.network/docs/api-reference/metrics-api) for more information. |
### Avalanche Community Proposals
Support for [Avalanche Community Proposals](https://github.com/avalanche-foundation/ACPs).
| Flag | Env Var | Type | Default | Description |
| --------------- | ------------------- | ------ | ------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--acp-support` | `AVAGO_ACP_SUPPORT` | \[]int | `[]` | The `--acp-support` flag allows an AvalancheGo node to indicate support for a set of [Avalanche Community Proposals](https://github.com/avalanche-foundation/ACPs). |
| `--acp-object` | `AVAGO_ACP_OBJECT` | \[]int | `[]` | The `--acp-object` flag allows an AvalancheGo node to indicate objection for a set of [Avalanche Community Proposals](https://github.com/avalanche-foundation/ACPs). |
### Bootstrapping
Configuration for node bootstrapping process.
| Flag | Env Var | Type | Default | Description |
| ----------------------------------------------- | --------------------------------------------------- | -------- | ----------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--bootstrap-ancestors-max-containers-sent` | `AVAGO_BOOTSTRAP_ANCESTORS_MAX_CONTAINERS_SENT` | uint | `2000` | Max number of containers in an `Ancestors` message sent by this node. |
| `--bootstrap-ancestors-max-containers-received` | `AVAGO_BOOTSTRAP_ANCESTORS_MAX_CONTAINERS_RECEIVED` | uint | `2000` | This node reads at most this many containers from an incoming `Ancestors` message. |
| `--bootstrap-beacon-connection-timeout` | `AVAGO_BOOTSTRAP_BEACON_CONNECTION_TIMEOUT` | duration | `1m` | Timeout when attempting to connect to bootstrapping beacons. |
| `--bootstrap-ids` | `AVAGO_BOOTSTRAP_IDS` | string | network dependent | Bootstrap IDs is a comma-separated list of validator IDs. These IDs will be used to authenticate bootstrapping peers. An example setting of this field would be `--bootstrap-ids="NodeID-7Xhw2mDxuDS44j42TCB6U5579esbSt3Lg,NodeID-MFrZFVCXPv5iCn6M9K6XduxGTYp891xXZ"`. The number of given IDs here must be same with number of given `--bootstrap-ips`. The default value depends on the network ID. |
| `--bootstrap-ips` | `AVAGO_BOOTSTRAP_IPS` | string | network dependent | Bootstrap IPs is a comma-separated list of IP:port pairs. These IP Addresses will be used to bootstrap the current Avalanche state. An example setting of this field would be `--bootstrap-ips="127.0.0.1:12345,1.2.3.4:5678"`. The number of given IPs here must be same with number of given `--bootstrap-ids`. The default value depends on the network ID. |
| `--bootstrap-max-time-get-ancestors` | `AVAGO_BOOTSTRAP_MAX_TIME_GET_ANCESTORS` | duration | `50ms` | Max Time to spend fetching a container and its ancestors when responding to a GetAncestors message. |
| `--bootstrap-retry-enabled` | `AVAGO_BOOTSTRAP_RETRY_ENABLED` | bool | `true` | If set to `false`, will not retry bootstrapping if it fails. |
| `--bootstrap-retry-warn-frequency` | `AVAGO_BOOTSTRAP_RETRY_WARN_FREQUENCY` | uint | `50` | Specifies how many times bootstrap should be retried before warning the operator. |
### Chain Configuration
Some blockchains allow the node operator to provide custom configurations for individual blockchains. These custom configurations are broken down into two categories: network upgrades and optional chain configurations. AvalancheGo reads in these configurations from the chain configuration directory and passes them into the VM on initialization.
| Flag | Env Var | Type | Default | Description |
| ------------------------------ | ---------------------------------- | ------ | -------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| `--chain-config-dir` | `AVAGO_CHAIN_CONFIG_DIR` | string | `$HOME/.avalanchego/configs/chains` | Specifies the directory that contains chain configs, as described [here](https://build.avax.network/docs/nodes/chain-configs). If this flag is not provided and the default directory does not exist, AvalancheGo will not exit since custom configs are optional. However, if the flag is set, the specified folder must exist, or AvalancheGo will exit with an error. This flag is ignored if `--chain-config-content` is specified. Network upgrades are passed in from the location: `chain-config-dir`/`blockchainID`/`upgrade.*`. The chain configs are passed in from the location `chain-config-dir`/`blockchainID`/`config.*`. See [here](https://build.avax.network/docs/nodes/chain-configs) for more information. |
| `--chain-config-content` | `AVAGO_CHAIN_CONFIG_CONTENT` | string | - | As an alternative to `--chain-config-dir`, chains custom configurations can be loaded altogether from command line via `--chain-config-content` flag. Content must be base64 encoded. Example: First, encode the chain config: `echo -n '{"log-level":"trace"}' \| base64`. This will output something like `eyJsb2ctbGV2ZWwiOiJ0cmFjZSJ9`. Then create the full config JSON and encode it: `echo -n '{"C":{"Config":"eyJsb2ctbGV2ZWwiOiJ0cmFjZSJ9","Upgrade":null}}' \| base64`. Finally run: `avalanchego --chain-config-content "eyJDIjp7IkNvbmZpZyI6ImV5SnNiMmN0YkdWMlpXd2lPaUowY21GalpTSjkiLCJVcGdyYWRlIjpudWxsfX0="` |
| `--chain-aliases-file` | `AVAGO_CHAIN_ALIASES_FILE` | string | `~/.avalanchego/configs/chains/aliases.json` | Path to JSON file that defines aliases for Blockchain IDs. This flag is ignored if `--chain-aliases-file-content` is specified. Example content: `{"q2aTwKuyzgs8pynF7UXBZCU7DejbZbZ6EUyHr3JQzYgwNPUPi": ["DFK"]}`. The above example aliases the Blockchain whose ID is `"q2aTwKuyzgs8pynF7UXBZCU7DejbZbZ6EUyHr3JQzYgwNPUPi"` to `"DFK"`. Chain aliases are added after adding primary network aliases and before any changes to the aliases via the admin API. This means that the first alias included for a Blockchain on a Subnet will be treated as the `"Primary Alias"` instead of the full blockchainID. The Primary Alias is used in all metrics and logs. |
| `--chain-aliases-file-content` | `AVAGO_CHAIN_ALIASES_FILE_CONTENT` | string | - | As an alternative to `--chain-aliases-file`, it allows specifying base64 encoded aliases for Blockchains. |
| `--chain-data-dir` | `AVAGO_CHAIN_DATA_DIR` | string | `$HOME/.avalanchego/chainData` | Chain specific data directory. |
### Config File
| Flag | Env Var | Type | Default | Description |
| ---------------------------- | -------------------------------- | ------ | ------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--config-file` | `AVAGO_CONFIG_FILE` | string | - | Path to a JSON file that specifies this node's configuration. Command line arguments will override arguments set in the config file. This flag is ignored if `--config-file-content` is specified. Example JSON config file: `{"log-level": "debug"}`. [Install Script](https://build.avax.network/docs/tooling/avalanche-go-installer) creates the node config file at `~/.avalanchego/configs/node.json`. No default file is created if [AvalancheGo is built from source](https://build.avax.network/docs/nodes/run-a-node/from-source), you would need to create it manually if needed. |
| `--config-file-content` | `AVAGO_CONFIG_FILE_CONTENT` | string | - | As an alternative to `--config-file`, it allows specifying base64 encoded config content. |
| `--config-file-content-type` | `AVAGO_CONFIG_FILE_CONTENT_TYPE` | string | `JSON` | Specifies the format of the base64 encoded config content. JSON, TOML, YAML are among currently supported file format (see [here](https://github.com/spf13/viper#reading-config-files) for full list). |
### Data Directory
| Flag | Env Var | Type | Default | Description |
| ------------ | ---------------- | ------ | -------------------- | ----------------------------------------------------------------------------------------------------- |
| `--data-dir` | `AVAGO_DATA_DIR` | string | `$HOME/.avalanchego` | Sets the base data directory where default sub-directories will be placed unless otherwise specified. |
### Database
| Flag | Env Var | Type | Default | Description |
| ----------- | --------------- | ------ | ----------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--db-dir` | `AVAGO_DB_DIR` | string | `$HOME/.avalanchego/db` | Specifies the directory to which the database is persisted. |
| `--db-type` | `AVAGO_DB_TYPE` | string | `leveldb` | Specifies the type of database to use. Must be one of `leveldb`, `memdb`, or `pebbledb`. `memdb` is an in-memory, non-persisted database. Note: `memdb` stores everything in memory. So if you have a 900 GiB LevelDB instance, then using `memdb` you'd need 900 GiB of RAM. `memdb` is useful for fast one-off testing, not for running an actual node (on Fuji or Mainnet). Also note that `memdb` doesn't persist after restart. So any time you restart the node it would start syncing from scratch. |
#### Database Config
| Flag | Env Var | Type | Default | Description |
| -------------------------- | ------------------------------ | ------ | ------- | ----------------------------------------------------------------------------------------------------- |
| `--db-config-file` | `AVAGO_DB_CONFIG_FILE` | string | - | Path to the database config file. Ignored if `--db-config-file-content` is specified. |
| `--db-config-file-content` | `AVAGO_DB_CONFIG_FILE_CONTENT` | string | - | As an alternative to `--db-config-file`, it allows specifying base64 encoded database config content. |
A LevelDB config file must be JSON and may have these keys. Any keys not given will receive the default value. See [here](https://pkg.go.dev/github.com/syndtr/goleveldb/leveldb/opt#Options) for more information.
### File Descriptor Limit
| Flag | Env Var | Type | Default | Description |
| ------------ | ---------------- | ---- | ------- | -------------------------------------------------------------------------------------------------------------------------- |
| `--fd-limit` | `AVAGO_FD_LIMIT` | int | `32768` | Attempts to raise the process file descriptor limit to at least this value and error if the value is above the system max. |
### Genesis
| Flag | Env Var | Type | Default | Description |
| ------------------------ | ---------------------------- | ------ | ------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--genesis-file` | `AVAGO_GENESIS_FILE` | string | - | Path to a JSON file containing the genesis data to use. Ignored when running standard networks (Mainnet, Fuji Testnet), or when `--genesis-file-content` is specified. If not given, uses default genesis data. See the documentation for the genesis JSON format [here](https://github.com/ava-labs/avalanchego/blob/master/genesis/README.md) and an example for a local network [here](https://github.com/ava-labs/avalanchego/blob/master/genesis/genesis_local.json). |
| `--genesis-file-content` | `AVAGO_GENESIS_FILE_CONTENT` | string | - | As an alternative to `--genesis-file`, it allows specifying base64 encoded genesis data to use. |
### HTTP Server
| Flag | Env Var | Type | Default | Description |
| ------------------------------ | ---------------------------------- | -------- | ----------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--http-allowed-hosts` | `AVAGO_HTTP_ALLOWED_HOSTS` | string | `localhost` | List of acceptable host names in API requests. Provide the wildcard (`'*'`) to accept requests from all hosts. API requests where the `Host` field is empty or an IP address will always be accepted. An API call whose HTTP `Host` field isn't acceptable will receive a 403 error code. |
| `--http-allowed-origins` | `AVAGO_HTTP_ALLOWED_ORIGINS` | string | `*` | Origins to allow on the HTTP port. Example: `"https://*.avax.network https://*.avax-test.network"` |
| `--http-host` | `AVAGO_HTTP_HOST` | string | `127.0.0.1` | The address that HTTP APIs listen on. This means that by default, your node can only handle API calls made from the same machine. To allow API calls from other machines, use `--http-host=`. You can also enter domain names as parameter. |
| `--http-port` | `AVAGO_HTTP_PORT` | int | `9650` | Each node runs an HTTP server that provides the APIs for interacting with the node and the Avalanche network. This argument specifies the port that the HTTP server will listen on. |
| `--http-idle-timeout` | `AVAGO_HTTP_IDLE_TIMEOUT` | duration | `120s` | Maximum duration to wait for the next request when keep-alives are enabled. If `--http-idle-timeout` is zero, the value of `--http-read-timeout` is used. If both are zero, there is no timeout. |
| `--http-read-timeout` | `AVAGO_HTTP_READ_TIMEOUT` | duration | `30s` | Maximum duration for reading the entire request, including the body. A zero or negative value means there will be no timeout. |
| `--http-read-header-timeout` | `AVAGO_HTTP_READ_HEADER_TIMEOUT` | duration | `30s` | Maximum duration to read request headers. The connection's read deadline is reset after reading the headers. If `--http-read-header-timeout` is zero, the value of `--http-read-timeout` is used. If both are zero, there is no timeout. |
| `--http-write-timeout` | `AVAGO_HTTP_WRITE_TIMEOUT` | duration | `30s` | Maximum duration before timing out writes of the response. It is reset whenever a new request's header is read. A zero or negative value means there will be no timeout. |
| `--http-shutdown-timeout` | `AVAGO_HTTP_SHUTDOWN_TIMEOUT` | duration | `10s` | Maximum duration to wait for existing connections to complete during node shutdown. |
| `--http-shutdown-wait` | `AVAGO_HTTP_SHUTDOWN_WAIT` | duration | `0s` | Duration to wait after receiving SIGTERM or SIGINT before initiating shutdown. The `/health` endpoint will return unhealthy during this duration (if the Health API is enabled.) |
| `--http-tls-enabled` | `AVAGO_HTTP_TLS_ENABLED` | boolean | `false` | If set to `true`, this flag will attempt to upgrade the server to use HTTPS. |
| `--http-tls-cert-file` | `AVAGO_HTTP_TLS_CERT_FILE` | string | - | This argument specifies the location of the TLS certificate used by the node for the HTTPS server. This must be specified when `--http-tls-enabled=true`. There is no default value. This flag is ignored if `--http-tls-cert-file-content` is specified. |
| `--http-tls-cert-file-content` | `AVAGO_HTTP_TLS_CERT_FILE_CONTENT` | string | - | As an alternative to `--http-tls-cert-file`, it allows specifying base64 encoded content of the TLS certificate used by the node for the HTTPS server. Note that full certificate content, with the leading and trailing header, must be base64 encoded. This must be specified when `--http-tls-enabled=true`. |
| `--http-tls-key-file` | `AVAGO_HTTP_TLS_KEY_FILE` | string | - | This argument specifies the location of the TLS private key used by the node for the HTTPS server. This must be specified when `--http-tls-enabled=true`. There is no default value. This flag is ignored if `--http-tls-key-file-content` is specified. |
| `--http-tls-key-file-content` | `AVAGO_HTTP_TLS_KEY_FILE_CONTENT` | string | - | As an alternative to `--http-tls-key-file`, it allows specifying base64 encoded content of the TLS private key used by the node for the HTTPS server. Note that full private key content, with the leading and trailing header, must be base64 encoded. This must be specified when `--http-tls-enabled=true`. |
### Logging
| Flag | Env Var | Type | Default | Description |
| ----------------------------------- | --------------------------------------- | ------- | ------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--log-level=off` | `AVAGO_LOG_LEVEL` | string | `info` | No logs. |
| `--log-level=fatal` | `AVAGO_LOG_LEVEL` | string | `info` | Fatal errors that are not recoverable. |
| `--log-level=error` | `AVAGO_LOG_LEVEL` | string | `info` | Errors that the node encounters, these errors were able to be recovered. |
| `--log-level=warn` | `AVAGO_LOG_LEVEL` | string | `info` | Warnings that might be indicative of a spurious byzantine node, or potential future error. |
| `--log-level=info` | `AVAGO_LOG_LEVEL` | string | `info` | Useful descriptions of node status updates. |
| `--log-level=trace` | `AVAGO_LOG_LEVEL` | string | `info` | Traces container job results, useful for tracing container IDs and their outcomes. |
| `--log-level=debug` | `AVAGO_LOG_LEVEL` | string | `info` | Useful when attempting to understand possible bugs in the code. |
| `--log-level=verbo` | `AVAGO_LOG_LEVEL` | string | `info` | Tracks extensive amounts of information the node is processing, including message contents and binary dumps of data for extremely low level protocol analysis. |
| `--log-display-level` | `AVAGO_LOG_DISPLAY_LEVEL` | string | value of `--log-level` | The log level determines which events to display to stdout. If left blank, will default to the value provided to `--log-level`. |
| `--log-format=auto` | `AVAGO_LOG_FORMAT` | string | `auto` | Formats terminal-like logs when the output is a terminal. |
| `--log-format=plain` | `AVAGO_LOG_FORMAT` | string | `auto` | Plain text log format. |
| `--log-format=colors` | `AVAGO_LOG_FORMAT` | string | `auto` | Colored log format. |
| `--log-format=json` | `AVAGO_LOG_FORMAT` | string | `auto` | JSON log format. |
| `--log-dir` | `AVAGO_LOG_DIR` | string | `$HOME/.avalanchego/logs` | Specifies the directory in which system logs are kept. If you are running the node as a system service (ex. using the installer script) logs will also be stored in `$HOME/var/log/syslog`. |
| `--log-disable-display-plugin-logs` | `AVAGO_LOG_DISABLE_DISPLAY_PLUGIN_LOGS` | boolean | `false` | Disables displaying plugin logs in stdout. |
| `--log-rotater-max-size` | `AVAGO_LOG_ROTATER_MAX_SIZE` | uint | `8` | The maximum file size in megabytes of the log file before it gets rotated. |
| `--log-rotater-max-files` | `AVAGO_LOG_ROTATER_MAX_FILES` | uint | `7` | The maximum number of old log files to retain. 0 means retain all old log files. |
| `--log-rotater-max-age` | `AVAGO_LOG_ROTATER_MAX_AGE` | uint | `0` | The maximum number of days to retain old log files based on the timestamp encoded in their filename. 0 means retain all old log files. |
| `--log-rotater-compress-enabled` | `AVAGO_LOG_ROTATER_COMPRESS_ENABLED` | boolean | `false` | Enables the compression of rotated log files through gzip. |
### Continuous Profiling
You can configure your node to continuously run memory/CPU profiles and save the most recent ones. Continuous memory/CPU profiling is enabled if `--profile-continuous-enabled` is set.
| Flag | Env Var | Type | Default | Description |
| -------------------------------- | ------------------------------------ | -------- | ------------------------------ | ------------------------------------------------------------------------------------------------- |
| `--profile-continuous-enabled` | `AVAGO_PROFILE_CONTINUOUS_ENABLED` | boolean | `false` | Whether the app should continuously produce performance profiles. |
| `--profile-dir` | `AVAGO_PROFILE_DIR` | string | `$HOME/.avalanchego/profiles/` | If profiling enabled, node continuously runs memory/CPU profiles and puts them at this directory. |
| `--profile-continuous-freq` | `AVAGO_PROFILE_CONTINUOUS_FREQ` | duration | `15m` | How often a new CPU/memory profile is created. |
| `--profile-continuous-max-files` | `AVAGO_PROFILE_CONTINUOUS_MAX_FILES` | int | `5` | Maximum number of CPU/memory profiles files to keep. |
### Network
| Flag | Env Var | Type | Default | Description |
| --------------------------- | ------------------ | ------ | --------- | ------------------------------------------------------------------------------- |
| `--network-id=mainnet` | `AVAGO_NETWORK_ID` | string | `mainnet` | Connect to Mainnet (default). |
| `--network-id=fuji` | `AVAGO_NETWORK_ID` | string | `mainnet` | Connect to the Fuji test-network. |
| `--network-id=testnet` | `AVAGO_NETWORK_ID` | string | `mainnet` | Connect to the current test-network (currently Fuji). |
| `--network-id=local` | `AVAGO_NETWORK_ID` | string | `mainnet` | Connect to a local test-network. |
| `--network-id=network-[id]` | `AVAGO_NETWORK_ID` | string | `mainnet` | Connect to the network with the given ID. `id` must be in the range \[0, 2^32). |
### OpenTelemetry
AvalancheGo supports collecting and exporting [OpenTelemetry](https://opentelemetry.io/) traces. This might be useful for debugging, performance analysis, or monitoring.
| Flag | Env Var | Type | Default | Description |
| ------------------------- | ----------------------------- | ------- | -------------------------------------------------- | ----------------------------------------------------------------------------------- |
| `--tracing-endpoint` | `AVAGO_TRACING_ENDPOINT` | string | `localhost:4317` (gRPC) or `localhost:4318` (HTTP) | The endpoint to export trace data to. Default depends on `--tracing-exporter-type`. |
| `--tracing-exporter-type` | `AVAGO_TRACING_EXPORTER_TYPE` | string | `disabled` | Type of exporter to use for tracing. Options are \`disabled\`, \`grpc\`, \`http\`. |
| `--tracing-insecure` | `AVAGO_TRACING_INSECURE` | boolean | `true` | If true, don't use TLS when exporting trace data. |
| `--tracing-sample-rate` | `AVAGO_TRACING_SAMPLE_RATE` | float | `0.1` | The fraction of traces to sample. If >= 1, always sample. If \<= 0, never sample. |
### Partial Sync Primary Network
| Flag | Env Var | Type | Default | Description |
| -------------------------------- | ------------------------------------ | ------- | ------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| `--partial-sync-primary-network` | `AVAGO_PARTIAL_SYNC_PRIMARY_NETWORK` | boolean | `false` | Partial sync enables nodes that are not primary network validators to optionally sync only the P-chain on the primary network. Nodes that use this option can still track Subnets. After the Etna upgrade, nodes that use this option can also validate L1s. |
### Public IP
Validators must know one of their public facing IP addresses so they can enable other nodes to connect to them. By default, the node will attempt to perform NAT traversal to get the node's IP according to its router.
| Flag | Env Var | Type | Default | Description |
| ---------------------------------- | -------------------------------------- | -------- | ------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--public-ip` | `AVAGO_PUBLIC_IP` | string | - | If this argument is provided, the node assumes this is its public IP. When running a local network it may be easiest to set this value to `127.0.0.1`. |
| `--public-ip-resolution-frequency` | `AVAGO_PUBLIC_IP_RESOLUTION_FREQUENCY` | duration | `5m` | Frequency at which this node resolves/updates its public IP and renew NAT mappings, if applicable. |
| `--public-ip-resolution-service` | `AVAGO_PUBLIC_IP_RESOLUTION_SERVICE` | string | - | When provided, the node will use that service to periodically resolve/update its public IP. Only acceptable values are `ifconfigCo`, `opendns` or `ifconfigMe`. |
### State Syncing
| Flag | Env Var | Type | Default | Description |
| ------------------ | ---------------------- | ------ | ------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| `--state-sync-ids` | `AVAGO_STATE_SYNC_IDS` | string | - | State sync IDs is a comma-separated list of validator IDs. The specified validators will be contacted to get and authenticate the starting point (state summary) for state sync. An example setting of this field would be `--state-sync-ids="NodeID-7Xhw2mDxuDS44j42TCB6U5579esbSt3Lg,NodeID-MFrZFVCXPv5iCn6M9K6XduxGTYp891xXZ"`. The number of given IDs here must be same with number of given `--state-sync-ips`. The default value is empty, which results in all validators being sampled. |
| `--state-sync-ips` | `AVAGO_STATE_SYNC_IPS` | string | - | State sync IPs is a comma-separated list of IP:port pairs. These IP Addresses will be contacted to get and authenticate the starting point (state summary) for state sync. An example setting of this field would be `--state-sync-ips="127.0.0.1:12345,1.2.3.4:5678"`. The number of given IPs here must be the same with the number of given `--state-sync-ids`. |
### Staking
| Flag | Env Var | Type | Default | Description |
| --------------------------------- | ------------------------------------- | ------ | --------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--staking-port` | `AVAGO_STAKING_PORT` | int | `9651` | The port through which the network peers will connect to this node externally. Having this port accessible from the internet is required for correct node operation. |
| `--staking-tls-cert-file` | `AVAGO_STAKING_TLS_CERT_FILE` | string | `$HOME/.avalanchego/staking/staker.crt` | Avalanche uses two-way authenticated TLS connections to securely connect nodes. This argument specifies the location of the TLS certificate used by the node. This flag is ignored if `--staking-tls-cert-file-content` is specified. |
| `--staking-tls-cert-file-content` | `AVAGO_STAKING_TLS_CERT_FILE_CONTENT` | string | - | As an alternative to `--staking-tls-cert-file`, it allows specifying base64 encoded content of the TLS certificate used by the node. Note that full certificate content, with the leading and trailing header, must be base64 encoded. |
| `--staking-tls-key-file` | `AVAGO_STAKING_TLS_KEY_FILE` | string | `$HOME/.avalanchego/staking/staker.key` | Avalanche uses two-way authenticated TLS connections to securely connect nodes. This argument specifies the location of the TLS private key used by the node. This flag is ignored if `--staking-tls-key-file-content` is specified. |
| `--staking-tls-key-file-content` | `AVAGO_STAKING_TLS_KEY_FILE_CONTENT` | string | - | As an alternative to `--staking-tls-key-file`, it allows specifying base64 encoded content of the TLS private key used by the node. Note that full private key content, with the leading and trailing header, must be base64 encoded. |
### Subnets
#### Subnet Tracking
| Flag | Env Var | Type | Default | Description |
| ----------------- | --------------------- | ------ | ------- | -------------------------------------------------------------------------------------------------------------------------------------- |
| `--track-subnets` | `AVAGO_TRACK_SUBNETS` | string | - | Comma separated list of Subnet IDs that this node would track if added to. Defaults to empty (will only validate the Primary Network). |
#### Subnet Configs
It is possible to provide parameters for Subnets. Parameters here apply to all chains in the specified Subnets. Parameters must be specified with a `[subnetID].json` config file under `--subnet-config-dir`. AvalancheGo loads configs for Subnets specified in `--track-subnets` parameter. Full reference for all configuration options for a Subnet can be found in a separate [Subnet Configs](https://build.avax.network/docs/nodes/configure/avalanche-l1-configs) document.
| Flag | Env Var | Type | Default | Description |
| ------------------------- | ----------------------------- | ------ | ------------------------------------ | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--subnet-config-dir` | `AVAGO_SUBNET_CONFIG_DIR` | string | `$HOME/.avalanchego/configs/subnets` | Specifies the directory that contains Subnet configs, as described above. If the flag is set explicitly, the specified folder must exist, or AvalancheGo will exit with an error. This flag is ignored if `--subnet-config-content` is specified. Example: Let's say we have a Subnet with ID `p4jUwqZsA2LuSftroCd3zb4ytH8W99oXKuKVZdsty7eQ3rXD6`. We can create a config file under the default `subnet-config-dir` at `$HOME/.avalanchego/configs/subnets/p4jUwqZsA2LuSftroCd3zb4ytH8W99oXKuKVZdsty7eQ3rXD6.json`. An example config file is: `{"validatorOnly": false, "consensusParameters": {"k": 25, "alpha": 18}}`. By default, none of these directories and/or files exist. You would need to create them manually if needed. |
| `--subnet-config-content` | `AVAGO_SUBNET_CONFIG_CONTENT` | string | - | As an alternative to `--subnet-config-dir`, it allows specifying base64 encoded parameters for a Subnet. |
### Version
| Flag | Env Var | Type | Default | Description |
| ----------- | --------------- | ------- | ------- | ---------------------------------------------- |
| `--version` | `AVAGO_VERSION` | boolean | `false` | If this is `true`, print the version and quit. |
# Advanced Configuration Options
⚠️ **Warning**: The following options may affect the correctness of a node. Only power users should change these.
### Gossiping
Consensus gossiping parameters.
| Flag | Env Var | Type | Default | Description |
| --------------------------------------------------------- | ------------------------------------------------------------- | -------- | ------- | ----------------------------------------------------------------------- |
| `--consensus-accepted-frontier-gossip-validator-size` | `AVAGO_CONSENSUS_ACCEPTED_FRONTIER_GOSSIP_VALIDATOR_SIZE` | uint | `0` | Number of validators to gossip to when gossiping accepted frontier. |
| `--consensus-accepted-frontier-gossip-non-validator-size` | `AVAGO_CONSENSUS_ACCEPTED_FRONTIER_GOSSIP_NON_VALIDATOR_SIZE` | uint | `0` | Number of non-validators to gossip to when gossiping accepted frontier. |
| `--consensus-accepted-frontier-gossip-peer-size` | `AVAGO_CONSENSUS_ACCEPTED_FRONTIER_GOSSIP_PEER_SIZE` | uint | `15` | Number of peers to gossip to when gossiping accepted frontier. |
| `--consensus-accepted-frontier-gossip-frequency` | `AVAGO_CONSENSUS_ACCEPTED_FRONTIER_GOSSIP_FREQUENCY` | duration | `10s` | Time between gossiping accepted frontiers. |
| `--consensus-on-accept-gossip-validator-size` | `AVAGO_CONSENSUS_ON_ACCEPT_GOSSIP_VALIDATOR_SIZE` | uint | `0` | Number of validators to gossip to each accepted container to. |
| `--consensus-on-accept-gossip-non-validator-size` | `AVAGO_CONSENSUS_ON_ACCEPT_GOSSIP_NON_VALIDATOR_SIZE` | uint | `0` | Number of non-validators to gossip to each accepted container to. |
| `--consensus-on-accept-gossip-peer-size` | `AVAGO_CONSENSUS_ON_ACCEPT_GOSSIP_PEER_SIZE` | uint | `10` | Number of peers to gossip to each accepted container to. |
### Sybil Protection
Sybil protection configuration. These settings affect how the node participates in consensus.
| Flag | Env Var | Type | Default | Description |
| ------------------------------------ | ---------------------------------------- | ------- | ------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--sybil-protection-enabled` | `AVAGO_SYBIL_PROTECTION_ENABLED` | boolean | `true` | Avalanche uses Proof of Stake (PoS) as sybil resistance to make it prohibitively expensive to attack the network. If false, sybil resistance is disabled and all peers will be sampled during consensus. Note that this can not be disabled on public networks (`Fuji` and `Mainnet`). Setting this flag to `false` **does not** mean "this node is not a validator." It means that this node will sample all nodes, not just validators. **You should not set this flag to false unless you understand what you are doing.** |
| `--sybil-protection-disabled-weight` | `AVAGO_SYBIL_PROTECTION_DISABLED_WEIGHT` | uint | `100` | Weight to provide to each peer when staking is disabled. |
### Benchlist
Peer benchlisting configuration.
| Flag | Env Var | Type | Default | Description |
| ---------------------------------- | -------------------------------------- | -------- | ------- | --------------------------------------------------------------------------------------------------------- |
| `--benchlist-duration` | `AVAGO_BENCHLIST_DURATION` | duration | `15m` | Maximum amount of time a peer is benchlisted after surpassing `--benchlist-fail-threshold`. |
| `--benchlist-fail-threshold` | `AVAGO_BENCHLIST_FAIL_THRESHOLD` | int | `10` | Number of consecutive failed queries to a node before benching it (assuming all queries to it will fail). |
| `--benchlist-min-failing-duration` | `AVAGO_BENCHLIST_MIN_FAILING_DURATION` | duration | `150s` | Minimum amount of time queries to a peer must be failing before the peer is benched. |
### Consensus Parameters
:::note
Some of these parameters can only be set on a local or private network, not on Fuji Testnet or Mainnet
:::
| Flag | Env Var | Type | Default | Description |
| ------------------------------ | ---------------------------------- | -------- | ---------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--consensus-shutdown-timeout` | `AVAGO_CONSENSUS_SHUTDOWN_TIMEOUT` | duration | `5s` | Timeout before killing an unresponsive chain. |
| `--create-asset-tx-fee` | `AVAGO_CREATE_ASSET_TX_FEE` | int | `10000000` | Transaction fee, in nAVAX, for transactions that create new assets. This can only be changed on a local network. |
| `--tx-fee` | `AVAGO_TX_FEE` | int | `1000000` | The required amount of nAVAX to be burned for a transaction to be valid on the X-Chain, and for import/export transactions on the P-Chain. This parameter requires network agreement in its current form. Changing this value from the default should only be done on private networks or local network. |
| `--uptime-requirement` | `AVAGO_UPTIME_REQUIREMENT` | float | `0.8` | Fraction of time a validator must be online to receive rewards. This can only be changed on a local network. |
| `--uptime-metric-freq` | `AVAGO_UPTIME_METRIC_FREQ` | duration | `30s` | Frequency of renewing this node's average uptime metric. |
### Staking Parameters
Staking economics configuration.
| Flag | Env Var | Type | Default | Description |
| ------------------------------ | ---------------------------------- | -------- | -------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--min-validator-stake` | `AVAGO_MIN_VALIDATOR_STAKE` | int | network dependent | The minimum stake, in nAVAX, required to validate the Primary Network. This can only be changed on a local network. Defaults to `2000000000000` (2,000 AVAX) on Mainnet. Defaults to `5000000` (.005 AVAX) on Test Net. |
| `--max-validator-stake` | `AVAGO_MAX_VALIDATOR_STAKE` | int | network dependent | The maximum stake, in nAVAX, that can be placed on a validator on the primary network. This includes stake provided by both the validator and by delegators to the validator. This can only be changed on a local network. |
| `--min-delegator-stake` | `AVAGO_MIN_DELEGATOR_STAKE` | int | network dependent | The minimum stake, in nAVAX, that can be delegated to a validator of the Primary Network. Defaults to `25000000000` (25 AVAX) on Mainnet. Defaults to `5000000` (.005 AVAX) on Test Net. This can only be changed on a local network. |
| `--min-delegation-fee` | `AVAGO_MIN_DELEGATION_FEE` | int | `20000` | The minimum delegation fee that can be charged for delegation on the Primary Network, multiplied by \`10,000\`. Must be in the range \[0, 1000000]. This can only be changed on a local network. |
| `--min-stake-duration` | `AVAGO_MIN_STAKE_DURATION` | duration | `336h` | Minimum staking duration. This can only be changed on a local network. This applies to both delegation and validation periods. |
| `--max-stake-duration` | `AVAGO_MAX_STAKE_DURATION` | duration | `8760h` | The maximum staking duration, in hours. This can only be changed on a local network. |
| `--stake-minting-period` | `AVAGO_STAKE_MINTING_PERIOD` | duration | `8760h` | Consumption period of the staking function, in hours. This can only be changed on a local network. |
| `--stake-max-consumption-rate` | `AVAGO_STAKE_MAX_CONSUMPTION_RATE` | uint | `120000` | The maximum percentage of the consumption rate for the remaining token supply in the minting period, which is 1 year on Mainnet. This can only be changed on a local network. |
| `--stake-min-consumption-rate` | `AVAGO_STAKE_MIN_CONSUMPTION_RATE` | uint | `100000` | The minimum percentage of the consumption rate for the remaining token supply in the minting period, which is 1 year on Mainnet. This can only be changed on a local network. |
| `--stake-supply-cap` | `AVAGO_STAKE_SUPPLY_CAP` | uint | `720000000000000000` | The maximum stake supply, in nAVAX, that can be placed on a validator. This can only be changed on a local network. |
### Snow Consensus
Snow consensus protocol parameters.
| Flag | Env Var | Type | Default | Description |
| ---------------------------- | -------------------------------- | -------- | ------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--snow-concurrent-repolls` | `AVAGO_SNOW_CONCURRENT_REPOLLS` | int | `4` | Snow consensus requires repolling transactions that are issued during low time of network usage. This parameter lets one define how aggressive the client will be in finalizing these pending transactions. This should only be changed after careful consideration of the tradeoffs of Snow consensus. The value must be at least `1` and at most `--snow-commit-threshold`. |
| `--snow-sample-size` | `AVAGO_SNOW_SAMPLE_SIZE` | int | `20` | Snow consensus defines `k` as the number of validators that are sampled during each network poll. This parameter lets one define the `k` value used for consensus. This should only be changed after careful consideration of the tradeoffs of Snow consensus. The value must be at least `1`. |
| `--snow-quorum-size` | `AVAGO_SNOW_QUORUM_SIZE` | int | `15` | Snow consensus defines `alpha` as the number of validators that must prefer a transaction during each network poll to increase the confidence in the transaction. This parameter lets us define the `alpha` value used for consensus. This should only be changed after careful consideration of the tradeoffs of Snow consensus. The value must be at greater than `k/2`. |
| `--snow-commit-threshold` | `AVAGO_SNOW_COMMIT_THRESHOLD` | int | `20` | Snow consensus defines `beta` as the number of consecutive polls that a container must increase its confidence for it to be accepted. This parameter lets us define the `beta` value used for consensus. This should only be changed after careful consideration of the tradeoffs of Snow consensus. The value must be at least `1`. |
| `--snow-optimal-processing` | `AVAGO_SNOW_OPTIMAL_PROCESSING` | int | `50` | Optimal number of processing items in consensus. The value must be at least `1`. |
| `--snow-max-processing` | `AVAGO_SNOW_MAX_PROCESSING` | int | `1024` | Maximum number of processing items to be considered healthy. Reports unhealthy if more than this number of items are outstanding. The value must be at least `1`. |
| `--snow-max-time-processing` | `AVAGO_SNOW_MAX_TIME_PROCESSING` | duration | `2m` | Maximum amount of time an item should be processing and still be healthy. Reports unhealthy if there is an item processing for longer than this duration. The value must be greater than `0`. |
### ProposerVM
ProposerVM configuration.
| Flag | Env Var | Type | Default | Description |
| --------------------------------- | ------------------------------------- | -------- | ------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| `--proposervm-use-current-height` | `AVAGO_PROPOSERVM_USE_CURRENT_HEIGHT` | boolean | `false` | Have the ProposerVM always report the last accepted P-chain block height. |
| `--proposervm-min-block-delay` | `AVAGO_PROPOSERVM_MIN_BLOCK_DELAY` | duration | `1s` | The minimum delay to enforce when building a snowman++ block for the primary network chains and the default minimum delay for subnets. A non-default value is only suggested for non-production nodes. |
### Health Checks
Health monitoring configuration.
| Flag | Env Var | Type | Default | Description |
| ---------------------------------- | -------------------------------------- | -------- | ------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--health-check-frequency` | `AVAGO_HEALTH_CHECK_FREQUENCY` | duration | `30s` | Health check runs with this frequency. |
| `--health-check-averager-halflife` | `AVAGO_HEALTH_CHECK_AVERAGER_HALFLIFE` | duration | `10s` | Half life of averagers used in health checks (to measure the rate of message failures, for example.) Larger value -> less volatile calculation of averages. |
### Network Configuration
Advanced network settings.
| Flag | Env Var | Type | Default | Description |
| --------------------------------------------------- | ------------------------------------------------------- | -------- | ------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--network-allow-private-ips` | `AVAGO_NETWORK_ALLOW_PRIVATE_IPS` | boolean | `true` | Allows the node to connect peers with private IPs. |
| `--network-compression-type` | `AVAGO_NETWORK_COMPRESSION_TYPE` | string | `gzip` | The type of compression to use when sending messages to peers. Must be one of \`gzip\`, \`zstd\`, \`none\`. Nodes can handle inbound \`gzip\` compressed messages but by default send \`zstd\` compressed messages. |
| `--network-initial-timeout` | `AVAGO_NETWORK_INITIAL_TIMEOUT` | duration | `5s` | Initial timeout value of the adaptive timeout manager. |
| `--network-initial-reconnect-delay` | `AVAGO_NETWORK_INITIAL_RECONNECT_DELAY` | duration | `1s` | Initial delay duration must be waited before attempting to reconnect a peer. |
| `--network-max-reconnect-delay` | `AVAGO_NETWORK_MAX_RECONNECT_DELAY` | duration | `1h` | Maximum delay duration must be waited before attempting to reconnect a peer. |
| `--network-minimum-timeout` | `AVAGO_NETWORK_MINIMUM_TIMEOUT` | duration | `2s` | Minimum timeout value of the adaptive timeout manager. |
| `--network-maximum-timeout` | `AVAGO_NETWORK_MAXIMUM_TIMEOUT` | duration | `10s` | Maximum timeout value of the adaptive timeout manager. |
| `--network-maximum-inbound-timeout` | `AVAGO_NETWORK_MAXIMUM_INBOUND_TIMEOUT` | duration | `10s` | Maximum timeout value of an inbound message. Defines duration within which an incoming message must be fulfilled. Incoming messages containing deadline higher than this value will be overridden with this value. |
| `--network-timeout-halflife` | `AVAGO_NETWORK_TIMEOUT_HALFLIFE` | duration | `5m` | Half life used when calculating average network latency. Larger value -> less volatile network latency calculation. |
| `--network-timeout-coefficient` | `AVAGO_NETWORK_TIMEOUT_COEFFICIENT` | float | `2` | Requests to peers will time out after \[network-timeout-coefficient] \* \[average request latency]. |
| `--network-read-handshake-timeout` | `AVAGO_NETWORK_READ_HANDSHAKE_TIMEOUT` | duration | `15s` | Timeout value for reading handshake messages. |
| `--network-ping-timeout` | `AVAGO_NETWORK_PING_TIMEOUT` | duration | `30s` | Timeout value for Ping-Pong with a peer. |
| `--network-ping-frequency` | `AVAGO_NETWORK_PING_FREQUENCY` | duration | `22.5s` | Frequency of pinging other peers. |
| `--network-health-min-conn-peers` | `AVAGO_NETWORK_HEALTH_MIN_CONN_PEERS` | uint | `1` | Node will report unhealthy if connected to less than this many peers. |
| `--network-health-max-time-since-msg-received` | `AVAGO_NETWORK_HEALTH_MAX_TIME_SINCE_MSG_RECEIVED` | duration | `1m` | Node will report unhealthy if it hasn't received a message for this amount of time. |
| `--network-health-max-time-since-msg-sent` | `AVAGO_NETWORK_HEALTH_MAX_TIME_SINCE_MSG_SENT` | duration | `1m` | Network layer returns unhealthy if haven't sent a message for at least this much time. |
| `--network-health-max-portion-send-queue-full` | `AVAGO_NETWORK_HEALTH_MAX_PORTION_SEND_QUEUE_FULL` | float | `0.9` | Node will report unhealthy if its send queue is more than this portion full. Must be in \[0,1]. |
| `--network-health-max-send-fail-rate` | `AVAGO_NETWORK_HEALTH_MAX_SEND_FAIL_RATE` | float | `0.25` | Node will report unhealthy if more than this portion of message sends fail. Must be in \[0,1]. |
| `--network-health-max-outstanding-request-duration` | `AVAGO_NETWORK_HEALTH_MAX_OUTSTANDING_REQUEST_DURATION` | duration | `5m` | Node reports unhealthy if there has been a request outstanding for this duration. |
| `--network-max-clock-difference` | `AVAGO_NETWORK_MAX_CLOCK_DIFFERENCE` | duration | `1m` | Max allowed clock difference value between this node and peers. |
| `--network-require-validator-to-connect` | `AVAGO_NETWORK_REQUIRE_VALIDATOR_TO_CONNECT` | boolean | `false` | If true, this node will only maintain a connection with another node if this node is a validator, the other node is a validator, or the other node is a beacon. |
| `--network-tcp-proxy-enabled` | `AVAGO_NETWORK_TCP_PROXY_ENABLED` | boolean | `false` | Require all P2P connections to be initiated with a TCP proxy header. |
| `--network-tcp-proxy-read-timeout` | `AVAGO_NETWORK_TCP_PROXY_READ_TIMEOUT` | duration | `3s` | Maximum duration to wait for a TCP proxy header. |
| `--network-outbound-connection-timeout` | `AVAGO_NETWORK_OUTBOUND_CONNECTION_TIMEOUT` | duration | `30s` | Timeout while dialing a peer. |
### Message Rate-Limiting
These flags govern rate-limiting of inbound and outbound messages. For more information on rate-limiting and the flags below, see package `throttling` in AvalancheGo.
#### CPU Based Rate-Limiting
Rate-limiting based on how much CPU usage a peer causes.
| Flag | Env Var | Type | Default | Description |
| ------------------------------------------------------- | ----------------------------------------------------------- | -------- | ------------ | ------------------------------------------------------------------------------------------------------------------------------- |
| `--throttler-inbound-cpu-validator-alloc` | `AVAGO_THROTTLER_INBOUND_CPU_VALIDATOR_ALLOC` | float | half of CPUs | Number of CPU allocated for use by validators. Value should be in range (0, total core count]. |
| `--throttler-inbound-cpu-max-recheck-delay` | `AVAGO_THROTTLER_INBOUND_CPU_MAX_RECHECK_DELAY` | duration | `5s` | In the CPU rate-limiter, check at least this often whether the node's CPU usage has fallen to an acceptable level. |
| `--throttler-inbound-disk-max-recheck-delay` | `AVAGO_THROTTLER_INBOUND_DISK_MAX_RECHECK_DELAY` | duration | `5s` | In the disk-based network throttler, check at least this often whether the node's disk usage has fallen to an acceptable level. |
| `--throttler-inbound-cpu-max-non-validator-usage` | `AVAGO_THROTTLER_INBOUND_CPU_MAX_NON_VALIDATOR_USAGE` | float | 80% of CPUs | Number of CPUs that if fully utilized, will rate limit all non-validators. Value should be in range \[0, total core count]. |
| `--throttler-inbound-cpu-max-non-validator-node-usage` | `AVAGO_THROTTLER_INBOUND_CPU_MAX_NON_VALIDATOR_NODE_USAGE` | float | CPUs / 8 | Maximum number of CPUs that a non-validator can utilize. Value should be in range \[0, total core count]. |
| `--throttler-inbound-disk-validator-alloc` | `AVAGO_THROTTLER_INBOUND_DISK_VALIDATOR_ALLOC` | float | `1000 GiB/s` | Maximum number of disk reads/writes per second to allocate for use by validators. Must be > 0. |
| `--throttler-inbound-disk-max-non-validator-usage` | `AVAGO_THROTTLER_INBOUND_DISK_MAX_NON_VALIDATOR_USAGE` | float | `1000 GiB/s` | Number of disk reads/writes per second that, if fully utilized, will rate limit all non-validators. Must be >= 0. |
| `--throttler-inbound-disk-max-non-validator-node-usage` | `AVAGO_THROTTLER_INBOUND_DISK_MAX_NON_VALIDATOR_NODE_USAGE` | float | `1000 GiB/s` | Maximum number of disk reads/writes per second that a non-validator can utilize. Must be >= 0. |
#### Bandwidth Based Rate-Limiting
Rate-limiting based on the bandwidth a peer uses.
| Flag | Env Var | Type | Default | Description |
| ---------------------------------------------- | -------------------------------------------------- | ---- | ------- | ------------------------------------------------------------------------------------------------------------------ |
| `--throttler-inbound-bandwidth-refill-rate` | `AVAGO_THROTTLER_INBOUND_BANDWIDTH_REFILL_RATE` | uint | `512` | Max average inbound bandwidth usage of a peer, in bytes per second. See interface `throttling.BandwidthThrottler`. |
| `--throttler-inbound-bandwidth-max-burst-size` | `AVAGO_THROTTLER_INBOUND_BANDWIDTH_MAX_BURST_SIZE` | uint | `2 MiB` | Max inbound bandwidth a node can use at once. See interface `throttling.BandwidthThrottler`. |
#### Message Size Based Rate-Limiting
Rate-limiting based on the total size, in bytes, of unprocessed messages.
| Flag | Env Var | Type | Default | Description |
| --------------------------------------------- | ------------------------------------------------- | ---- | -------- | ------------------------------------------------------------------------------------------------------ |
| `--throttler-inbound-at-large-alloc-size` | `AVAGO_THROTTLER_INBOUND_AT_LARGE_ALLOC_SIZE` | uint | `6 MiB` | Size, in bytes, of at-large allocation in the inbound message throttler. |
| `--throttler-inbound-validator-alloc-size` | `AVAGO_THROTTLER_INBOUND_VALIDATOR_ALLOC_SIZE` | uint | `32 MiB` | Size, in bytes, of validator allocation in the inbound message throttler. |
| `--throttler-inbound-node-max-at-large-bytes` | `AVAGO_THROTTLER_INBOUND_NODE_MAX_AT_LARGE_BYTES` | uint | `2 MiB` | Maximum number of bytes a node can take from the at-large allocation of the inbound message throttler. |
#### Message Based Rate-Limiting
Rate-limiting based on the number of unprocessed messages.
| Flag | Env Var | Type | Default | Description |
| ---------------------------------------------- | -------------------------------------------------- | ---- | ------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--throttler-inbound-node-max-processing-msgs` | `AVAGO_THROTTLER_INBOUND_NODE_MAX_PROCESSING_MSGS` | uint | `1024` | Node will stop reading messages from a peer when it is processing this many messages from the peer. Will resume reading messages from the peer when it is processing less than this many messages. |
#### Outbound Rate-Limiting
Rate-limiting for outbound messages.
| Flag | Env Var | Type | Default | Description |
| ---------------------------------------------- | -------------------------------------------------- | ---- | -------- | ------------------------------------------------------------------------------------------------------- |
| `--throttler-outbound-at-large-alloc-size` | `AVAGO_THROTTLER_OUTBOUND_AT_LARGE_ALLOC_SIZE` | uint | `32 MiB` | Size, in bytes, of at-large allocation in the outbound message throttler. |
| `--throttler-outbound-validator-alloc-size` | `AVAGO_THROTTLER_OUTBOUND_VALIDATOR_ALLOC_SIZE` | uint | `32 MiB` | Size, in bytes, of validator allocation in the outbound message throttler. |
| `--throttler-outbound-node-max-at-large-bytes` | `AVAGO_THROTTLER_OUTBOUND_NODE_MAX_AT_LARGE_BYTES` | uint | `2 MiB` | Maximum number of bytes a node can take from the at-large allocation of the outbound message throttler. |
### Connection Rate-Limiting
| Flag | Env Var | Type | Default | Description |
| ----------------------------------------------------------- | --------------------------------------------------------------- | -------- | ------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--network-inbound-connection-throttling-cooldown` | `AVAGO_NETWORK_INBOUND_CONNECTION_THROTTLING_COOLDOWN` | duration | `10s` | Node will upgrade an inbound connection from a given IP at most once within this duration. If 0 or negative, will not consider recency of last upgrade when deciding whether to upgrade. |
| `--network-inbound-connection-throttling-max-conns-per-sec` | `AVAGO_NETWORK_INBOUND_CONNECTION_THROTTLING_MAX_CONNS_PER_SEC` | uint | `512` | Node will accept at most this many inbound connections per second. |
| `--network-outbound-connection-throttling-rps` | `AVAGO_NETWORK_OUTBOUND_CONNECTION_THROTTLING_RPS` | uint | `50` | Node makes at most this many outgoing peer connection attempts per second. |
### Peer List Gossiping
Nodes gossip peers to each other so that each node can have an up-to-date peer list. A node gossips `--network-peer-list-num-validator-ips` validator IPs to `--network-peer-list-validator-gossip-size` validators, `--network-peer-list-non-validator-gossip-size` non-validators and `--network-peer-list-peers-gossip-size` peers every `--network-peer-list-gossip-frequency`.
| Flag | Env Var | Type | Default | Description |
| ----------------------------------------------- | --------------------------------------------------- | -------- | ------- | ---------------------------------------------------------------------------------------------------- |
| `--network-peer-list-num-validator-ips` | `AVAGO_NETWORK_PEER_LIST_NUM_VALIDATOR_IPS` | int | `15` | Number of validator IPs to gossip to other nodes. |
| `--network-peer-list-validator-gossip-size` | `AVAGO_NETWORK_PEER_LIST_VALIDATOR_GOSSIP_SIZE` | int | `20` | Number of validators that the node will gossip peer list to. |
| `--network-peer-list-non-validator-gossip-size` | `AVAGO_NETWORK_PEER_LIST_NON_VALIDATOR_GOSSIP_SIZE` | int | `0` | Number of non-validators that the node will gossip peer list to. |
| `--network-peer-list-peers-gossip-size` | `AVAGO_NETWORK_PEER_LIST_PEERS_GOSSIP_SIZE` | int | `0` | Number of total peers (including non-validator or validator) that the node will gossip peer list to. |
| `--network-peer-list-gossip-frequency` | `AVAGO_NETWORK_PEER_LIST_GOSSIP_FREQUENCY` | duration | `1m` | Frequency to gossip peers to other nodes. |
| `--network-peer-read-buffer-size` | `AVAGO_NETWORK_PEER_READ_BUFFER_SIZE` | int | `8 KiB` | Size of the buffer that peer messages are read into (there is one buffer per peer). |
| `--network-peer-write-buffer-size` | `AVAGO_NETWORK_PEER_WRITE_BUFFER_SIZE` | int | `8 KiB` | Size of the buffer that peer messages are written into (there is one buffer per peer). |
### Resource Usage Tracking
| Flag | Env Var | Type | Default | Description |
| --------------------------------------------------------- | ------------------------------------------------------------- | -------- | ------------ | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--meter-vms-enabled` | `AVAGO_METER_VMS_ENABLED` | boolean | `true` | Enable Meter VMs to track VM performance with more granularity. |
| `--system-tracker-frequency` | `AVAGO_SYSTEM_TRACKER_FREQUENCY` | duration | `500ms` | Frequency to check the real system usage of tracked processes. More frequent checks -> usage metrics are more accurate, but more expensive to track. |
| `--system-tracker-processing-halflife` | `AVAGO_SYSTEM_TRACKER_PROCESSING_HALFLIFE` | duration | `15s` | Half life to use for the processing requests tracker. Larger half life -> usage metrics change more slowly. |
| `--system-tracker-cpu-halflife` | `AVAGO_SYSTEM_TRACKER_CPU_HALFLIFE` | duration | `15s` | Half life to use for the CPU tracker. Larger half life -> CPU usage metrics change more slowly. |
| `--system-tracker-disk-halflife` | `AVAGO_SYSTEM_TRACKER_DISK_HALFLIFE` | duration | `1m` | Half life to use for the disk tracker. Larger half life -> disk usage metrics change more slowly. |
| `--system-tracker-disk-required-available-space` | `AVAGO_SYSTEM_TRACKER_DISK_REQUIRED_AVAILABLE_SPACE` | uint | `536870912` | Minimum number of available bytes on disk, under which the node will shutdown. |
| `--system-tracker-disk-warning-threshold-available-space` | `AVAGO_SYSTEM_TRACKER_DISK_WARNING_THRESHOLD_AVAILABLE_SPACE` | uint | `1073741824` | Warning threshold for the number of available bytes on disk, under which the node will be considered unhealthy. Must be >= `--system-tracker-disk-required-available-space`. |
### Plugins
| Flag | Env Var | Type | Default | Description |
| -------------- | ------------------ | ------ | ---------------------------- | -------------------------------------------------------------------------------------- |
| `--plugin-dir` | `AVAGO_PLUGIN_DIR` | string | `$HOME/.avalanchego/plugins` | Sets the directory for [VM plugins](https://build.avax.network/docs/virtual-machines). |
### Virtual Machine (VM) Configs
| Flag | Env Var | Type | Default | Description |
| --------------------------- | ------------------------------- | ------ | ----------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| `--vm-aliases-file` | `AVAGO_VM_ALIASES_FILE` | string | `~/.avalanchego/configs/vms/aliases.json` | Path to JSON file that defines aliases for Virtual Machine IDs. This flag is ignored if `--vm-aliases-file-content` is specified. Example content: `{"tGas3T58KzdjLHhBDMnH2TvrddhqTji5iZAMZ3RXs2NLpSnhH": ["timestampvm", "timerpc"]}`. The above example aliases the VM whose ID is `"tGas3T58KzdjLHhBDMnH2TvrddhqTji5iZAMZ3RXs2NLpSnhH"` to `"timestampvm"` and `"timerpc"`. |
| `--vm-aliases-file-content` | `AVAGO_VM_ALIASES_FILE_CONTENT` | string | - | As an alternative to `--vm-aliases-file`, it allows specifying base64 encoded aliases for Virtual Machine IDs. |
### Indexing
| Flag | Env Var | Type | Default | Description |
| -------------------------- | ------------------------------ | ------- | ------- | --------------------------------------------------------------------------------------------------------------------------- |
| `--index-allow-incomplete` | `AVAGO_INDEX_ALLOW_INCOMPLETE` | boolean | `false` | If true, allow running the node in such a way that could cause an index to miss transactions. Ignored if index is disabled. |
### Router
| Flag | Env Var | Type | Default | Description |
| ------------------------------------------ | ---------------------------------------------- | ----- | ------- | ------------------------------------------------------------------------------------------------------------------------------ |
| `--router-health-max-drop-rate` | `AVAGO_ROUTER_HEALTH_MAX_DROP_RATE` | float | `1` | Node reports unhealthy if the router drops more than this portion of messages. |
| `--router-health-max-outstanding-requests` | `AVAGO_ROUTER_HEALTH_MAX_OUTSTANDING_REQUESTS` | uint | `1024` | Node reports unhealthy if there are more than this many outstanding consensus requests (Get, PullQuery, etc.) over all chains. |
## Additional Resources
* [Full documentation](https://build.avax.network/docs/quick-start)
* [Example configurations](https://github.com/ava-labs/avalanchego/tree/master/config)
* [Network upgrade schedules](https://build.avax.network/docs/quick-start/primary-network)
# Backup and Restore
URL: /docs/nodes/maintain/backup-restore
Once you have your node up and running, it's time to prepare for disaster recovery. Should your machine ever have a catastrophic failure due to either hardware or software issues, or even a case of natural disaster, it's best to be prepared for such a situation by making a backup.
When running, a complete node installation along with the database can grow to be multiple gigabytes in size. Having to back up and restore such a large volume of data can be expensive, complicated and time-consuming. Luckily, there is a better way.
Instead of having to back up and restore everything, we need to back up only what is essential, that is, those files that cannot be reconstructed because they are unique to your node. For AvalancheGo node, unique files are those that identify your node on the network, in other words, files that define your NodeID.
Even if your node is a validator on the network and has multiple delegations on it, you don't need to worry about backing up anything else, because the validation and delegation transactions are also stored on the blockchain and will be restored during bootstrapping, along with the rest of the blockchain data.
The installation itself can be easily recreated by installing the node on a new machine, and all the remaining gigabytes of blockchain data can be easily recreated by the process of bootstrapping, which copies the data over from other network peers. However, if you would like to speed up the process, see the [Database Backup and Restore section](#database)
## NodeID[](#nodeid "Direct link to heading")
If more than one running nodes share the same NodeID, the communications from other nodes in the Avalanche network to this NodeID will be random to one of these nodes. If this NodeID is of a validator, it will dramatically impact the uptime calculation of the validator which will very likely disqualify the validator from receiving the staking rewards. Please make sure only one node with the same NodeID run at one time.
NodeID is a unique identifier that differentiates your node from all the other peers on the network. It's a string formatted like `NodeID-5mb46qkSBj81k9g9e4VFjGGSbaaSLFRzD`. You can look up the technical background of how the NodeID is constructed [here](/docs/api-reference/standards/cryptographic-primitives#tls-addresses). In essence, NodeID is defined by two files:
* `staker.crt`
* `staker.key`
NodePOP is this node's BLS key and proof of possession. Nodes must register a BLS key to act as a validator on the Primary Network. Your node's POP is logged on startup and is accessible over this endpoint.
* `publicKey` is the 48 byte hex representation of the BLS key.
* `proofOfPossession` is the 96 byte hex representation of the BLS signature.
NodePOP is defined by the `signer.key` file.
In the default installation, they can be found in the working directory, specifically in `~/.avalanchego/staking/`. All we need to do to recreate the node on another machine is to run a new installation with those same three files.
If `staker.key` and `staker.crt` are removed from a node, which is restarted afterwards, they will be recreated and a new node ID will be assigned.
If the `signer.key` is regenerated, the node will lose its previous BLS identity, which includes its public key and proof of possession. This change means that the node's former identity on the network will no longer be recognized, affecting its ability to participate in the consensus mechanism as before. Consequently, the node may lose its established reputation and any associated staking rewards.
If you have users defined in the keystore of your node, then you need to back up and restore those as well. [Keystore API](/docs/api-reference/keystore-api) has methods that can be used to export and import user keys. Note that Keystore API is used by developers only and not intended for use in production nodes. If you don't know what a keystore API is and have not used it, you don't need to worry about it.
### Backup[](#backup "Direct link to heading")
To back up your node, we need to store `staker.crt` and `staker.key` files somewhere safe and private, preferably to a different computer, to your private To back up your node, we need to store `staker.crt`, `staker.key` and `signer.key` files somewhere safe and private, preferably to a different computer.
If someone gets a hold of your staker files, they still cannot get to your funds, as they are controlled by the wallet private keys, not by the node. But, they could re-create your node somewhere else, and depending on the circumstances make you lose the staking rewards. So make sure your staker files are secure.
If someone gains access to your `signer.key`, they could potentially sign transactions on behalf of your node, which might disrupt the operations and integrity of your node on the network.
Let's get the files off the machine running the node.
#### From Local Node[](#from-local-node "Direct link to heading")
If you're running the node locally, on your desktop computer, just navigate to where the files are and copy them somewhere safe.
On a default Linux installation, the path to them will be `/home/USERNAME/.avalanchego/staking/`, where `USERNAME` needs to be replaced with the actual username running the node. Select and copy the files from there to a backup location. You don't need to stop the node to do that.
#### From Remote Node Using `scp`[](#from-remote-node-using-scp "Direct link to heading")
`scp` is a 'secure copy' command line program, available built-in on Linux and MacOS computers. There is also a Windows version, `pscp`, as part of the [PuTTY](https://www.chiark.greenend.org.uk/~sgtatham/putty/latest.html) package. If using `pscp`, in the following commands replace each usage of `scp` with `pscp -scp`.
To copy the files from the node, you will need to be able to remotely log into the machine. You can use account password, but the secure and recommended way is to use the SSH keys. The procedure for acquiring and setting up SSH keys is highly dependent on your cloud provider and machine configuration. You can refer to our [Amazon Web Services](/docs/nodes/on-third-party-services/amazon-web-services) and [Microsoft Azure](/docs/nodes/on-third-party-services/microsoft-azure) setup guides for those providers. Other providers will have similar procedures.
When you have means of remote login into the machine, you can copy the files over with the following command:
```bash
scp -r ubuntu@PUBLICIP:/home/ubuntu/.avalanchego/staking ~/avalanche_backup
```
This assumes the username on the machine is `ubuntu`, replace with correct username in both places if it is different. Also, replace `PUBLICIP` with the actual public IP of the machine. If `scp` doesn't automatically use your downloaded SSH key, you can point to it manually:
```bash
scp -i /path/to/the/key.pem -r ubuntu@PUBLICIP:/home/ubuntu/.avalanchego/staking ~/avalanche_backup
```
Once executed, this command will create `avalanche_backup` directory and place those three files in it. You need to store them somewhere safe.
### Restore[](#restore "Direct link to heading")
To restore your node from a backup, we need to do the reverse: restore `staker.key`, `staker.crt` and `signer.key` from the backup to the working directory of the new node.
First, we need to do the usual [installation](/docs/nodes/using-install-script/installing-avalanche-go) of the node. This will create a new NodeID, a new BLS key and a new BLS signature, which we need to replace. When the node is installed correctly, log into the machine where the node is running and stop it:
```bash
sudo systemctl stop avalanchego
```
We're ready to restore the node.
#### To Local Node[](#to-local-node "Direct link to heading")
If you're running the node locally, just copy the `staker.key`, `staker.crt` and `signer.key` files from the backup location into the working directory, which on the default Linux installation will be `/home/USERNAME/.avalanchego/staking/`. Replace `USERNAME` with the actual username used to run the node.
#### To Remote Node Using `scp`[](#to-remote-node-using-scp "Direct link to heading")
Again, the process is just the reverse operation. Using `scp` we need to copy the `staker.key`, `staker.crt` and `signer.key` files from the backup location into the remote working directory. Assuming the backed up files are located in the directory where the above backup procedure placed them:
```bash
scp ~/avalanche_backup/{staker.*,signer.key} ubuntu@PUBLICIP:/home/ubuntu/.avalanchego/staking
```
Or if you need to specify the path to the SSH key:
```bash
scp -i /path/to/the/key.pem ~/avalanche_backup/{staker.*,signer.key} ubuntu@PUBLICIP:/home/ubuntu/.avalanchego/staking
```
And again, replace `ubuntu` with correct username if different, and `PUBLICIP` with the actual public IP of the machine running the node, as well as the path to the SSH key if used.
#### Restart the Node and Verify[](#restart-the-node-and-verify "Direct link to heading")
Once the files have been replaced, log into the machine and start the node using:
```bash
sudo systemctl start avalanchego
```
You can now check that the node is restored with the correct NodeID and NodePOP by issuing the [getNodeID](/docs/api-reference/info-api#infogetnodeid) API call in the same console you ran the previous command:
```bash
curl -X POST --data '{
"jsonrpc":"2.0",
"id" :1,
"method" :"info.getNodeID"
}' -H 'content-type:application/json;' 127.0.0.1:9650/ext/info
```
You should see your original NodeID and NodePOP (BLS key and BLS signature). Restore process is done.
## Database[](#database "Direct link to heading")
Normally, when starting a new node, you can just bootstrap from scratch. However, there are situations when you may prefer to reuse an existing database (ex: preserve keystore records, reduce sync time).
This tutorial will walk you through compressing your node's DB and moving it to another computer using `zip` and `scp`.
### Database Backup[](#database-backup "Direct link to heading")
First, make sure to stop AvalancheGo, run:
```bash
sudo systemctl stop avalanchego
```
You must stop the Avalanche node before you back up the database otherwise data could become corrupted.
Once the node is stopped, you can `zip` the database directory to reduce the size of the backup and speed up the transfer using `scp`:
```bash
zip -r avalanche_db_backup.zip .avalanchego/db
```
*Note: It may take > 30 minutes to zip the node's DB.*
Next, you can transfer the backup to another machine:
```bash
scp -r ubuntu@PUBLICIP:/home/ubuntu/avalanche_db_backup.zip ~/avalanche_db_backup.zip
```
This assumes the username on the machine is `ubuntu`, replace with correct username in both places if it is different. Also, replace `PUBLICIP` with the actual public IP of the machine. If `scp` doesn't automatically use your downloaded SSH key, you can point to it manually:
```bash
scp -i /path/to/the/key.pem -r ubuntu@PUBLICIP:/home/ubuntu/avalanche_db_backup.zip ~/avalanche_db_backup.zip
```
Once executed, this command will create `avalanche_db_backup.zip` directory in you home directory.
### Database Restore[](#database-restore "Direct link to heading")
*This tutorial assumes you have already completed "Database Backup" and have a backup at \~/avalanche\_db\_backup.zip.*
First, we need to do the usual [installation](/docs/nodes/using-install-script/installing-avalanche-go) of the node. When the node is installed correctly, log into the machine where the node is running and stop it:
```bash
sudo systemctl stop avalanchego
```
You must stop the Avalanche node before you restore the database otherwise data could become corrupted.
We're ready to restore the database. First, let's move the DB on the existing node (you can remove this old DB later if the restore was successful):
```bash
mv .avalanchego/db .avalanchego/db-old
```
Next, we'll unzip the backup we moved from another node (this will place the unzipped files in `~/.avalanchego/db` when the command is run in the home directory):
```bash
unzip avalanche_db_backup.zip
```
After the database has been restored on a new node, use this command to start the node:
```bash
sudo systemctl start avalanchego
```
Node should now be running from the database on the new instance. To check that everything is in order and that node is not bootstrapping from scratch (which would indicate a problem), use:
```bash
sudo journalctl -u avalanchego -f
```
The node should be catching up to the network and fetching a small number of blocks before resuming normal operation (all the ones produced from the time when the node was stopped before the backup).
Once the backup has been restored and is working as expected, the zip can be deleted:
```bash
rm avalanche_db_backup.zip
```
### Database Direct Copy[](#database-direct-copy "Direct link to heading")
You may be in a situation where you don't have enough disk space to create the archive containing the whole database, so you cannot complete the backup process as described previously.
In that case, you can still migrate your database to a new computer, by using a different approach: `direct copy`. Instead of creating the archive, moving the archive and unpacking it, we can do all of that on the fly.
To do so, you will need `ssh` access from the destination machine (where you want the database to end up) to the source machine (where the database currently is). Setting up `ssh` is the same as explained for `scp` earlier in the document.
Same as shown previously, you need to stop the node (on both machines):
```bash
sudo systemctl stop avalanchego
```
You must stop the Avalanche node before you back up the database otherwise data could become corrupted.
Then, on the destination machine, change to a directory where you would like to the put the database files, enter the following command:
```bash
ssh -i /path/to/the/key.pem ubuntu@PUBLICIP 'tar czf - .avalanchego/db' | tar xvzf - -C .
```
Make sure to replace the correct path to the key, and correct IP of the source machine. This will compress the database, but instead of writing it to a file it will pipe it over `ssh` directly to destination machine, where it will be decompressed and written to disk. The process can take a long time, make sure it completes before continuing.
After copying is done, all you need to do now is move the database to the correct location on the destination machine. Assuming there is a default AvalancheGo node installation, we remove the old database and replace it with the new one:
```bash
rm -rf ~/.avalanchego/db
mv db ~/.avalanchego/db
```
You can now start the node on the destination machine:
```bash
sudo systemctl start avalanchego
```
Node should now be running from the copied database. To check that everything is in order and that node is not bootstrapping from scratch (which would indicate a problem), use:
```bash
sudo journalctl -u avalanchego -f
```
The node should be catching up to the network and fetching a small number of blocks before resuming normal operation (all the ones produced from the time when the node was stopped before the backup).
## Summary[](#summary "Direct link to heading")
Essential part of securing your node is the backup that enables full and painless restoration of your node. Following this tutorial you can rest easy knowing that should you ever find yourself in a situation where you need to restore your node from scratch, you can easily and quickly do so.
If you have any problems following this tutorial, comments you want to share with us or just want to chat, you can reach us on our [Discord](https://chat.avalabs.org/) server.
# Node Bootstrap
URL: /docs/nodes/maintain/bootstrapping
Node Bootstrap is the process where a node *securely* downloads linear chain blocks to recreate the latest state of the chain locally.
Bootstrap must guarantee that the local state of a node is in sync with the state of other valid nodes. Once bootstrap is completed, a node has the latest state of the chain and can verify new incoming transactions and reach consensus with other nodes, collectively moving forward the chains.
Bootstrapping a node is a multi-step process which requires downloading the chains required by the Primary Network (that is, the C-Chain, P-Chain, and X-Chain), as well as the chains required by any additional Avalanche L1s that the node explicitly tracks.
This document covers the high-level technical details of how bootstrapping works. This document glosses over some specifics, but the [AvalancheGo](https://github.com/ava-labs/avalanchego) codebase is open-source and is available for curious-minded readers to learn more.
## Validators and Where to Find Them[](#validators-and-where-to-find-them "Direct link to heading")
Bootstrapping is all about downloading all previously accepted containers *securely* so a node can have the latest correct state of the chain. A node can't arbitrarily trust any source - a malicious actor could provide malicious blocks, corrupting the bootstrapping node's local state, and making it impossible for the node to correctly validate the network and reach consensus with other correct nodes.
What's the most reliable source of information in the Avalanche ecosystem? It's a *large enough* majority of validators. Therefore, the first step of bootstrapping is finding a sufficient amount of validators to download containers from.
The P-Chain is responsible for all platform-level operations, including staking events that modify an Avalanche L1's validator set. Whenever any chain (aside from the P-Chain itself) bootstraps, it requests an up-to-date validator set for that Avalanche L1 (Primary Network is an Avalanche L1 too). Once the Avalanche L1's current validator set is known, the node can securely download containers from these validators to bootstrap the chain.
There is a caveat here: the validator set must be *up-to-date*. If a bootstrapping node's validator set is stale, the node may incorrectly believe that some nodes are still validators when their validation period has already expired. A node might unknowingly end up requesting blocks from non-validators which respond with malicious blocks that aren't safe to download.
**For this reason, every Avalanche node must fully bootstrap the P-chain first before moving on to the other Primary Network chains and other Avalanche L1s to guarantee that their validator sets are up-to-date**.
What about the P-chain? The P-chain can't ever have an up-to-date validator set before completing its bootstrap. To solve this chicken-and-egg situation the Avalanche Foundation maintains a trusted default set of validators called beacons (but users are free to configure their own). Beacon Node-IDs and IP addresses are listed in the [AvalancheGo codebase](https://github.com/ava-labs/avalanchego/blob/master/genesis/bootstrappers.json). Every node has the beacon list available from the start and can reach out to them as soon as it starts.
Validators are the only sources of truth for a blockchain. Validator availability is so key to the bootstrapping process that **bootstrapping is blocked until the node establishes a sufficient amount of secure connections to validators**. If the node fails to reach a sufficient amount within a given period of time, it shuts down as no operation can be carried out safely.
## Bootstrapping the Blockchain[](#bootstrapping-the-blockchain "Direct link to heading")
Once a node is able to discover and connect to validator and beacon nodes, it's able to start bootstrapping the blockchain by downloading the individual containers.
One common misconception is that Avalanche blockchains are bootstrapped by retrieving containers starting at genesis and working up to the currently accepted frontier.
Instead, containers are downloaded from the accepted frontier downwards to genesis, and then their corresponding state transitions are executed upwards from genesis to the accepted frontier. The accepted frontier is the last accepted block for linear chains.
Why can't nodes simply download blocks in chronological order, starting from genesis upwards? The reason is efficiency: if nodes downloaded containers upwards they would only get a safety guarantee by polling a majority of validators for every single container. That's a lot of network traffic for a single container, and a node would still need to do that for each container in the chain.
Instead, if a node starts by securely retrieving the accepted frontier from a majority of honest nodes and then recursively fetches the parent containers from the accepted frontier down to genesis, it can cheaply check that containers are correct just by verifying their IDs. Each Avalanche container has the IDs of its parents (one block parent for linear chains) and an ID's integrity can be guaranteed cryptographically.
Let's dive deeper into the two bootstrap phases - frontier retrieval and container execution.
### Frontier Retrieval[](#frontier-retrieval "Direct link to heading")
The current frontier is retrieved by requesting them from validator or beacon nodes. Avalanche bootstrap is designed to be robust - it must be able to make progress even in the presence of slow validators or network failures. This process needs to be fault-tolerant to these types of failures, since bootstrapping may take quite some time to complete and network connections can be unreliable.
Bootstrap starts when a node has connected to a sufficient majority of validator stake. A node is able to start bootstrapping when it has connected to at least 75%75\\% of total validator stake.
Seeders are the first set of peers that a node reaches out to when trying to figure out the current frontier. A subset of seeders is randomly sampled from the validator set. Seeders might be slow and provide a stale frontier, be malicious and return malicious container IDs, but they always provide an initial set of candidate frontiers to work with.
Once a node has received the candidate frontiers form its seeders, it polls **every network validator** to vet the candidates frontiers. It sends the list of candidate frontiers it received from the seeders to each validator, asking whether or not they know about these frontiers. Each validator responds returning the subset of known candidates, regardless of how up-to-date or stale the containers are. Each validator returns containers irrespective of their age so that bootstrap works even in the presence of a stale frontier.
Frontier retrieval is completed when at least one of the candidate frontiers is supported by at least 50%50\\% of total validator stake. Multiple candidate frontiers may be supported by a majority of stake, after which point the next phase, container fetching starts.
At any point in these steps a network issue may occur, preventing a node from retrieving or validating frontiers. If this occurs, bootstrap restarts by sampling a new set of seeders and repeating the bootstrapping process, optimistically assuming that the network issue will go away.
### Containers Execution[](#containers-execution "Direct link to heading")
Once a node has at least one valid frontiers, it starts downloading parent containers for each frontier. If it's the first time the node is running, it won't know about any containers and will try fetching all parent containers recursively from the accepted frontier down to genesis (unless [state sync](#state-sync) is enabled). If bootstrap had already run previously, some containers are already available locally and the node will stop as soon as it finds a known one.
A node first just fetches and parses containers. Once the chain is complete, the node executes them in chronological order starting from the earliest downloaded container to the accepted frontier. This allows the node to rebuild the full chain state and to eventually be in sync with the rest of the network.
## When Does Bootstrapping Finish?[](#when-does-bootstrapping-finish "Direct link to heading")
You've seen how [bootstrap works](#bootstrapping-the-blockchain) for a single chain. However, a node must bootstrap the chains in the Primary Network as well as the chains in each Avalanche L1 it tracks. This begs the questions - when are these chains bootstrapped? When is a node done bootstrapping?
The P-chain is always the first to bootstrap before any other chain. Once the P-Chain has finished, all other chains start bootstrapping in parallel, connecting to their own validators independently of one another.
A node completes bootstrapping an Avalanche L1 once all of its corresponding chains have completed bootstrapping. Because the Primary Network is a special case of Avalanche L1 that includes the entire network, this applies to it as well as any other manually tracked Avalanche L1s.
Note that Avalanche L1s bootstrap is independently of one another - so even if one Avalanche L1 has bootstrapped and is validating new transactions and adding new containers, other Avalanche L1s may still be bootstrapping in parallel.
Within a single Avalanche L1 however, an Avalanche L1 isn't done bootstrapping until the last chain completes bootstrapping. It's possible for a single chain to effectively stall a node from finishing the bootstrap for a single Avalanche L1, if it has a sufficiently long history or each operation is complex and time consuming. Even worse, other Avalanche L1 validators are continuously accepting new transactions and adding new containers on top of the previously known frontier, so a node that's slow to bootstrap can continuously fall behind the rest of the network.
Nodes mitigate this by restarting bootstrap for any chains which is blocked waiting for the remaining Avalanche L1 chains to finish bootstrapping. These chains repeat the frontier retrieval and container downloading phases to stay up-to-date with the Avalanche L1's ever moving current frontier until the slowest chain has completed bootstrapping.
Once this is complete, a node is finally ready to validate the network.
## State Sync[](#state-sync "Direct link to heading")
The full node bootstrap process is long, and gets longer and longer over time as more and more containers are accepted. Nodes need to bootstrap a chain by reconstructing the full chain state locally - but downloading and executing each container isn't the only way to do this.
Starting from [AvalancheGo version 1.7.11](https://github.com/ava-labs/avalanchego/releases/tag/v1.7.11), nodes can use state sync to drastically cut down bootstrapping time on the C-Chain. Instead of executing each block, state sync uses cryptographic techniques to download and verify just the state associated with the current frontier. State synced nodes can't serve every C-chain block ever historically accepted, but they can safely retrieve the full C-chain state needed to validate in a much shorter time. State sync will fetch the previous 256 blocks prior to support the previous block hash operation code.
State sync is currently only available for the C-chain. The P-chain and X-chain currently bootstrap by downloading all blocks. Note that irrespective of the bootstrap method used (including state sync), each chain is still blocked on all other chains in its Avalanche L1 completing their bootstrap before continuing into normal operation.
There are no configs to state sync an archival node. If you need all the historical state then you must not use state sync and setup the config of the node for an archival node.
## Conclusions and FAQ[](#conclusions-and-faq "Direct link to heading")
If you got this far, you've hopefully gotten a better idea of what's going on when your node bootstraps. Here's a few frequently asked questions about bootstrapping.
### How Can I Get the ETA for Node Bootstrap?[](#how-can-i-get-the-eta-for-node-bootstrap "Direct link to heading")
Logs provide information about both container downloading and their execution for each chain. Here is an example
```bash
[02-16|17:31:42.950] INFO bootstrap/bootstrapper.go:494 fetching blocks {"numFetchedBlocks": 5000, "numTotalBlocks": 101357, "eta": "2m52s"}
[02-16|17:31:58.110] INFO
bootstrap/bootstrapper.go:494 fetching blocks {"numFetchedBlocks": 10000, "numTotalBlocks": 101357, "eta": "3m40s"}
[02-16|17:32:04.554] INFO
bootstrap/bootstrapper.go:494 fetching blocks {"numFetchedBlocks": 15000, "numTotalBlocks": 101357, "eta": "2m56s"}
...
[02-16|17:36:52.404] INFO
queue/jobs.go:203 executing operations {"numExecuted": 17881, "numToExecute": 101357, "eta": "2m20s"}
[02-16|17:37:22.467] INFO
queue/jobs.go:203 executing operations {"numExecuted": 35009, "numToExecute": 101357, "eta": "1m54s"}
[02-16|17:37:52.468] INFO
queue/jobs.go:203 executing operations {"numExecuted": 52713, "numToExecute": 101357, "eta": "1m23s"}
```
Similar logs are emitted for X and C chains and any chain in explicitly tracked Avalanche L1s.
### Why Chain Bootstrap ETA Keeps On Changing?[](#why-chain-bootstrap-eta-keeps-on-changing "Direct link to heading")
As you saw in the [bootstrap completion section](#when-does-bootstrapping-finish), an Avalanche L1 like the Primary Network completes once all of its chains finish bootstrapping. Some Avalanche L1 chains may have to wait for the slowest to finish. They'll restart bootstrapping in the meantime, to make sure they won't fall back too much with respect to the network accepted frontier.
## What Order Do The Chains Bootstrap?[](#what-order-do-the-chains-bootstrap "Direct link to heading")
The 3 chains will bootstrap in the following order: P-chain, X-chain, C-chain.
### Why Are AvalancheGo APIs Disabled During Bootstrapping?[](#why-are-avalanchego-apis-disabled-during-bootstrapping "Direct link to heading")
AvalancheGo APIs are [explicitly disabled](https://github.com/ava-labs/avalanchego/blob/master/api/server/server.go#L367:L379) during bootstrapping. The reason is that if the node has not fully rebuilt its Avalanche L1s state, it can't provide accurate information. AvalancheGo APIs are activated once bootstrap completes and node transition into its normal operating mode, accepting and validating transactions.
# Enroll in Avalanche Notify
URL: /docs/nodes/maintain/enroll-in-avalanche-notify
To receive email alerts if a validator becomes unresponsive or out-of-date, sign up with the Avalanche Notify tool: [http://notify.avax.network](http://notify.avax.network/).
Avalanche Notify is an active monitoring system that checks a validator's responsiveness each minute.
An email alert is sent if a validator is down for 5 consecutive checks and when a validator recovers (is responsive for 5 checks in a row).
}>
When signing up for email alerts, consider using a new, alias, or auto-forwarding email address to protect your privacy. Otherwise, it will be possible to link your NodeID to your email.
This tool is currently in BETA and validator alerts may erroneously be triggered, not triggered, or delayed. The best way to maximize the likelihood of earning staking rewards is to run redundant monitoring/alerting.
# Monitoring
URL: /docs/nodes/maintain/monitoring
Learn how to monitor an AvalancheGo node.
This tutorial demonstrates how to set up infrastructure to monitor an instance of [AvalancheGo](https://github.com/ava-labs/avalanchego). We will use:
* [Prometheus](https://prometheus.io/) to gather and store data
* [`node_exporter`](https://github.com/prometheus/node_exporter) to get information about the machine,
* AvalancheGo's [Metrics API](/docs/api-reference/metrics-api) to get information about the node
* [Grafana](https://grafana.com/) to visualize data on a dashboard.
* A set of pre-made [Avalanche dashboards](https://github.com/ava-labs/avalanche-monitoring/tree/main/grafana/dashboards)
## Prerequisites:
* A running AvalancheGo node
* Shell access to the machine running the node
* Administrator privileges on the machine
This tutorial assumes you have Ubuntu 20.04 running on your node. Other Linux flavors that use `systemd` for running services and `apt-get` for package management might work but have not been tested. Community member has reported it works on Debian 10, might work on other Debian releases as well.
### Caveat: Security
The system as described here **should not** be opened to the public internet. Neither Prometheus nor Grafana as shown here is hardened against unauthorized access. Make sure that both of them are accessible only over a secured proxy, local network, or VPN. Setting that up is beyond the scope of this tutorial, but exercise caution. Bad security practices could lead to attackers gaining control over your node! It is your responsibility to follow proper security practices.
## Monitoring Installer Script[](#monitoring-installer-script "Direct link to heading")
In order to make node monitoring easier to install, we have made a script that does most of the work for you. To download and run the script, log into the machine the node runs on with a user that has administrator privileges and enter the following command:
```bash
wget -nd -m https://raw.githubusercontent.com/ava-labs/avalanche-monitoring/main/grafana/monitoring-installer.sh ;\
chmod 755 monitoring-installer.sh;
```
This will download the script and make it executable.
Script itself is run multiple times with different arguments, each installing a different tool or part of the environment. To make sure it downloaded and set up correctly, begin by running:
```bash
./monitoring-installer.sh --help
```
It should display:
```bash
Usage: ./monitoring-installer.sh [--1|--2|--3|--4|--5|--help]
Options:
--help Shows this message
--1 Step 1: Installs Prometheus
--2 Step 2: Installs Grafana
--3 Step 3: Installs node_exporter
--4 Step 4: Installs AvalancheGo Grafana dashboards
--5 Step 5: (Optional) Installs additional dashboards
Run without any options, script will download and install latest version of AvalancheGo dashboards.
```
Let's get to it.
## Step 1: Set up Prometheus [](#step-1-set-up-prometheus- "Direct link to heading")
Run the script to execute the first step:
```bash
./monitoring-installer.sh --1
```
It should produce output something like this:
```bash
AvalancheGo monitoring installer
--------------------------------
STEP 1: Installing Prometheus
Checking environment...
Found arm64 architecture...
Prometheus install archive found:
https://github.com/prometheus/prometheus/releases/download/v2.31.0/prometheus-2.31.0.linux-arm64.tar.gz
Attempting to download:
https://github.com/prometheus/prometheus/releases/download/v2.31.0/prometheus-2.31.0.linux-arm64.tar.gz
prometheus.tar.gz 100%[=========================================================================================>] 65.11M 123MB/s in 0.5s
2021-11-05 14:16:11 URL:https://github-releases.githubusercontent.com/6838921/a215b0e7-df1f-402b-9541-a3ec9d431f76?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20211105%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20211105T141610Z&X-Amz-Expires=300&X-Amz-Signature=72a8ae4c6b5cea962bb9cad242cb4478082594b484d6a519de58b8241b319d94&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=6838921&response-content-disposition=attachment%3B%20filename%3Dprometheus-2.31.0.linux-arm64.tar.gz&response-content-type=application%2Foctet-stream [68274531/68274531] -> "prometheus.tar.gz" [1]
...
```
You may be prompted to confirm additional package installs, do that if asked. Script run should end with instructions on how to check that Prometheus installed correctly. Let's do that, run:
```bash
sudo systemctl status prometheus
```
It should output something like:
```bash
● prometheus.service - Prometheus
Loaded: loaded (/etc/systemd/system/prometheus.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2021-11-12 11:38:32 UTC; 17min ago
Docs: https://prometheus.io/docs/introduction/overview/
Main PID: 548 (prometheus)
Tasks: 10 (limit: 9300)
Memory: 95.6M
CGroup: /system.slice/prometheus.service
└─548 /usr/local/bin/prometheus --config.file=/etc/prometheus/prometheus.yml --storage.tsdb.path=/var/lib/prometheus --web.console.templates=/etc/prometheus/con>
Nov 12 11:38:33 ip-172-31-36-200 prometheus[548]: ts=2021-11-12T11:38:33.644Z caller=head.go:590 level=info component=tsdb msg="WAL segment loaded" segment=81 maxSegment=84
Nov 12 11:38:33 ip-172-31-36-200 prometheus[548]: ts=2021-11-12T11:38:33.773Z caller=head.go:590 level=info component=tsdb msg="WAL segment loaded" segment=82 maxSegment=84
```
Note the `active (running)` status (press `q` to exit). You can also check Prometheus web interface, available on `http://your-node-host-ip:9090/`
You may need to do `sudo ufw allow 9090/tcp` if the firewall is on, and/or adjust the security settings to allow connections to port 9090 if the node is running on a cloud instance. For AWS, you can look it up [here](/docs/nodes/on-third-party-services/amazon-web-services#create-a-security-group). If on public internet, make sure to only allow your IP to connect!
If everything is OK, let's move on.
## Step 2: Install Grafana [](#step-2-install-grafana- "Direct link to heading")
Run the script to execute the second step:
```bash
./monitoring-installer.sh --2
```
It should produce output something like this:
```bash
AvalancheGo monitoring installer
--------------------------------
STEP 2: Installing Grafana
OK
deb https://packages.grafana.com/oss/deb stable main
Hit:1 http://us-east-2.ec2.ports.ubuntu.com/ubuntu-ports focal InRelease
Get:2 http://us-east-2.ec2.ports.ubuntu.com/ubuntu-ports focal-updates InRelease [114 kB]
Get:3 http://us-east-2.ec2.ports.ubuntu.com/ubuntu-ports focal-backports InRelease [101 kB]
Hit:4 http://ppa.launchpad.net/longsleep/golang-backports/ubuntu focal InRelease
Get:5 http://ports.ubuntu.com/ubuntu-ports focal-security InRelease [114 kB]
Get:6 https://packages.grafana.com/oss/deb stable InRelease [12.1 kB]
...
```
To make sure it's running properly:
```bash
sudo systemctl status grafana-server
```
which should again show Grafana as `active`. Grafana should now be available at `http://your-node-host-ip:3000/` from your browser. Log in with username: admin, password: admin, and you will be prompted to set up a new, secure password. Do that.
You may need to do `sudo ufw allow 3000/tcp` if the firewall is on, and/or adjust the cloud instance settings to allow connections to port 3000. If on public internet, make sure to only allow your IP to connect!
Prometheus and Grafana are now installed, we're ready for the next step.
## Step 3: Set up `node_exporter` [](#step-3-set-up-node_exporter- "Direct link to heading")
In addition to metrics from AvalancheGo, let's set up monitoring of the machine itself, so we can check CPU, memory, network and disk usage and be aware of any anomalies. For that, we will use `node_exporter`, a Prometheus plugin.
Run the script to execute the third step:
```bash
./monitoring-installer.sh --3
```
The output should look something like this:
```bash
AvalancheGo monitoring installer
--------------------------------
STEP 3: Installing node_exporter
Checking environment...
Found arm64 architecture...
Downloading archive...
https://github.com/prometheus/node_exporter/releases/download/v1.2.2/node_exporter-1.2.2.linux-arm64.tar.gz
node_exporter.tar.gz 100%[=========================================================================================>] 7.91M --.-KB/s in 0.1s
2021-11-05 14:57:25 URL:https://github-releases.githubusercontent.com/9524057/6dc22304-a1f5-419b-b296-906f6dd168dc?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20211105%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20211105T145725Z&X-Amz-Expires=300&X-Amz-Signature=3890e09e58ea9d4180684d9286c9e791b96b0c411d8f8a494f77e99f260bdcbb&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=9524057&response-content-disposition=attachment%3B%20filename%3Dnode_exporter-1.2.2.linux-arm64.tar.gz&response-content-type=application%2Foctet-stream [8296266/8296266] -> "node_exporter.tar.gz" [1]
node_exporter-1.2.2.linux-arm64/LICENSE
```
Again, we check that the service is running correctly:
```bash
sudo systemctl status node_exporter
```
If the service is running, Prometheus, Grafana and `node_exporter` should all work together now. To check, in your browser visit Prometheus web interface on `http://your-node-host-ip:9090/targets`. You should see three targets enabled:
* Prometheus
* AvalancheGo
* `avalanchego-machine`
Make sure that all of them have `State` as `UP`.
If you run your AvalancheGo node with TLS enabled on your API port, you will need to manually edit the `/etc/prometheus/prometheus.yml` file and change the `avalanchego` job to look like this:
```yml
- job_name: "avalanchego"
metrics_path: "/ext/metrics"
scheme: "https"
tls_config:
insecure_skip_verify: true
static_configs:
- targets: ["localhost:9650"]
```
Mind the spacing (leading spaces too)! You will need admin privileges to do that (use `sudo`). Restart Prometheus service afterwards with `sudo systemctl restart prometheus`.
All that's left to do now is to provision the data source and install the actual dashboards that will show us the data.
## Step 4: Dashboards [](#step-4-dashboards- "Direct link to heading")
Run the script to install the dashboards:
```bash
./monitoring-installer.sh --4
```
It will produce output something like this:
```bash
AvalancheGo monitoring installer
--------------------------------
Downloading...
Last-modified header missing -- time-stamps turned off.
2021-11-05 14:57:47 URL:https://raw.githubusercontent.com/ava-labs/avalanche-monitoring/master/grafana/dashboards/c_chain.json [50282/50282] -> "c_chain.json" [1]
FINISHED --2021-11-05 14:57:47--
Total wall clock time: 0.2s
Downloaded: 1 files, 49K in 0s (132 MB/s)
Last-modified header missing -- time-stamps turned off.
...
```
This will download the latest versions of the dashboards from GitHub and provision Grafana to load them, as well as defining Prometheus as a data source. It may take up to 30 seconds for the dashboards to show up. In your browser, go to: `http://your-node-host-ip:3000/dashboards`. You should see 7 Avalanche dashboards:
Select 'Avalanche Main Dashboard' by clicking its title. It should load, and look similar to this:
Some graphs may take some time to populate fully, as they need a series of data points in order to render correctly.
You can bookmark the main dashboard as it shows the most important information about the node at a glance. Every dashboard has a link to all the others as the first row, so you can move between them easily.
## Step 5: Additional Dashboards (Optional)[](#step-5-additional-dashboards-optional "Direct link to heading")
Step 4 installs the basic set of dashboards that make sense to have on any node. Step 5 is for installing additional dashboards that may not be useful for every installation.
Currently, there is only one additional dashboard: Avalanche L1s. If your node is running any Avalanche L1s, you may want to add this as well. Do:
```bash
./monitoring-installer.sh --5
```
This will add the Avalanche L1s dashboard. It allows you to monitor operational data for any Avalanche L1 that is synced on the node. There is an Avalanche L1 switcher that allows you to switch between different Avalanche L1s. As there are many Avalanche L1s and not every node will have all of them, by default, it comes populated only with Spaces and WAGMI Avalanche L1s that exist on Fuji testnet:
To configure the dashboard and add any Layer 1s that your node is syncing, you will need to edit the dashboard. Select the `dashboard settings` icon (image of a cog) in the upper right corner of the dashboard display and switch to `Variables` section and select the `subnet` variable. It should look something like this:
The variable format is:
```bash
Subnet name:
```
and the separator between entries is a comma. Entries for Spaces and WAGMI look like:
```bash
Spaces (Fuji) : 2ebCneCbwthjQ1rYT41nhd7M76Hc6YmosMAQrTFhBq8qeqh6tt, WAGMI (Fuji) : 2AM3vsuLoJdGBGqX2ibE8RGEq4Lg7g4bot6BT1Z7B9dH5corUD
```
After editing the values, press `Update` and then click `Save dashboard` button and confirm. Press the back arrow in the upper left corner to return to the dashboard. New values should now be selectable from the dropdown and data for the selected Avalanche L1 will be shown in the panels.
## Updating[](#updating "Direct link to heading")
Available node metrics are updated constantly, new ones are added and obsolete removed, so it is good a practice to update the dashboards from time to time, especially if you notice any missing data in panels. Updating the dashboards is easy, just run the script with no arguments, and it will refresh the dashboards with the latest available versions. Allow up to 30s for dashboards to update in Grafana.
If you added the optional extra dashboards (step 5), they will be updated as well.
## Summary[](#summary "Direct link to heading")
Using the script to install node monitoring is easy, and it gives you insight into how your node is behaving and what's going on under the hood. Also, pretty graphs!
If you have feedback on this tutorial, problems with the script or following the steps, send us a message on [Discord](https://chat.avalabs.org/).
# Reduce Disk Usage
URL: /docs/nodes/maintain/reduce-disk-usage
Offline Pruning is ported from `go-ethereum` to reduce the amount of disk space taken up by the TrieDB (storage for the Merkle Forest).
Offline pruning creates a bloom filter and adds all trie nodes in the active state to the bloom filter to mark the data as protected. This ensures that any part of the active state will not be removed during offline pruning.
After generating the bloom filter, offline pruning iterates over the database and searches for trie nodes that are safe to be removed from disk.
A bloom filter is a probabilistic data structure that reports whether an item is definitely not in a set or possibly in a set. Therefore, for each key we iterate, we check if it is in the bloom filter. If the key is definitely not in the bloom filter, then it is not in the active state and we can safely delete it. If the key is possibly in the set, then we skip over it to ensure we do not delete any active state.
During iteration, the underlying database (LevelDB) writes deletion markers, causing a temporary increase in disk usage.
After iterating over the database and deleting any old trie nodes that it can, offline pruning then runs compaction to minimize the DB size after the potentially large number of delete operations.
## Finding the C-Chain Config File[](#finding-the-c-chain-config-file "Direct link to heading")
In order to enable offline pruning, you need to update the C-Chain config file to include the parameters `offline-pruning-enabled` and `offline-pruning-data-directory`.
The default location of the C-Chain config file is `~/.avalanchego/configs/chains/C/config.json`. **Please note that by default, this file does not exist. You would need to create it manually.** You can update the directory for chain configs by passing in the directory of your choice via the CLI argument: `chain-config-dir`. See [this](/docs/nodes/configure/configs-flags) for more info. For example, if you start your node with:
```bash
./build/avalanchego --chain-config-dir=/home/ubuntu/chain-configs
```
The chain config directory will be updated to `/home/ubuntu/chain-configs` and the corresponding C-Chain config file will be: `/home/ubuntu/chain-configs/C/config.json`.
## Running Offline Pruning[](#running-offline-pruning "Direct link to heading")
In order to enable offline pruning, update the C-Chain config file to include the following parameters:
```json
{
"offline-pruning-enabled": true,
"offline-pruning-data-directory": "/home/ubuntu/offline-pruning"
}
```
This will set `/home/ubuntu/offline-pruning` as the directory to be used by the offline pruner. Offline pruning will store the bloom filter in this location, so you must ensure that the path exists.
Now that the C-Chain config file has been updated, you can start your node with the command (no CLI arguments are necessary if using the default chain config directory):
Once AvalancheGo starts the C-Chain, you can expect to see update logs from the offline pruner:
```bash
INFO [02-09|00:20:15.625] Iterating state snapshot accounts=297,231 slots=6,669,708 elapsed=16.001s eta=1m29.03s
INFO [02-09|00:20:23.626] Iterating state snapshot accounts=401,907 slots=10,698,094 elapsed=24.001s eta=1m32.522s
INFO [02-09|00:20:31.626] Iterating state snapshot accounts=606,544 slots=13,891,948 elapsed=32.002s eta=1m10.927s
INFO [02-09|00:20:39.626] Iterating state snapshot accounts=760,948 slots=18,025,523 elapsed=40.002s eta=1m2.603s
INFO [02-09|00:20:47.626] Iterating state snapshot accounts=886,583 slots=21,769,199 elapsed=48.002s eta=1m8.834s
INFO [02-09|00:20:55.626] Iterating state snapshot accounts=1,046,295 slots=26,120,100 elapsed=56.002s eta=57.401s
INFO [02-09|00:21:03.626] Iterating state snapshot accounts=1,229,257 slots=30,241,391 elapsed=1m4.002s eta=47.674s
INFO [02-09|00:21:11.626] Iterating state snapshot accounts=1,344,091 slots=34,128,835 elapsed=1m12.002s eta=45.185s
INFO [02-09|00:21:19.626] Iterating state snapshot accounts=1,538,009 slots=37,791,218 elapsed=1m20.002s eta=34.59s
INFO [02-09|00:21:27.627] Iterating state snapshot accounts=1,729,564 slots=41,694,303 elapsed=1m28.002s eta=25.006s
INFO [02-09|00:21:35.627] Iterating state snapshot accounts=1,847,617 slots=45,646,011 elapsed=1m36.003s eta=20.052s
INFO [02-09|00:21:43.627] Iterating state snapshot accounts=1,950,875 slots=48,832,722 elapsed=1m44.003s eta=9.299s
INFO [02-09|00:21:47.342] Iterated snapshot accounts=1,950,875 slots=49,667,870 elapsed=1m47.718s
INFO [02-09|00:21:47.351] Writing state bloom to disk name=/home/ubuntu/offline-pruning/statebloom.0xd6fca36db4b60b34330377040ef6566f6033ed8464731cbb06dc35c8401fa38e.bf.gz
INFO [02-09|00:23:04.421] State bloom filter committed name=/home/ubuntu/offline-pruning/statebloom.0xd6fca36db4b60b34330377040ef6566f6033ed8464731cbb06dc35c8401fa38e.bf.gz
```
The bloom filter should be populated and committed to disk after about 5 minutes. At this point, if the node shuts down, it will resume the offline pruning session when it restarts (note: this operation cannot be cancelled).
In order to ensure that users do not mistakenly leave offline pruning enabled for the long term (which could result in an hour of downtime on each restart), we have added a manual protection which requires that after an offline pruning session, the node must be started with offline pruning disabled at least once before it will start with offline pruning enabled again. Therefore, once the bloom filter has been committed to disk, you should update the C-Chain config file to include the following parameters:
```json
{
"offline-pruning-enabled": false,
"offline-pruning-data-directory": "/home/ubuntu/offline-pruning"
}
```
It is important to keep the same data directory in the config file, so that the node knows where to look for the bloom filter on a restart if offline pruning has not finished.
Now if your node restarts, it will be marked as having correctly disabled offline pruning after the run and be allowed to resume normal operation once offline pruning has finished running.
You will see progress logs throughout the offline pruning run which will indicate the session's progress:
```bash
INFO [02-09|00:31:51.920] Pruning state data nodes=40,116,759 size=10.08GiB elapsed=8m47.499s eta=12m50.961s
INFO [02-09|00:31:59.921] Pruning state data nodes=41,659,059 size=10.47GiB elapsed=8m55.499s eta=12m13.822s
INFO [02-09|00:32:07.921] Pruning state data nodes=41,687,047 size=10.48GiB elapsed=9m3.499s eta=12m23.915s
INFO [02-09|00:32:15.921] Pruning state data nodes=41,715,823 size=10.48GiB elapsed=9m11.499s eta=12m33.965s
INFO [02-09|00:32:23.921] Pruning state data nodes=41,744,167 size=10.49GiB elapsed=9m19.500s eta=12m44.004s
INFO [02-09|00:32:31.921] Pruning state data nodes=41,772,613 size=10.50GiB elapsed=9m27.500s eta=12m54.01s
INFO [02-09|00:32:39.921] Pruning state data nodes=41,801,267 size=10.50GiB elapsed=9m35.500s eta=13m3.992s
INFO [02-09|00:32:47.922] Pruning state data nodes=41,829,714 size=10.51GiB elapsed=9m43.500s eta=13m13.951s
INFO [02-09|00:32:55.922] Pruning state data nodes=41,858,400 size=10.52GiB elapsed=9m51.501s eta=13m23.885s
INFO [02-09|00:33:03.923] Pruning state data nodes=41,887,131 size=10.53GiB elapsed=9m59.501s eta=13m33.79s
INFO [02-09|00:33:11.923] Pruning state data nodes=41,915,583 size=10.53GiB elapsed=10m7.502s eta=13m43.678s
INFO [02-09|00:33:19.924] Pruning state data nodes=41,943,891 size=10.54GiB elapsed=10m15.502s eta=13m53.551s
INFO [02-09|00:33:27.924] Pruning state data nodes=41,972,281 size=10.55GiB elapsed=10m23.502s eta=14m3.389s
INFO [02-09|00:33:35.924] Pruning state data nodes=42,001,414 size=10.55GiB elapsed=10m31.503s eta=14m13.192s
INFO [02-09|00:33:43.925] Pruning state data nodes=42,029,987 size=10.56GiB elapsed=10m39.504s eta=14m22.976s
INFO [02-09|00:33:51.925] Pruning state data nodes=42,777,042 size=10.75GiB elapsed=10m47.504s eta=14m7.245s
INFO [02-09|00:34:00.950] Pruning state data nodes=42,865,413 size=10.77GiB elapsed=10m56.529s eta=14m15.927s
INFO [02-09|00:34:08.956] Pruning state data nodes=42,918,719 size=10.79GiB elapsed=11m4.534s eta=14m24.453s
INFO [02-09|00:34:22.816] Pruning state data nodes=42,952,925 size=10.79GiB elapsed=11m18.394s eta=14m41.243s
INFO [02-09|00:34:30.818] Pruning state data nodes=42,998,715 size=10.81GiB elapsed=11m26.397s eta=14m49.961s
INFO [02-09|00:34:38.828] Pruning state data nodes=43,046,476 size=10.82GiB elapsed=11m34.407s eta=14m58.572s
INFO [02-09|00:34:46.893] Pruning state data nodes=43,107,656 size=10.83GiB elapsed=11m42.472s eta=15m6.729s
INFO [02-09|00:34:55.038] Pruning state data nodes=43,168,834 size=10.85GiB elapsed=11m50.616s eta=15m14.934s
INFO [02-09|00:35:03.039] Pruning state data nodes=43,446,900 size=10.92GiB elapsed=11m58.618s eta=15m14.705s
```
When the node completes, it will emit the following log and resume normal operation:
```bash
INFO [02-09|00:42:16.009] Pruning state data nodes=93,649,812 size=23.53GiB elapsed=19m11.588s eta=1m2.658s
INFO [02-09|00:42:24.009] Pruning state data nodes=95,045,956 size=23.89GiB elapsed=19m19.588s eta=45.149s
INFO [02-09|00:42:32.009] Pruning state data nodes=96,429,410 size=24.23GiB elapsed=19m27.588s eta=28.041s
INFO [02-09|00:42:40.009] Pruning state data nodes=97,811,804 size=24.58GiB elapsed=19m35.588s eta=11.204s
INFO [02-09|00:42:45.359] Pruned state data nodes=98,744,430 size=24.82GiB elapsed=19m40.938s
INFO [02-09|00:42:45.360] Compacting database range=0x00-0x10 elapsed="2.157µs"
INFO [02-09|00:43:12.311] Compacting database range=0x10-0x20 elapsed=26.951s
INFO [02-09|00:43:38.763] Compacting database range=0x20-0x30 elapsed=53.402s
INFO [02-09|00:44:04.847] Compacting database range=0x30-0x40 elapsed=1m19.486s
INFO [02-09|00:44:31.194] Compacting database range=0x40-0x50 elapsed=1m45.834s
INFO [02-09|00:45:31.580] Compacting database range=0x50-0x60 elapsed=2m46.220s
INFO [02-09|00:45:58.465] Compacting database range=0x60-0x70 elapsed=3m13.104s
INFO [02-09|00:51:17.593] Compacting database range=0x70-0x80 elapsed=8m32.233s
INFO [02-09|00:56:19.679] Compacting database range=0x80-0x90 elapsed=13m34.319s
INFO [02-09|00:56:46.011] Compacting database range=0x90-0xa0 elapsed=14m0.651s
INFO [02-09|00:57:12.370] Compacting database range=0xa0-0xb0 elapsed=14m27.010s
INFO [02-09|00:57:38.600] Compacting database range=0xb0-0xc0 elapsed=14m53.239s
INFO [02-09|00:58:06.311] Compacting database range=0xc0-0xd0 elapsed=15m20.951s
INFO [02-09|00:58:35.484] Compacting database range=0xd0-0xe0 elapsed=15m50.123s
INFO [02-09|00:59:05.449] Compacting database range=0xe0-0xf0 elapsed=16m20.089s
INFO [02-09|00:59:34.365] Compacting database range=0xf0- elapsed=16m49.005s
INFO [02-09|00:59:34.367] Database compaction finished elapsed=16m49.006s
INFO [02-09|00:59:34.367] State pruning successful pruned=24.82GiB elapsed=39m34.749s
INFO [02-09|00:59:34.367] Completed offline pruning. Re-initializing blockchain.
INFO [02-09|00:59:34.387] Loaded most recent local header number=10,671,401 hash=b52d0a..7bd166 age=40m29s
INFO [02-09|00:59:34.387] Loaded most recent local full block number=10,671,401 hash=b52d0a..7bd166 age=40m29s
INFO [02-09|00:59:34.387] Initializing snapshots async=true
DEBUG[02-09|00:59:34.390] Reinjecting stale transactions count=0
INFO [02-09|00:59:34.395] Transaction pool price threshold updated price=470,000,000,000
INFO [02-09|00:59:34.396] Transaction pool price threshold updated price=225,000,000,000
INFO [02-09|00:59:34.396] Transaction pool price threshold updated price=0
INFO [02-09|00:59:34.396] lastAccepted = 0xb52d0a1302e4055b487c3a0243106b5e13a915c6e178da9f8491cebf017bd166
INFO [02-09|00:59:34] snow/engine/snowman/transitive.go#67: initializing consensus engine
INFO [02-09|00:59:34] snow/engine/snowman/bootstrap/bootstrapper.go#220: Starting bootstrap...
INFO [02-09|00:59:34] chains/manager.go#246: creating chain:
ID: 2oYMBNV4eNHyqk2fjjV5nVQLDbtmNJzq5s3qs3Lo6ftnC6FByM
VMID:jvYyfQTxGMJLuGWa55kdP2p2zSUYsQ5Raupu4TW34ZAUBAbtq
INFO [02-09|00:59:34.425] Enabled APIs: eth, eth-filter, net, web3, internal-eth, internal-blockchain, internal-transaction, avax
DEBUG[02-09|00:59:34.425] Allowed origin(s) for WS RPC interface [*]
INFO [02-09|00:59:34] api/server/server.go#203: adding route /ext/bc/2q9e4r6Mu3U68nU1fYjgbR6JvwrRx36CohpAX5UQxse55x1Q5/avax
INFO [02-09|00:59:34] api/server/server.go#203: adding route /ext/bc/2q9e4r6Mu3U68nU1fYjgbR6JvwrRx36CohpAX5UQxse55x1Q5/rpc
INFO [02-09|00:59:34] api/server/server.go#203: adding route /ext/bc/2q9e4r6Mu3U68nU1fYjgbR6JvwrRx36CohpAX5UQxse55x1Q5/ws
INFO [02-09|00:59:34] vms/avm/vm.go#437: Fee payments are using Asset with Alias: AVAX, AssetID: FvwEAhmxKfeiG8SnEvq42hc6whRyY3EFYAvebMqDNDGCgxN5Z
INFO [02-09|00:59:34] vms/avm/vm.go#229: address transaction indexing is disabled
INFO [02-09|00:59:34] snow/engine/avalanche/transitive.go#71: initializing consensus engine
INFO [02-09|00:59:34] snow/engine/avalanche/bootstrap/bootstrapper.go#258: Starting bootstrap...
INFO [02-09|00:59:34] api/server/server.go#203: adding route /ext/bc/2oYMBNV4eNHyqk2fjjV5nVQLDbtmNJzq5s3qs3Lo6ftnC6FByM
INFO [02-09|00:59:34] snow/engine/snowman/bootstrap/bootstrapper.go#445: waiting for the remaining chains in this subnet to finish syncing
INFO [02-09|00:59:34] api/server/server.go#203: adding route /ext/bc/2oYMBNV4eNHyqk2fjjV5nVQLDbtmNJzq5s3qs3Lo6ftnC6FByM/wallet
INFO [02-09|00:59:34] api/server/server.go#203: adding route /ext/bc/2oYMBNV4eNHyqk2fjjV5nVQLDbtmNJzq5s3qs3Lo6ftnC6FByM/events
INFO [02-09|00:59:34]
snow/engine/common/bootstrapper.go#235: Bootstrapping started syncing with 1 vertices in the accepted frontier
INFO [02-09|00:59:46] snow/engine/common/bootstrapper.go#235: Bootstrapping started syncing with 2 vertices in the accepted frontier
INFO [02-09|00:59:49] snow/engine/common/bootstrapper.go#235: Bootstrapping started syncing with 1 vertices in the accepted frontier
INFO [02-09|00:59:49] snow/engine/avalanche/bootstrap/bootstrapper.go#473: bootstrapping fetched 55 vertices. Executing transaction state transitions...
INFO [02-09|00:59:49] snow/engine/common/queue/jobs.go#171: executed 55 operations
INFO [02-09|00:59:49] snow/engine/avalanche/bootstrap/bootstrapper.go#484: executing vertex state transitions...
INFO [02-09|00:59:49] snow/engine/common/queue/jobs.go#171: executed 55 operations
INFO [02-09|01:00:07] snow/engine/snowman/bootstrap/bootstrapper.go#406: bootstrapping fetched 1241 blocks. Executing state transitions...
```
At this point, the node will go into bootstrapping and (once bootstrapping completes) resume consensus and operate as normal.
## Disk Space Considerations[](#disk-space-considerations "Direct link to heading")
To ensure the node does not enter an inconsistent state, the bloom filter used for pruning is persisted to `offline-pruning-data-directory` for the duration of the operation. This directory should have `offline-pruning-bloom-filter-size` available in disk space (default 512 MB).
The underlying database (LevelDB) uses deletion markers (tombstones) to identify newly deleted keys. These markers are temporarily persisted to disk until they are removed during a process known as compaction. This will lead to an increase in disk usage during pruning. If your node runs out of disk space during pruning, you may safely restart the pruning operation. This may succeed as restarting the node triggers compaction.
If restarting the pruning operation does not succeed, additional disk space should be provisioned.
# Run Avalanche Node in Background
URL: /docs/nodes/maintain/run-as-background-service
This page demonstrates how to set up a `avalanchego.service` file to enable a manually deployed validator node to run in the background of a server instead of in the terminal directly.
Make sure that AvalancheGo is already installed on your machine.
## Steps[](#steps "Direct link to heading")
### Fuji Testnet Config[](#fuji-testnet-config "Direct link to heading")
Run this command in your terminal to create the `avalanchego.service` file
```bash
sudo nano /etc/systemd/system/avalanchego.service
```
Paste the following configuration into the `avalanchego.service` file
Remember to modify the values of:
* ***user=***
* ***group=***
* ***WorkingDirectory=***
* ***ExecStart=***
For those that you have configured on your Server:
```toml
[Unit]
Description=Avalanche Node service
After=network.target
[Service]
User='YourUserHere'
Group='YourUserHere'
Restart=always
PrivateTmp=true
TimeoutStopSec=60s
TimeoutStartSec=10s
StartLimitInterval=120s
StartLimitBurst=5
WorkingDirectory=/Your/Path/To/avalanchego
ExecStart=/Your/Path/To/avalanchego/./avalanchego \
--network-id=fuji \
--api-metrics-enabled=true
[Install]
WantedBy=multi-user.target
```
Press **Ctrl + X** then **Y** then **Enter** to save and exit.
Now, run:
```bash
sudo systemctl daemon-reload
```
### Mainnet Config[](#mainnet-config "Direct link to heading")
Run this command in your terminal to create the `avalanchego.service` file
```bash
sudo nano /etc/systemd/system/avalanchego.service
```
Paste the following configuration into the `avalanchego.service` file
```toml
[Unit]
Description=Avalanche Node service
After=network.target
[Service]
User='YourUserHere'
Group='YourUserHere'
Restart=always
PrivateTmp=true
TimeoutStopSec=60s
TimeoutStartSec=10s
StartLimitInterval=120s
StartLimitBurst=5
WorkingDirectory=/Your/Path/To/avalanchego
ExecStart=/Your/Path/To/avalanchego/./avalanchego \
--api-metrics-enabled=true
[Install]
WantedBy=multi-user.target
```
Press **Ctrl + X** then **Y** then **Enter** to save and exit.
Now, run:
```bash
sudo systemctl daemon-reload
```
## Start the Node[](#start-the-node "Direct link to heading")
This command makes your node start automatically in case of a reboot, run it:
```bash
sudo systemctl enable avalanchego
```
To start the node, run:
```bash
sudo systemctl start avalanchego
sudo systemctl status avalanchego
```
Output:
```bash
socopower@avalanche-node-01:~$ sudo systemctl status avalanchego
● avalanchego.service - Avalanche Node service
Loaded: loaded (/etc/systemd/system/avalanchego.service; enabled; vendor p>
Active: active (running) since Tue 2023-08-29 23:14:45 UTC; 5h 46min ago
Main PID: 2226 (avalanchego)
Tasks: 27 (limit: 38489)
Memory: 8.7G
CPU: 5h 50min 31.165s
CGroup: /system.slice/avalanchego.service
└─2226 /usr/local/bin/avalanchego/./avalanchego --network-id=fuji
Aug 30 03:02:50 avalanche-node-01 avalanchego[2226]: INFO [08-30|03:02:50.685] >
Aug 30 03:02:51 avalanche-node-01 avalanchego[2226]: INFO [08-30|03:02:51.185] >
Aug 30 03:03:09 avalanche-node-01 avalanchego[2226]: [08-30|03:03:09.380] INFO >
Aug 30 03:03:23 avalanche-node-01 avalanchego[2226]: [08-30|03:03:23.983] INFO >
Aug 30 03:05:15 avalanche-node-01 avalanchego[2226]: [08-30|03:05:15.192] INFO >
Aug 30 03:05:15 avalanche-node-01 avalanchego[2226]: [08-30|03:05:15.237] INFO >
Aug 30 03:05:15 avalanche-node-01 avalanchego[2226]: [08-30|03:05:15.238] INFO >
Aug 30 03:05:19 avalanche-node-01 avalanchego[2226]: [08-30|03:05:19.809] INFO >
Aug 30 03:05:19 avalanche-node-01 avalanchego[2226]: [08-30|03:05:19.809] INFO >
Aug 30 05:00:47 avalanche-node-01 avalanchego[2226]: [08-30|05:00:47.001] INFO
```
To see the synchronization process, you can run the following command:
```bash
sudo journalctl -fu avalanchego
```
# Upgrade Your AvalancheGo Node
URL: /docs/nodes/maintain/upgrade
## Backup Your Node[](#backup-your-node "Direct link to heading")
Before upgrading your node, it is recommended you backup your staker files which are used to identify your node on the network. In the default installation, you can copy them by running following commands:
```bash
cd
cp ~/.avalanchego/staking/staker.crt .
cp ~/.avalanchego/staking/staker.key .
```
Then download `staker.crt` and `staker.key` files and keep them somewhere safe and private. If anything happens to your node or the machine node runs on, these files can be used to fully recreate your node.
If you use your node for development purposes and have keystore users on your node, you should back up those too.
## Node Installed Using the Installer Script[](#node-installed-using-the-installer-script "Direct link to heading")
If you installed your node using the [installer script](/docs/nodes/using-install-script/installing-avalanche-go), to upgrade your node, just run the installer script again.
```bash
./avalanchego-installer.sh
```
It will detect that you already have AvalancheGo installed:
```bash
AvalancheGo installer
---------------------
Preparing environment...
Found 64bit Intel/AMD architecture...
Found AvalancheGo systemd service already installed, switching to upgrade mode.
Stopping service...
```
It will then upgrade your node to the latest version, and after it's done, start the node back up, and print out the information about the latest version:
```bash
Node upgraded, starting service...
New node version:
avalanche/1.1.1 [network=mainnet, database=v1.0.0, commit=f76f1fd5f99736cf468413bbac158d6626f712d2]
Done!
```
And that is it, your node is upgraded to the latest version.
If you installed your node manually, proceed with the rest of the tutorial.
## Stop the Old Node Version[](#stop-the-old-node-version "Direct link to heading")
After the backup is secured, you may start upgrading your node. Begin by stopping the currently running version.
### Node Running from Terminal[](#node-running-from-terminal "Direct link to heading")
If your node is running in a terminal stop it by pressing `ctrl+c`.
### Node Running as a Service[](#node-running-as-a-service "Direct link to heading")
If your node is running as a service, stop it by entering: `sudo systemctl stop avalanchego.service`
(your service may be named differently, `avalanche.service`, or similar)
### Node Running in Background[](#node-running-in-background "Direct link to heading")
If your node is running in the background (by running with `nohup`, for example) then find the process running the node by running `ps aux | grep avalanche`. This will produce output like:
```bash
ubuntu 6834 0.0 0.0 2828 676 pts/1 S+ 19:54 0:00 grep avalanche
ubuntu 2630 26.1 9.4 2459236 753316 ? Sl Dec02 1220:52 /home/ubuntu/build/avalanchego
```
In this example, second line shows information about your node. Note the process id, in this case, `2630`. Stop the node by running `kill -2 2630`.
Now we are ready to download the new version of the node. You can either download the source code and then build the binary program, or you can download the pre-built binary. You don't need to do both.
Downloading pre-built binary is easier and recommended if you're just looking to run your own node and stake on it.
Building the node [from source](/docs/nodes/maintain/upgrade#build-from-source) is recommended if you're a developer looking to experiment and build on Avalanche.
## Download Pre-Built Binary[](#download-pre-built-binary "Direct link to heading")
If you want to download a pre-built binary instead of building it yourself, go to our [releases page](https://github.com/ava-labs/avalanchego/releases), and select the release you want (probably the latest one.)
If you have a node, you can subscribe to the [avalanche notify service](/docs/nodes/maintain/enroll-in-avalanche-notify) with your node ID to be notified about new releases.
In addition, or if you don't have a node ID, you can get release notifications from github. To do so, you can go to our [repository](https://github.com/ava-labs/avalanchego) and look on the top-right corner for the **Watch** option. After you click on it, select **Custom**, and then **Releases**. Press **Apply** and it is done.
Under `Assets`, select the appropriate file.
For MacOS:\
Download: `avalanchego-macos-.zip`\
Unzip: `unzip avalanchego-macos-.zip`\
The resulting folder, `avalanchego-`, contains the binaries.
For Linux on PCs or cloud providers:\
Download: `avalanchego-linux-amd64-.tar.gz`\
Unzip: `tar -xvf avalanchego-linux-amd64-.tar.gz`\
The resulting folder, `avalanchego--linux`, contains the binaries.
For Linux on Arm64-based computers:\
Download: `avalanchego-linux-arm64-.tar.gz`\
Unzip: `tar -xvf avalanchego-linux-arm64-.tar.gz`\
The resulting folder, `avalanchego--linux`, contains the binaries.
You are now ready to run the new version of the node.
### Running the Node from Terminal[](#running-the-node-from-terminal "Direct link to heading")
If you are using the pre-built binaries on MacOS:
```bash
./avalanchego-/build/avalanchego
```
If you are using the pre-built binaries on Linux:
```bash
./avalanchego--linux/avalanchego
```
Add `nohup` at the start of the command if you want to run the node in the background.
### Running the Node as a Service[](#running-the-node-as-a-service "Direct link to heading")
If you're running the node as a service, you need to replace the old binaries with the new ones.
```bash
cp -r avalanchego--linux/*
```
and then restart the service with: `sudo systemctl start avalanchego.service`.
## Build from Source[](#build-from-source "Direct link to heading")
First clone our GitHub repo (you can skip this step if you've done this before):
```bash
git clone https://github.com/ava-labs/avalanchego.git
```
The repository cloning method used is HTTPS, but SSH can be used too:
`git clone git@github.com:ava-labs/avalanchego.git`
You can find more about SSH and how to use it [here](https://docs.github.com/en/authentication/connecting-to-github-with-ssh/about-ssh).
Then move to the AvalancheGo directory:
```bash
cd avalanchego
```
Pull the latest code:
```bash
git pull
```
If the master branch has not been updated with the latest release tag, you can get to it directly via first running `git fetch --all --tags` and then `git checkout --force tags/` (where `` is the latest release tag; for example `v1.3.2`) instead of `git pull`.
Note that your local copy will be in a 'detached HEAD' state, which is not an issue if you do not make changes to the source that you want push back to the repository (in which case you should check out to a branch and to the ordinary merges).
Note also that the `--force` flag will disregard any local changes you might have.
Check that your local code is up to date. Do:
```bash
git rev-parse HEAD
```
and check that the first 7 characters printed match the Latest commit field on our [GitHub](https://github.com/ava-labs/avalanchego).
If you used the `git checkout tags/` then these first 7 characters should match commit hash of that tag.
Now build the binary:
```bash
./scripts/build.sh
```
This should print: `Build Successful`
You can check what version you're running by doing:
```bash
./build/avalanchego --version
```
You can run your node with:
```bash
./build/avalanchego
```
# Amazon Web Services
URL: /docs/nodes/on-third-party-services/amazon-web-services
Learn how to run a node on Amazon Web Services.
## Introduction[](#introduction "Direct link to heading")
This tutorial will guide you through setting up an Avalanche node on [Amazon Web Services (AWS)](https://aws.amazon.com/). Cloud services like AWS are a good way to ensure that your node is highly secure, available, and accessible.
To get started, you'll need:
* An AWS account
* A terminal with which to SSH into your AWS machine
* A place to securely store and back up files
This tutorial assumes your local machine has a Unix style terminal. If you're on Windows, you'll have to adapt some of the commands used here.
## Log Into AWS[](#log-into-aws "Direct link to heading")
Signing up for AWS is outside the scope of this article, but Amazon has instructions [here](https://aws.amazon.com/premiumsupport/knowledge-center/create-and-activate-aws-account).
It is *highly* recommended that you set up Multi-Factor Authentication on your AWS root user account to protect it. Amazon has documentation for this [here](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_credentials_mfa_enable_virtual.html#enable-virt-mfa-for-root).
Once your account is set up, you should create a new EC2 instance. An EC2 is a virtual machine instance in AWS's cloud. Go to the [AWS Management Console](https://console.aws.amazon.com/) and enter the EC2 dashboard.
To log into the EC2 instance, you will need a key on your local machine that grants access to the instance. First, create that key so that it can be assigned to the EC2 instance later on. On the bar on the left side, under **Network & Security**, select **Key Pairs.**
Select **Create key pair** to launch the key pair creation wizard.
Name your key `avalanche`. If your local machine has MacOS or Linux, select the `pem` file format. If it's Windows, use the `ppk` file format. Optionally, you can add tags for the key pair to assist with tracking.
Click `Create key pair`. You should see a success message, and the key file should be downloaded to your local machine. Without this file, you will not be able to access your EC2 instance. **Make a copy of this file and put it on a separate storage medium such as an external hard drive. Keep this file secret; do not share it with others.**
## Create a Security Group[](#create-a-security-group "Direct link to heading")
An AWS Security Group defines what internet traffic can enter and leave your EC2 instance. Think of it like a firewall. Create a new Security Group by selecting **Security Groups** under the **Network & Security** drop-down.
This opens the Security Groups panel. Click **Create security group** in the top right of the Security Groups panel.
You'll need to specify what inbound traffic is allowed. Allow SSH traffic from your IP address so that you can log into your EC2 instance (each time your ISP changes your IP address, you will need to modify this rule). Allow TCP traffic on port 9651 so your node can communicate with other nodes on the network. Allow TCP traffic on port 9650 from your IP so you can make API calls to your node. **It's important that you only allow traffic on the SSH and API port from your IP.** If you allow incoming traffic from anywhere, this could be used to brute force entry to your node (SSH port) or used as a denial of service attack vector (API port). Finally, allow all outbound traffic.
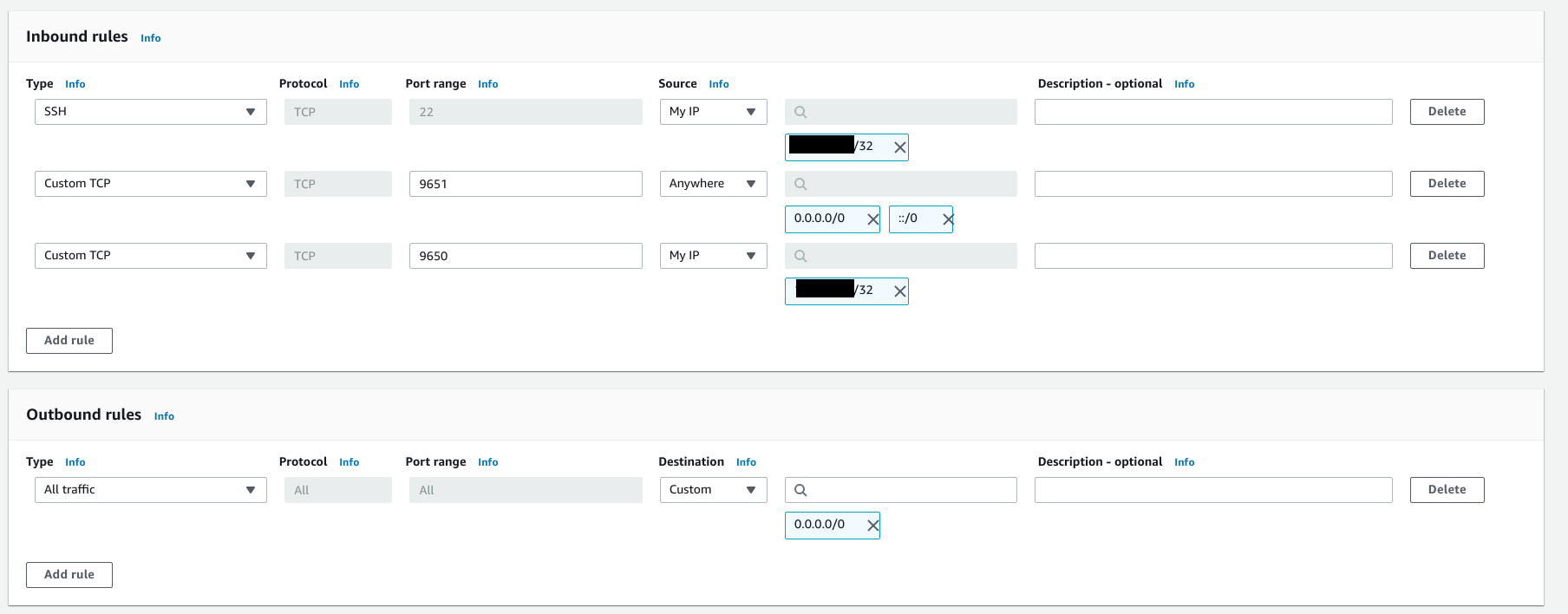
Add a tag to the new security group with key `Name` and value`Avalanche Security Group`. This will enable us to know what this security group is when we see it in the list of security groups.
Click `Create security group`. You should see the new security group in the list of security groups.
## Launch an EC2 Instance[](#launch-an-ec2-instance "Direct link to heading")
Now you're ready to launch an EC2 instance. Go to the EC2 Dashboard and select **Launch instance**.
Select **Ubuntu 20.04 LTS (HVM), SSD Volume Type** for the operating system.
Next, choose your instance type. This defines the hardware specifications of the cloud instance. In this tutorial we set up a **c5.2xlarge**. This should be more than powerful enough since Avalanche is a lightweight consensus protocol. To create a c5.2xlarge instance, select the **Compute-optimized** option from the filter drop-down menu.
Select the checkbox next to the c5.2xlarge instance in the table.

Click the **Next: Configure Instance Details** button in the bottom right-hand corner.
The instance details can stay as their defaults.
When setting up a node as a validator, it is crucial to select the appropriate AWS instance type to ensure the node can efficiently process transactions and manage the network load. The recommended instance types are as follows:
* For a minimal stake, start with a compute-optimized instance such as c6, c6i, c6a, c7 and similar.
* Use a 2xlarge instance size for the minimal stake configuration.
* As the staked amount increases, choose larger instance sizes to accommodate the additional workload. For every order of magnitude increase in stake, move up one instance size. For example, for a 20k AVAX stake, a 4xlarge instance is suitable.
### Optional: Using Reserved Instances[](#optional-using-reserved-instances "Direct link to heading")
By default, you will be charged hourly for running your EC2 instance. For a long term usage that is not optimal.
You could save money by using a **Reserved Instance**. With a reserved instance, you pay upfront for an entire year of EC2 usage, and receive a lower per-hour rate in exchange for locking in. If you intend to run a node for a long time and don't want to risk service interruptions, this is a good option to save money. Again, do your own research before selecting this option.
### Add Storage, Tags, Security Group[](#add-storage-tags-security-group "Direct link to heading")
Click the **Next: Add Storage** button in the bottom right corner of the screen.
You need to add space to your instance's disk. You should start with at least 700GB of disk space. Although upgrades to reduce disk usage are always in development, on average the database will continually grow, so you need to constantly monitor disk usage on the node and increase disk space if needed.
Note that the image below shows 100GB as disk size, which was appropriate at the time the screenshot was taken. You should check the current [recommended disk space size](https://github.com/ava-labs/avalanchego#installation) before entering the actual value here.

Click **Next: Add Tags** in the bottom right corner of the screen to add tags to the instance. Tags enable us to associate metadata with our instance. Add a tag with key `Name` and value `My Avalanche Node`. This will make it clear what this instance is on your list of EC2 instances.
Now assign the security group created earlier to the instance. Choose **Select an existing security group** and choose the security group created earlier.
Finally, click **Review and Launch** in the bottom right. A review page will show the details of the instance you're about to launch. Review those, and if all looks good, click the blue **Launch** button in the bottom right corner of the screen.
You'll be asked to select a key pair for this instance. Select **Choose an existing key pair** and then select the `avalanche` key pair you made earlier in the tutorial. Check the box acknowledging that you have access to the `.pem` or `.ppk` file created earlier (make sure you've backed it up!) and then click **Launch Instances**.
You should see a new pop up that confirms the instance is launching!
### Assign an Elastic IP[](#assign-an-elastic-ip "Direct link to heading")
By default, your instance will not have a fixed IP. Let's give it a fixed IP through AWS's Elastic IP service. Go back to the EC2 dashboard. Under **Network & Security,** select **Elastic IPs**.
Select **Allocate Elastic IP address**.
Select the region your instance is running in, and choose to use Amazon's pool of IPv4 addresses. Click **Allocate**.
Select the Elastic IP you just created from the Elastic IP manager. From the **Actions** drop-down, choose **Associate Elastic IP address**.
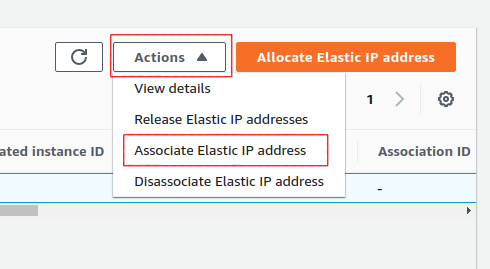
Select the instance you just created. This will associate the new Elastic IP with the instance and give it a public IP address that won't change.
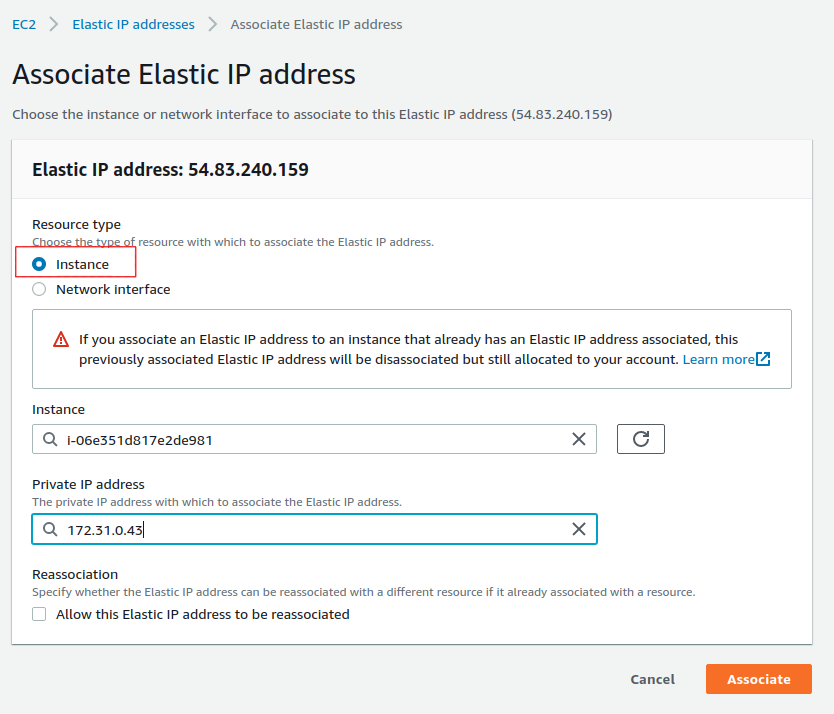
## Set Up AvalancheGo[](#set-up-avalanchego "Direct link to heading")
Go back to the EC2 Dashboard and select `Running Instances`.
Select the newly created EC2 instance. This opens a details panel with information about the instance.
Copy the `IPv4 Public IP` field to use later. From now on we call this value `PUBLICIP`.
**Remember: the terminal commands below assume you're running Linux. Commands may differ for MacOS or other operating systems. When copy-pasting a command from a code block, copy and paste the entirety of the text in the block.**
Log into the AWS instance from your local machine. Open a terminal (try shortcut `CTRL + ALT + T`) and navigate to the directory containing the `.pem` file you downloaded earlier.
Move the `.pem` file to `$HOME/.ssh` (where `.pem` files generally live) with:
Add it to the SSH agent so that we can use it to SSH into your EC2 instance, and mark it as read-only.
```bash
ssh-add ~/.ssh/avalanche.pem; chmod 400 ~/.ssh/avalanche.pem
```
SSH into the instance. (Remember to replace `PUBLICIP` with the public IP field from earlier.)
If the permissions are **not** set correctly, you will see the following error.
You are now logged into the EC2 instance.
If you have not already done so, update the instance to make sure it has the latest operating system and security updates:
```bash
sudo apt update; sudo apt upgrade -y; sudo reboot
```
This also reboots the instance. Wait 5 minutes, then log in again by running this command on your local machine:
You're logged into the EC2 instance again. Now we'll need to set up our Avalanche node. To do this, follow the [Set Up Avalanche Node With Installer](/docs/nodes/using-install-script/installing-avalanche-go) tutorial which automates the installation process. You will need the `PUBLICIP` we set up earlier.
Your AvalancheGo node should now be running and in the process of bootstrapping, which can take a few hours. To check if it's done, you can issue an API call using `curl`. If you're making the request from the EC2 instance, the request is:
```bash
curl -X POST --data '{
"jsonrpc":"2.0",
"id" :1,
"method" :"info.isBootstrapped",
"params": {
"chain":"X"
}
}' -H 'content-type:application/json;' 127.0.0.1:9650/ext/info
```
Once the node is finished bootstrapping, the response will be:
```json
{
"jsonrpc": "2.0",
"result": {
"isBootstrapped": true
},
"id": 1
}
```
You can continue on, even if AvalancheGo isn't done bootstrapping.
In order to make your node a validator, you'll need its node ID. To get it, run:
```bash
curl -X POST --data '{
"jsonrpc":"2.0",
"id" :1,
"method" :"info.getNodeID"
}' -H 'content-type:application/json;' 127.0.0.1:9650/ext/info
```
The response contains the node ID.
```json
{"jsonrpc":"2.0","result":{"nodeID":"NodeID-DznHmm3o7RkmpLkWMn9NqafH66mqunXbM"},"id":1}
```
In the above example the node ID is`NodeID-DznHmm3o7RkmpLkWMn9NqafH66mqunXbM`. Copy your node ID for later. Your node ID is not a secret, so you can just paste it into a text editor.
AvalancheGo has other APIs, such as the [Health API](/docs/api-reference/health-api), that may be used to interact with the node. Some APIs are disabled by default. To enable such APIs, modify the ExecStart section of `/etc/systemd/system/avalanchego.service` (created during the installation process) to include flags that enable these endpoints. Don't manually enable any APIs unless you have a reason to.
Back up the node's staking key and certificate in case the EC2 instance is corrupted or otherwise unavailable. The node's ID is derived from its staking key and certificate. If you lose your staking key or certificate then your node will get a new node ID, which could cause you to become ineligible for a staking reward if your node is a validator. **It is very strongly advised that you copy your node's staking key and certificate**. The first time you run a node, it will generate a new staking key/certificate pair and store them in directory `/home/ubuntu/.avalanchego/staking`.
Exit out of the SSH instance by running:
Now you're no longer connected to the EC2 instance; you're back on your local machine.
To copy the staking key and certificate to your machine, run the following command. As always, replace `PUBLICIP`.
```bash
scp -r ubuntu@PUBLICIP:/home/ubuntu/.avalanchego/staking ~/aws_avalanche_backup
```
Now your staking key and certificate are in directory `~/aws_avalanche_backup` . **The contents of this directory are secret.** You should hold this directory on storage not connected to the internet (like an external hard drive.)
### Upgrading Your Node[](#upgrading-your-node "Direct link to heading")
AvalancheGo is an ongoing project and there are regular version upgrades. Most upgrades are recommended but not required. Advance notice will be given for upgrades that are not backwards compatible. To update your node to the latest version, SSH into your AWS instance as before and run the installer script again.
```bash
./avalanchego-installer.sh
```
Your machine is now running the newest AvalancheGo version. To see the status of the AvalancheGo service, run `sudo systemctl status avalanchego.`
## Increase Volume Size[](#increase-volume-size "Direct link to heading")
If you need to increase the volume size, follow these instructions from AWS:
* [Request modifications to your EBS volumes](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/requesting-ebs-volume-modifications.html)
* [Extend a Linux file system after resizing a volume](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/recognize-expanded-volume-linux.html)
## Wrap Up[](#wrap-up "Direct link to heading")
That's it! You now have an AvalancheGo node running on an AWS EC2 instance. We recommend setting up [node monitoring](/docs/nodes/maintain/monitoring)for your AvalancheGo node. We also recommend setting up AWS billing alerts so you're not surprised when the bill arrives. If you have feedback on this tutorial, or anything else, send us a message on [Discord](https://chat.avalabs.org/).
# AWS Marketplace
URL: /docs/nodes/on-third-party-services/aws-marketplace
Learn how to run a node on AWS Marketplace.
## How to Launch an Avalanche Validator using AWS
With the intention of enabling developers and entrepreneurs to on-ramp into the Avalanche ecosystem with as little friction as possible, Ava Labs recently launched an offering to deploy an Avalanche Validator node via the AWS Marketplace. This tutorial will show the main steps required to get this node running and validating on the Avalanche Fuji testnet.
## Product Overview[](#product-overview "Direct link to heading")
The Avalanche Validator node is available via [the AWS Marketplace](https://aws.amazon.com/marketplace/pp/prodview-nd6wgi2bhhslg). There you'll find a high level product overview. This includes a product description, pricing information, usage instructions, support information and customer reviews. After reviewing this information you want to click the "Continue to Subscribe" button.
## Subscribe to This Software[](#subscribe-to-this-software "Direct link to heading")
Once on the "Subscribe to this Software" page you will see a button which enables you to subscribe to this AWS Marketplace offering. In addition you'll see Terms of service including the seller's End User License Agreement and the [AWS Privacy Notice](https://aws.amazon.com/privacy/). After reviewing these you want to click on the "Continue to Configuration" button.
## Configure This Software[](#configure-this-software "Direct link to heading")
This page lets you choose a fulfillment option and software version to launch this software. No changes are needed as the default settings are sufficient. Leave the `Fulfillment Option` as `64-bit (x86) Amazon Machine Image (AMI)`. The software version is the latest build of [the AvalancheGo full node](https://github.com/ava-labs/avalanchego/releases), `v1.9.5 (Dec 22, 2022)`, AKA `Banff.5`. This will always show the latest version. Also, the Region to deploy in can be left as `US East (N. Virginia)`. On the right you'll see the software and infrastructure pricing. Lastly, click the "Continue to Launch" button.
## Launch This Software[](#launch-this-software "Direct link to heading")
Here you can review the launch configuration details and follow the instructions to launch the Avalanche Validator Node. The changes are very minor. Leave the action as "Launch from Website." The EC2 Instance Type should remain `c5.2xlarge`. The primary change you'll need to make is to choose a keypair which will enable you to `ssh` into the newly created EC2 instance to run `curl` commands on the Validator node. You can search for existing Keypairs or you can create a new keypair and download it to your local machine. If you create a new keypair you'll need to move the keypair to the appropriate location, change the permissions and add it to the OpenSSH authentication agent. For example, on MacOS it would look similar to the following:
```bash
# In this example we have a keypair called avalanche.pem which was downloaded from AWS to ~/Downloads/avalanche.pem
# Confirm the file exists with the following command
test -f ~/Downloads/avalanche.pem && echo "Avalanche.pem exists."
# Running the above command will output the following:
# Avalanche.pem exists.
# Move the avalanche.pem keypair from the ~/Downloads directory to the hidden ~/.ssh directory
mv ~/Downloads/avalanche.pem ~/.ssh
# Next add the private key identity to the OpenSSH authentication agent
ssh-add ~/.ssh/avalanche.pem;
# Change file modes or Access Control Lists
sudo chmod 600 ~/.ssh/avalanche.pem
```
Once these steps are complete you are ready to launch the Validator node on EC2. To make that happen click the "Launch" button

You now have an Avalanche node deployed on an AWS EC2 instance! Copy the `AMI ID` and click on the `EC2 Console` link for the next step.
## EC2 Console[](#ec2-console "Direct link to heading")
Now take the `AMI ID` from the previous step and input it into the search bar on the EC2 Console. This will bring you to the dashboard where you can find the EC2 instances public IP address.
Copy that public IP address and open a Terminal or command line prompt. Once you have the new Terminal open `ssh` into the EC2 instance with the following command.
## Node Configuration[](#node-configuration "Direct link to heading")
### Switch to Fuji Testnet[](#switch-to-fuji-testnet "Direct link to heading")
By default the Avalanche Node available through the AWS Marketplace syncs the Mainnet. If this is what you are looking for, you can skip this step.
For this tutorial you want to sync and validate the Fuji Testnet. Now that you're `ssh`ed into the EC2 instance you can make the required changes to sync Fuji instead of Mainnet.
First, confirm that the node is syncing the Mainnet by running the `info.getNetworkID` command.
#### `info.getNetworkID` Request[](#infogetnetworkid-request "Direct link to heading")
```bash
curl -X POST --data '{
"jsonrpc":"2.0",
"id" :1,
"method" :"info.getNetworkID",
"params": {
}
}' -H 'content-type:application/json;' 127.0.0.1:9650/ext/info
```
#### `info.getNetworkID` Response[](#infogetnetworkid-response "Direct link to heading")
The returned `networkID` will be 1 which is the network ID for Mainnet.
```json
{
"jsonrpc": "2.0",
"result": {
"networkID": "1"
},
"id": 1
}
```
Now you want to edit `/etc/avalanchego/conf.json` and change the `"network-id"` property from `"mainnet"` to `"fuji"`. To see the contents of `/etc/avalanchego/conf.json` you can `cat` the file.
```bash
cat /etc/avalanchego/conf.json
{
"api-keystore-enabled": false,
"http-host": "0.0.0.0",
"log-dir": "/var/log/avalanchego",
"db-dir": "/data/avalanchego",
"api-admin-enabled": false,
"public-ip-resolution-service": "opendns",
"network-id": "mainnet"
}
```
Edit that `/etc/avalanchego/conf.json` with your favorite text editor and change the value of the `"network-id"` property from `"mainnet"` to `"fuji"`. Once that's complete, save the file and restart the Avalanche node via `sudo systemctl restart avalanchego`. You can then call the `info.getNetworkID` endpoint to confirm the change was successful.
#### `info.getNetworkID` Request[](#infogetnetworkid-request-1 "Direct link to heading")
```bash
curl -X POST --data '{
"jsonrpc":"2.0",
"id" :1,
"method" :"info.getNetworkID",
"params": {
}
}' -H 'content-type:application/json;' 127.0.0.1:9650/ext/info
```
#### `info.getNetworkID` Response[](#infogetnetworkid-response-1 "Direct link to heading")
The returned `networkID` will be 5 which is the network ID for Fuji.
```json
{
"jsonrpc": "2.0",
"result": {
"networkID": "5"
},
"id": 1
}
```
Next you run the `info.isBoostrapped` command to confirm if the Avalanche Validator node has finished bootstrapping.
### `info.isBootstrapped` Request[](#infoisbootstrapped-request "Direct link to heading")
```bash
curl -X POST --data '{
"jsonrpc":"2.0",
"id" :1,
"method" :"info.isBootstrapped",
"params": {
"chain":"P"
}
}' -H 'content-type:application/json;' 127.0.0.1:9650/ext/info
```
Once the node is finished bootstrapping, the response will be:
### `info.isBootstrapped` Response[](#infoisbootstrapped-response "Direct link to heading")
```json
{
"jsonrpc": "2.0",
"result": {
"isBootstrapped": true
},
"id": 1
}
```
**Note** that initially the response is `false` because the network is still syncing.\
When you're adding your node as a Validator on the Avalanche Mainnet you'll want to wait for this response to return `true` so that you don't suffer from any downtime while validating. For this tutorial you're not going to wait for it to finish syncing as it's not strictly necessary.
### `info.getNodeID` Request[](#infogetnodeid-request "Direct link to heading")
Next, you want to get the NodeID which will be used to add the node as a Validator. To get the node's ID you call the `info.getNodeID` jsonrpc endpoint.
```bash
curl --location --request POST 'http://127.0.0.1:9650/ext/info' \
--header 'Content-Type: application/json' \
--data-raw '{
"jsonrpc":"2.0",
"id" :1,
"method" :"info.getNodeID",
"params" :{
}
}'
```
### `info.getNodeID` Response[](#infogetnodeid-response "Direct link to heading")
Take a note of the `nodeID` value which is returned as you'll need to use it in the next step when adding a validator via the Avalanche Web Wallet. In this case the `nodeID` is `NodeID-Q8Gfaaio9FAqCmZVEXDq9bFvNPvDi7rt5`
```json
{
"jsonrpc": "2.0",
"result": {
"nodeID": "NodeID-Q8Gfaaio9FAqCmZVEXDq9bFvNPvDi7rt5",
"nodePOP": {
"publicKey": "0x85675db18b326a9585bfd43892b25b71bf01b18587dc5fac136dc5343a9e8892cd6c49b0615ce928d53ff5dc7fd8945d",
"proofOfPossession": "0x98a56f092830161243c1f1a613ad68a7f1fb25d2462ecf85065f22eaebb4e93a60e9e29649a32252392365d8f628b2571174f520331ee0063a94473f8db6888fc3a722be330d5c51e67d0d1075549cb55376e1f21d1b48f859ef807b978f65d9"
}
},
"id": 1
}
```
## Add Node as Validator on Fuji via Core web[](#add-node-as-validator-on-fuji-via-core-web "Direct link to heading")
For adding the new node as a Validator on the Fuji testnet's Primary Network you can use the [Core web](https://core.app/) [connected](https://support.avax.network/en/articles/6639869-core-web-how-do-i-connect-to-core-web) to [Core extension](https://core.app). If you don't have a Core extension already, check out this [guide](https://support.avax.network/en/articles/6100129-core-extension-how-do-i-create-a-new-wallet). If you'd like to import an existing wallet to Core extension, follow [these steps](https://support.avax.network/en/articles/6078933-core-extension-how-do-i-access-my-existing-account).
Core web is a free, all-in-one command center that gives users a more intuitive and comprehensive way to view assets, and use dApps across the Avalanche network, its various Avalanche L1s, and Ethereum. Core web is optimized for use with the Core browser extension and Core mobile (available on both iOS & Android). Together, they are key components of the Core product suite that brings dApps, NFTs, Avalanche Bridge, Avalanche L1s, L2s, and more, directly to users.
### Switching to Testnet Mode[](#switching-to-testnet-mode "Direct link to heading")
By default, Core web and Core extension are connected to Mainnet. For the sake of this demo, you want to connect to the Fuji Testnet.
#### On Core Extension[](#on-core-extension "Direct link to heading")
From the hamburger menu on the top-left corner, choose Advanced, and then toggle the Testnet Mode on.
You can follow the same steps for switching back to Mainnet.
#### On Core web[](#on-core-web "Direct link to heading")
Click on the Settings button top-right corner of the page, then toggle Testnet Mode on.
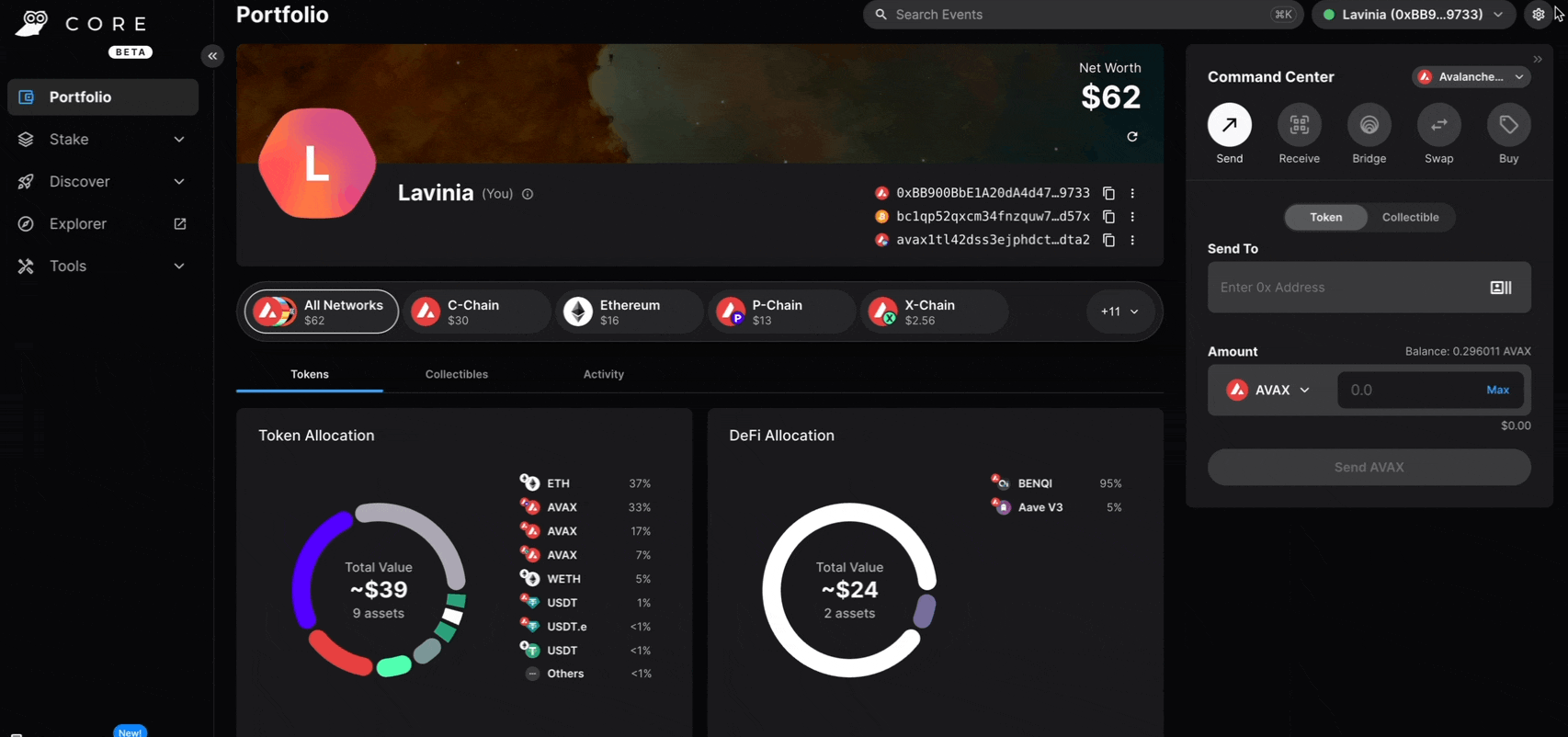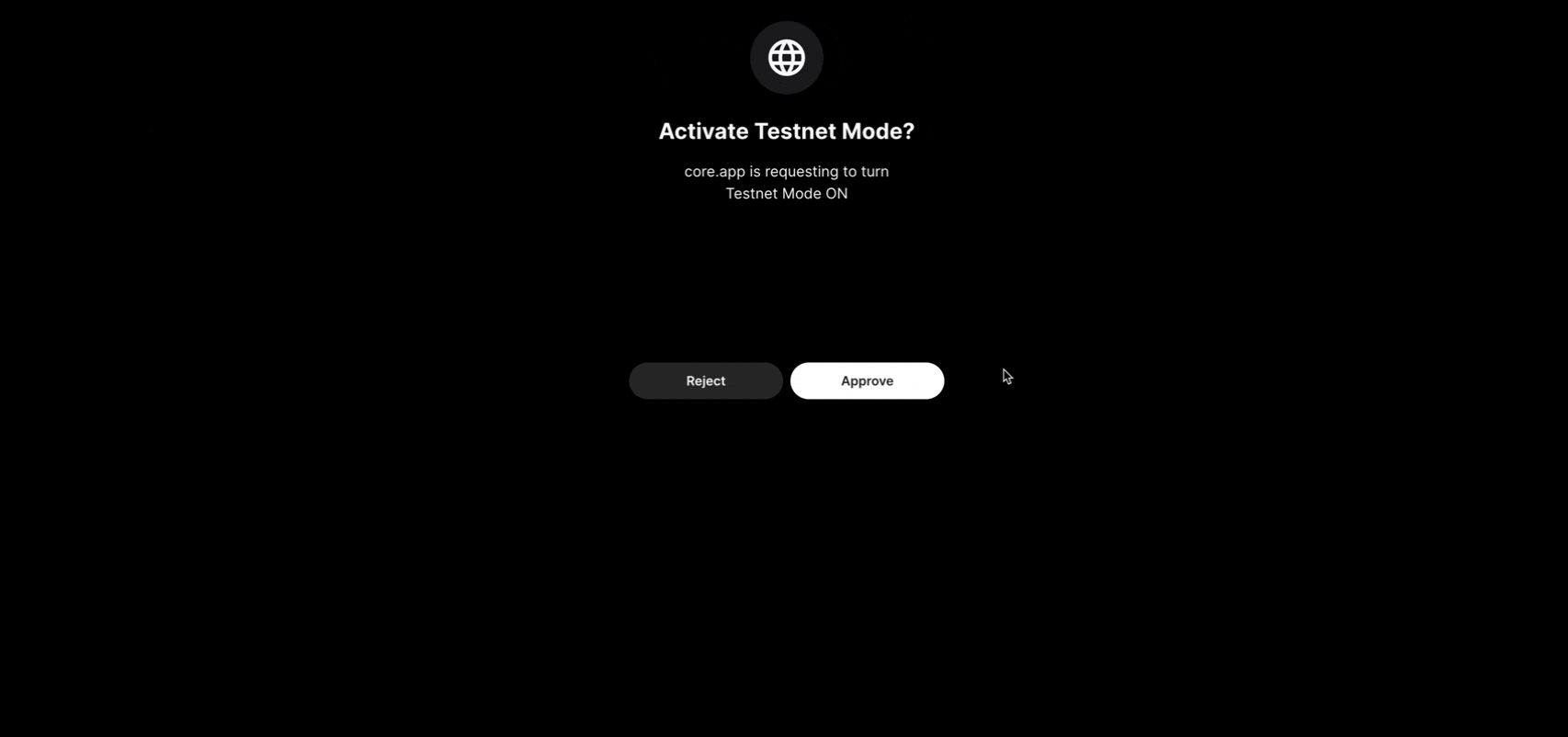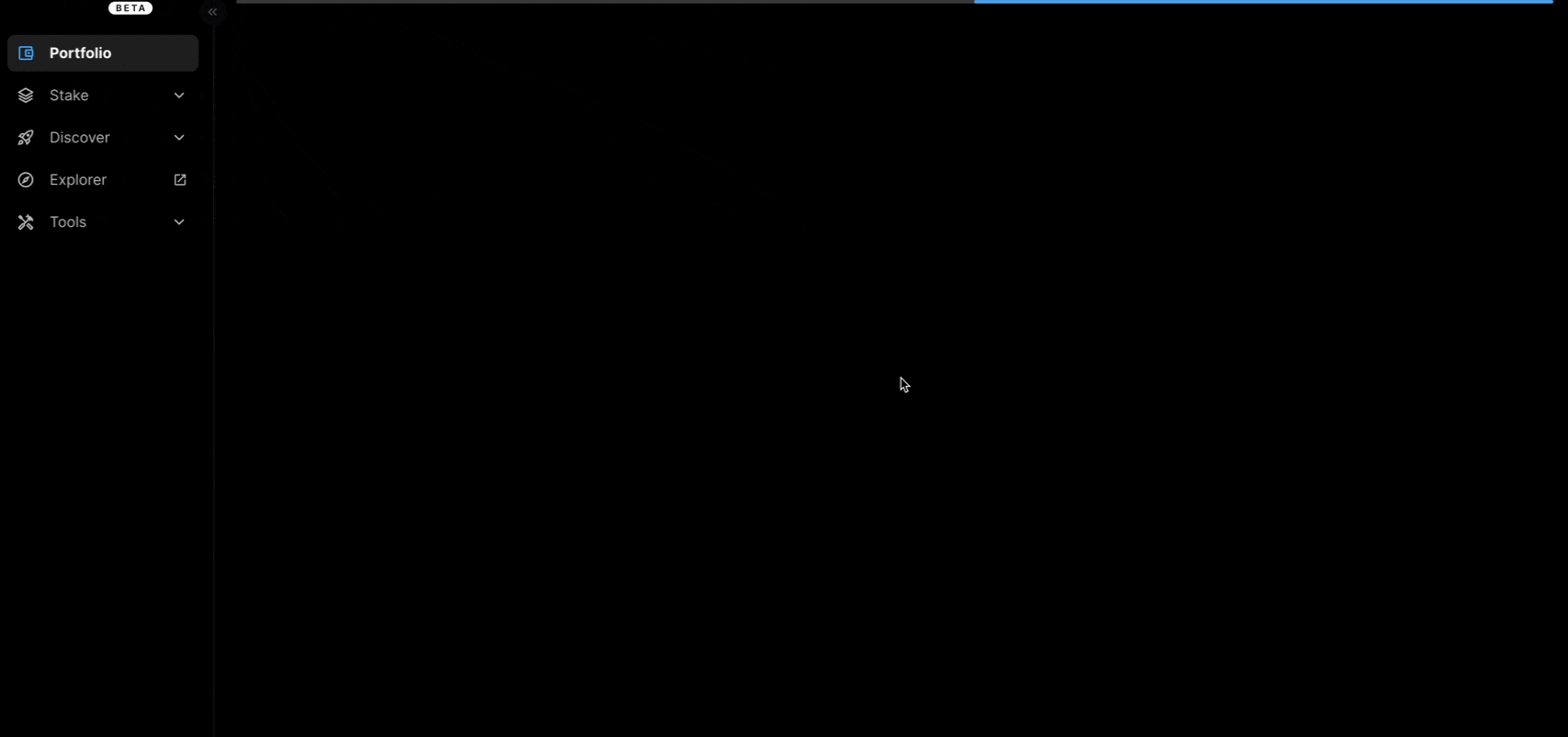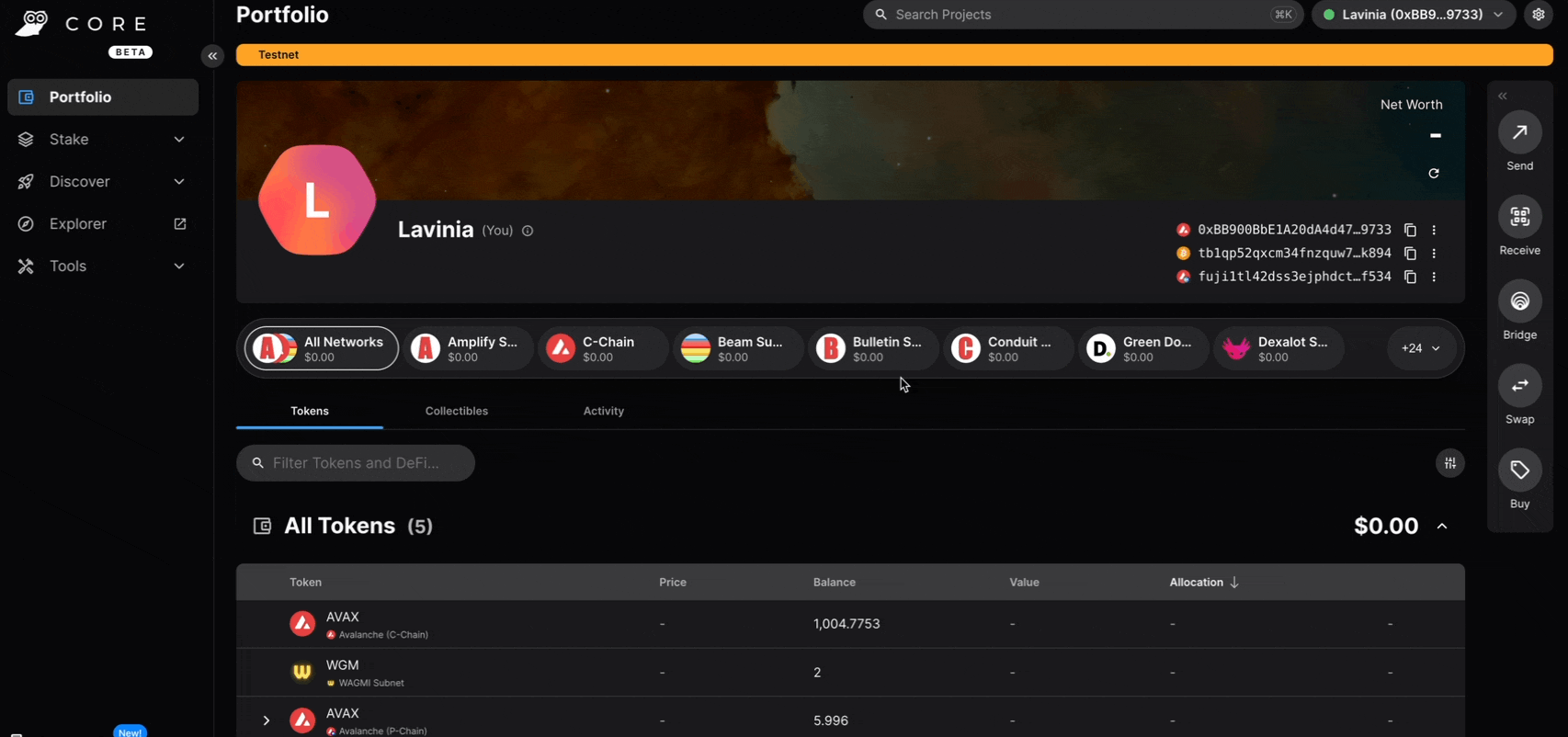
You can follow the same steps for switching back to Mainnet.
### Adding the Validator[](#adding-the-validator "Direct link to heading")
* Node ID: A unique ID derived from each individual node's staker certificate. Use the `NodeID` which was returned in the `info.getNodeID` response. In this example it's `NodeID-Q8Gfaaio9FAqCmZVEXDq9bFvNPvDi7rt5`
* Staking End Date: Your AVAX tokens will be locked until this date.
* Stake Amount: The amount of AVAX to lock for staking. On Mainnet, the minimum required amount is 2,000 AVAX. On Testnet the minimum required amount is 1 AVAAX.
* Delegation Fee: You will claim this % of the rewards from the delegators on your node.
* Reward Address: A reward address is the destination address of the accumulated staking rewards.
To add a node as a Validator, first select the Stake tab on Core web, in the left hand nav menu. Next click the Validate button, and select Get Started.
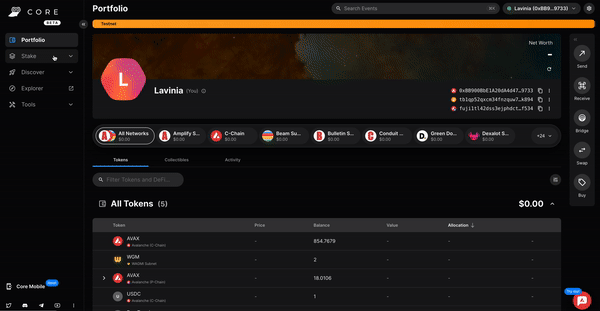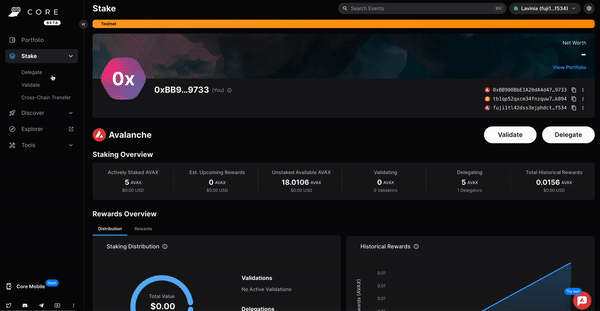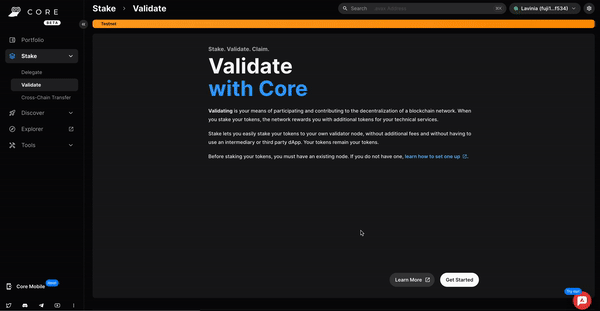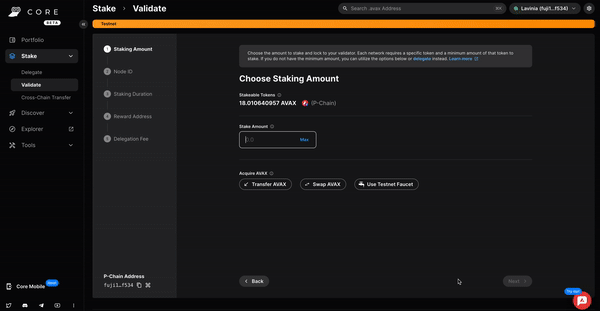
This page will open up.
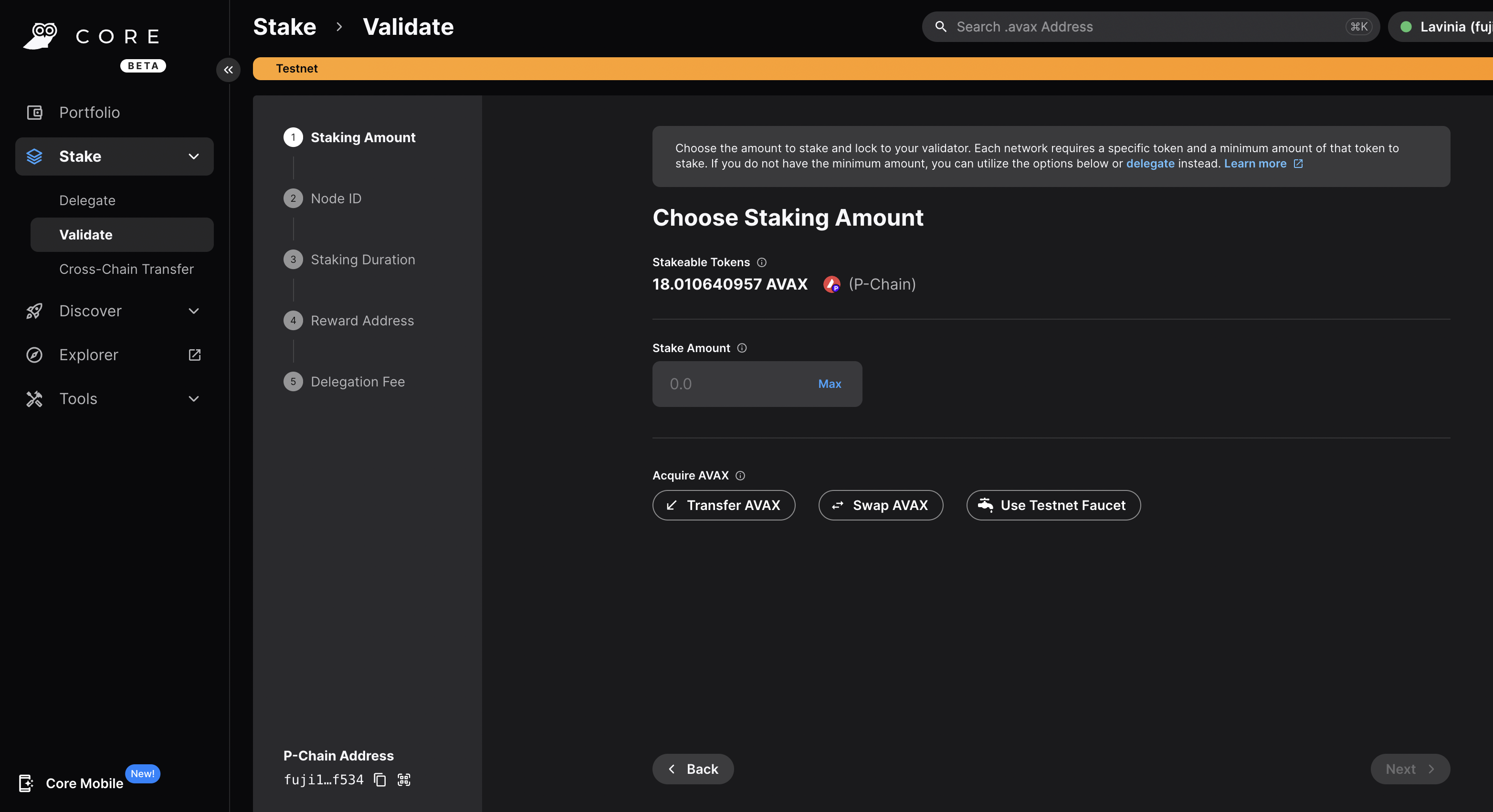
Choose the desired Staking Amount, then click Next.
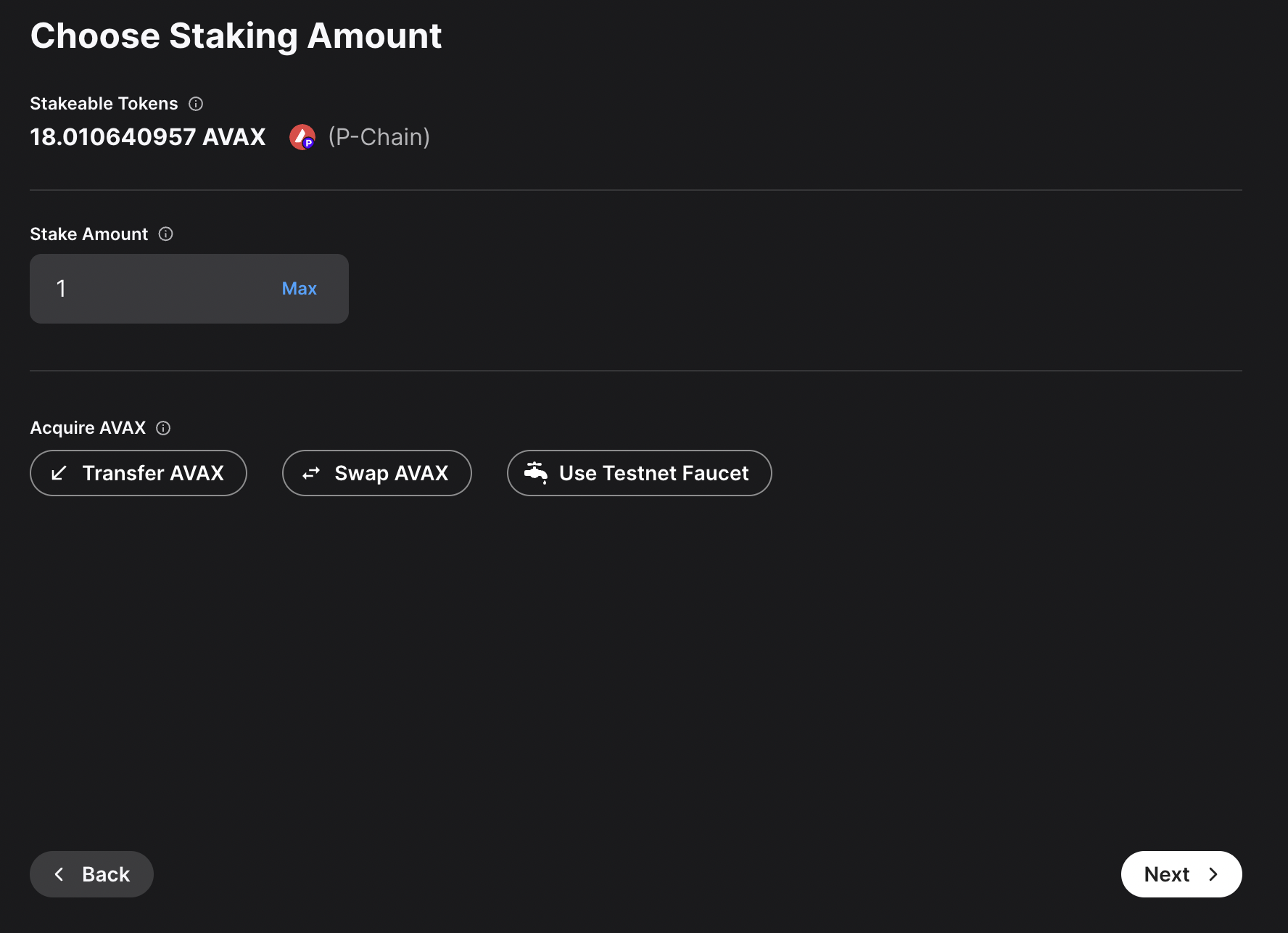
Enter you Node ID, then click Next.
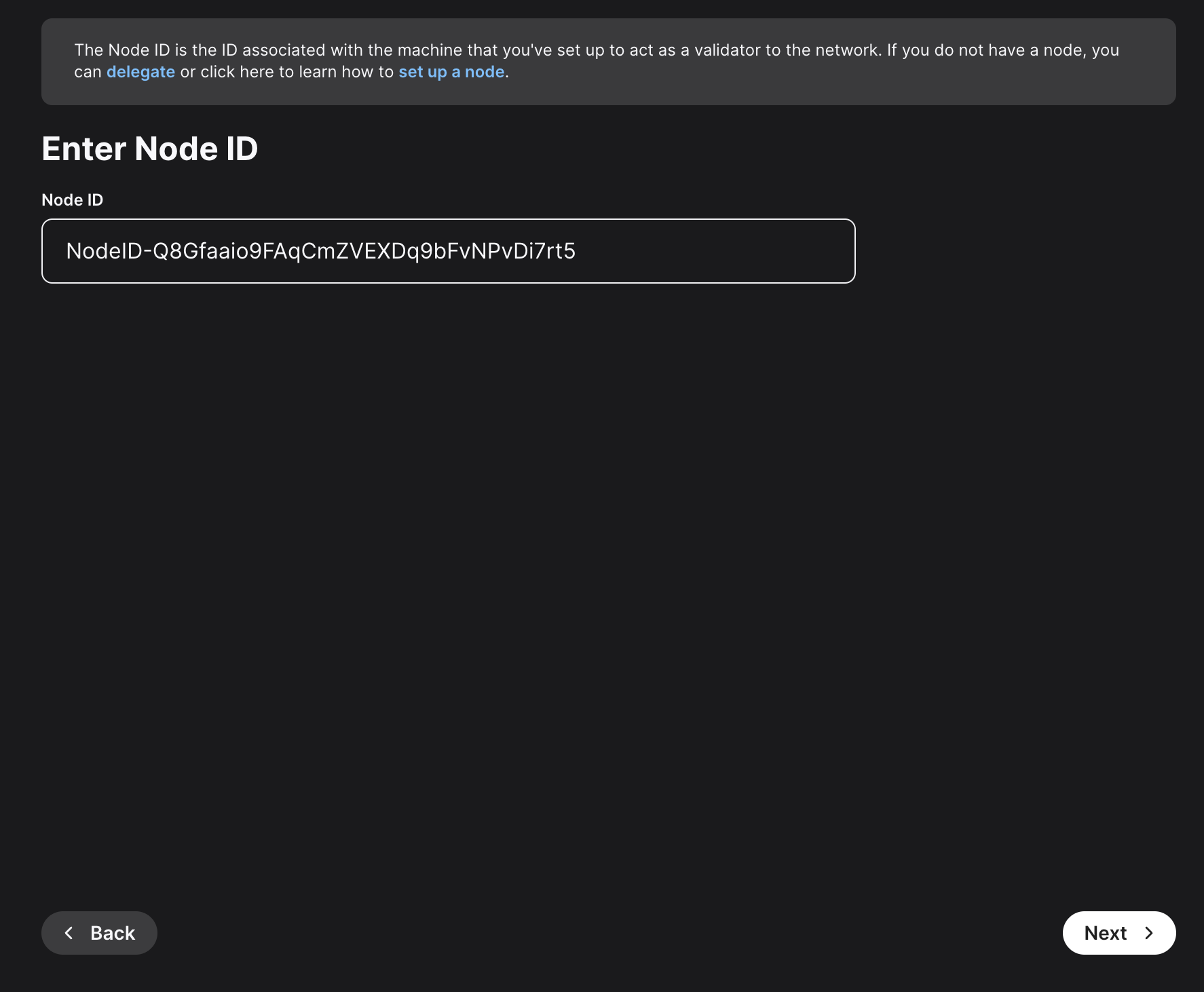
Here, you'll need to choose the staking duration. There are predefined values, like 1 day, 1 month and so on. You can also choose a custom period of time. For this example, 22 days were chosen.
Choose the address that the network will send rewards to. Make sure it's the correct address because once the transaction is submitted this cannot be changed later or undone. You can choose the wallet's P-Chain address, or a custom P-Chain address. After entering the address, click Next.
Other individuals can stake to your validator and receive rewards too, known as "delegating." You will claim this percent of the rewards from the delegators on your node. Click Next.
After entering all these details, a summary of your validation will show up. If everything is correct, you can proceed and click on Submit Validation. A new page will open up, prompting you to accept the transaction. Here, please approve the transaction.
After the transaction is approved, you will see a message saying that your validation transaction was submitted.
If you click on View on explorer, a new browser tab will open with the details of the `AddValidatorTx`. It will show details such as the total value of AVAX transferred, any AVAX which were burned, the blockchainID, the blockID, the NodeID of the validator, and the total time which has elapsed from the entire Validation period.
## Confirm That the Node is a Pending Validator on Fuji[](#confirm-that-the-node-is-a-pending-validator-on-fuji "Direct link to heading")
As a last step you can call the `platform.getPendingvalidators` endpoint to confirm that the Avalanche node which was recently spun up on AWS is no in the pending validators queue where it will stay for 5 minutes.
### `platform.getPendingValidators` Request[](#platformgetpendingvalidators-request "Direct link to heading")
```bash
curl --location --request POST 'https://api.avax-test.network/ext/bc/P' \
--header 'Content-Type: application/json' \
--data-raw '{
"jsonrpc": "2.0",
"method": "platform.getPendingValidators",
"params": {
"subnetID": "11111111111111111111111111111111LpoYY",
"nodeIDs": []
},
"id": 1
}'
```
### `platform.getPendingValidators` Response[](#platformgetpendingvalidators-response "Direct link to heading")
```json
{
"jsonrpc": "2.0",
"result": {
"validators": [
{
"txID": "4d7ZboCrND4FjnyNaF3qyosuGQsNeJ2R4KPJhHJ55VCU1Myjd",
"startTime": "1673411918",
"endTime": "1675313170",
"stakeAmount": "1000000000",
"nodeID": "NodeID-Q8Gfaaio9FAqCmZVEXDq9bFvNPvDi7rt5",
"delegationFee": "2.0000",
"connected": false,
"delegators": null
}
],
"delegators": []
},
"id": 1
}
```
You can also pass in the `NodeID` as a string to the `nodeIDs` array in the request body.
```bash
curl --location --request POST 'https://api.avax-test.network/ext/bc/P' \
--header 'Content-Type: application/json' \
--data-raw '{
"jsonrpc": "2.0",
"method": "platform.getPendingValidators",
"params": {
"subnetID": "11111111111111111111111111111111LpoYY",
"nodeIDs": ["NodeID-Q8Gfaaio9FAqCmZVEXDq9bFvNPvDi7rt5"]
},
"id": 1
}'
```
This will filter the response by the `nodeIDs` array which will save you time by no longer requiring you to search through the entire response body for the NodeIDs.
```json
{
"jsonrpc": "2.0",
"result": {
"validators": [
{
"txID": "4d7ZboCrND4FjnyNaF3qyosuGQsNeJ2R4KPJhHJ55VCU1Myjd",
"startTime": "1673411918",
"endTime": "1675313170",
"stakeAmount": "1000000000",
"nodeID": "NodeID-Q8Gfaaio9FAqCmZVEXDq9bFvNPvDi7rt5",
"delegationFee": "2.0000",
"connected": false,
"delegators": null
}
],
"delegators": []
},
"id": 1
}
```
After 5 minutes the node will officially start validating the Avalanche Fuji testnet and you will no longer see it in the response body for the `platform.getPendingValidators` endpoint. Now you will access it via the `platform.getCurrentValidators` endpoint.
### `platform.getCurrentValidators` Request[](#platformgetcurrentvalidators-request "Direct link to heading")
```bash
curl --location --request POST 'https://api.avax-test.network/ext/bc/P' \
--header 'Content-Type: application/json' \
--data-raw '{
"jsonrpc": "2.0",
"method": "platform.getCurrentValidators",
"params": {
"subnetID": "11111111111111111111111111111111LpoYY",
"nodeIDs": ["NodeID-Q8Gfaaio9FAqCmZVEXDq9bFvNPvDi7rt5"]
},
"id": 1
}'
```
### `platform.getCurrentValidators` Response[](#platformgetcurrentvalidators-response "Direct link to heading")
```json
{
"jsonrpc": "2.0",
"result": {
"validators": [
{
"txID": "2hy57Z7KiZ8L3w2KonJJE1fs5j4JDzVHLjEALAHaXPr6VMeDhk",
"startTime": "1673411918",
"endTime": "1675313170",
"stakeAmount": "1000000000",
"nodeID": "NodeID-Q8Gfaaio9FAqCmZVEXDq9bFvNPvDi7rt5",
"rewardOwner": {
"locktime": "0",
"threshold": "1",
"addresses": [
"P-fuji1tgj2c3k56enytw5d78rt0tsq3lzg8wnftffwk7"
]
},
"validationRewardOwner": {
"locktime": "0",
"threshold": "1",
"addresses": [
"P-fuji1tgj2c3k56enytw5d78rt0tsq3lzg8wnftffwk7"
]
},
"delegationRewardOwner": {
"locktime": "0",
"threshold": "1",
"addresses": [
"P-fuji1tgj2c3k56enytw5d78rt0tsq3lzg8wnftffwk7"
]
},
"potentialReward": "5400963",
"delegationFee": "2.0000",
"uptime": "0.0000",
"connected": false,
"delegators": null
}
]
},
"id": 1
}
```
## Mainnet[](#mainnet "Direct link to heading")
All of these steps can be applied to Mainnet. However, the minimum required Avax token amounts to become a validator is 2,000 on the Mainnet. For more information, please read [this doc](/docs/nodes/validate/how-to-stake#validators).
## Maintenance[](#maintenance "Direct link to heading")
AWS one click is meant to be used in automated environments, not as an end-user solution. You can still manage it manually, but it is not as easy as an Ubuntu instance or using the script:
* AvalancheGo binary is at `/usr/local/bin/avalanchego`
* Main node config is at `/etc/avalanchego/conf.json`
* Working directory is at `/home/avalanche/.avalanchego/ (and belongs to avalanchego user)`
* Database is at `/data/avalanchego`
* Logs are at `/var/log/avalanchego`
For a simple upgrade you would need to place the new binary at `/usr/local/bin/`. If you run an Avalanche L1, you would also need to place the VM binary into `/home/avalanche/.avalanchego/plugins`.
You can also look at using [this guide](https://docs.aws.amazon.com/systems-manager/latest/userguide/automation-tutorial-update-ami.html), but that won't address updating the Avalanche L1, if you have one.
## Summary[](#summary "Direct link to heading")
Avalanche is the first decentralized smart contracts platform built for the scale of global finance, with near-instant transaction finality. Now with an Avalanche Validator node available as a one-click install from the AWS Marketplace developers and entrepreneurs can on-ramp into the Avalanche ecosystem in a matter of minutes. If you have any questions or want to follow up in any way please join our Discord server at [https://chat.avax.network](https://chat.avax.network/). For more developer resources please check out our [Developer Documentation](/docs/).
# Google Cloud
URL: /docs/nodes/on-third-party-services/google-cloud
Learn how to run an Avalanche node on Google Cloud.
This document was written by a community member, some information may be outdated.
## Introduction[](#introduction "Direct link to heading")
Google's Cloud Platform (GCP) is a scalable, trusted and reliable hosting platform. Google operates a significant amount of it's own global networking infrastructure. It's [fiber network](https://cloud.google.com/blog/products/networking/google-cloud-networking-in-depth-cloud-cdn) can provide highly stable and consistent global connectivity. In this article, we will leverage GCP to deploy a node on which Avalanche can installed via [terraform](https://www.terraform.io/). Leveraging `terraform` may seem like overkill, it should set you apart as an operator and administrator as it will enable you greater flexibility and provide the basis on which you can easily build further automation.
## Conventions[](#conventions "Direct link to heading")
* `Items` highlighted in this manor are GCP parlance and can be searched for further reference in the Google documentation for their cloud products.
## Important Notes[](#important-notes "Direct link to heading")
* The machine type used in this documentation is for reference only and the actual sizing you use will depend entirely upon the amount that is staked and delegated to the node.
## Architectural Description[](#architectural-description "Direct link to heading")
This section aims to describe the architecture of the system that the steps in the [Setup Instructions](#-setup-instructions) section deploy when enacted. This is done so that the executor can not only deploy the reference architecture, but also understand and potentially optimize it for their needs.
### Project[](#project "Direct link to heading")
We will create and utilize a single GCP `Project` for deployment of all resources.
#### Service Enablement[](#service-enablement "Direct link to heading")
Within our GCP project we will need to enable the following Cloud Services:
* `Compute Engine`
* `IAP`
### Networking[](#networking "Direct link to heading")
#### Compute Network[](#compute-network "Direct link to heading")
We will deploy a single `Compute Network` object. This unit is where we will deploy all subsequent networking objects. It provides a logical boundary and securitization context should you wish to deploy other chain stacks or other infrastructure in GCP.
#### Public IP[](#public-ip "Direct link to heading")
Avalanche requires that a validator communicate outbound on the same public IP address that it advertises for other peers to connect to it on. Within GCP this precludes the possibility of us using a Cloud NAT Router for the outbound communications and requires us to bind the public IP that we provision to the interface of the machine. We will provision a single `EXTERNAL` static IPv4 `Compute Address`.
#### Avalanche L1s[](#avalanche-l1s "Direct link to heading")
For the purposes of this documentation we will deploy a single `Compute Subnetwork` in the US-EAST1 `Region` with a /24 address range giving us 254 IP addresses (not all usable but for the sake of generalized documentation).
### Compute[](#compute "Direct link to heading")
#### Disk[](#disk "Direct link to heading")
We will provision a single 400GB `PD-SSD` disk that will be attached to our VM.
#### Instance[](#instance "Direct link to heading")
We will deploy a single `Compute Instance` of size `e2-standard-8`. Observations of operations using this machine specification suggest it is memory over provisioned and could be brought down to 16GB using custom machine specification; but please review and adjust as needed (the beauty of compute virtualization!!).
#### Zone[](#zone "Direct link to heading")
We will deploy our instance into the `US-EAST1-B` `Zone`
#### Firewall[](#firewall "Direct link to heading")
We will provision the following `Compute Firewall` rules:
* IAP INGRESS for SSH (TCP 22) - this only allows GCP IAP sources inbound on SSH.
* P2P INGRESS for AVAX Peers (TCP 9651)
These are obviously just default ports and can be tailored to your needs as you desire.
## Setup Instructions[](#-setup-instructions "Direct link to heading")
### GCP Account[](#gcp-account "Direct link to heading")
1. If you don't already have a GCP account go create one [here](https://console.cloud.google.com/freetrial)
You will get some free bucks to run a trial, the trial is feature complete but your usage will start to deplete your free bucks so turn off anything you don't need and/or add a credit card to your account if you intend to run things long term to avoid service shutdowns.
### Project[](#project-1 "Direct link to heading")
Login to the GCP `Cloud Console` and create a new `Project` in your organization. Let's use the name `my-avax-nodes` for the sake of this setup.
1. 
2. 
3. 
### Terraform State[](#terraform-state "Direct link to heading")
Terraform uses a state files to compose a differential between current infrastructure configuration and the proposed plan. You can store this state in a variety of different places, but using GCP storage is a reasonable approach given where we are deploying so we will stick with that.
1. 
2. 
Authentication to GCP from terraform has a few different options which are laid out [here](https://www.terraform.io/language/settings/backends/gcs). Please chose the option that aligns with your context and ensure those steps are completed before continuing.
Depending upon how you intend to execute your terraform operations you may or may not need to enable public access to the bucket. Obviously, not exposing the bucket for `public` access (even if authenticated) is preferable. If you intend to simply run terraform commands from your local machine then you will need to open the access up. I recommend to employ a full CI/CD pipeline using GCP Cloud Build which if utilized will mean the bucket can be marked as `private`. A full walk through of Cloud Build setup in this context can be found [here](https://cloud.google.com/architecture/managing-infrastructure-as-code)
### Clone GitHub Repository[](#clone-github-repository "Direct link to heading")
I have provided a rudimentary terraform construct to provision a node on which to run Avalanche which can be found [here](https://github.com/meaghanfitzgerald/deprecated-avalanche-docs/tree/master/static/scripts). Documentation below assumes you are using this repository but if you have another terraform skeleton similar steps will apply.
### Terraform Configuration[](#terraform-configuration "Direct link to heading")
1. If running terraform locally, please [install](https://learn.hashicorp.com/tutorials/terraform/install-cli) it.
2. In this repository, navigate to the `terraform` directory.
3. Under the `projects` directory, rename the `my-avax-project` directory to match your GCP project name that you created (not required, but nice to be consistent)
4. Under the folder you just renamed locate the `terraform.tfvars` file.
5. Edit this file and populate it with the values which make sense for your context and save it.
6. Locate the `backend.tf` file in the same directory.
7. Edit this file ensuring to replace the `bucket` property with the GCS bucket name that you created earlier.
If you do not with to use cloud storage to persist terraform state then simply switch the `backend` to some other desirable provider.
### Terraform Execution[](#terraform-execution "Direct link to heading")
Terraform enables us to see what it would do if we were to run it without actually applying any changes... this is called a `plan` operation. This plan is then enacted (optionally) by an `apply`.
#### Plan[](#plan "Direct link to heading")
1. In a terminal which is able to execute the `tf` binary, `cd` to the \~`my-avax-project` directory that you renamed in step 3 of `Terraform Configuration`.
2. Execute the command `tf plan`
3. You should see a JSON output to the stdout of the terminal which lays out the operations that terraform will execute to apply the intended state.
#### Apply[](#apply "Direct link to heading")
1. In a terminal which is able to execute the `tf` binary, `cd` to the \~`my-avax-project` directory that you renamed in step 3 of `Terraform Configuration`.
2. Execute the command `tf apply`
If you want to ensure that terraform does **exactly** what you saw in the `apply` output, you can optionally request for the `plan` output to be saved to a file to feed to `apply`. This is generally considered best practice in highly fluid environments where rapid change is occurring from multiple sources.
## Conclusion[](#conclusion "Direct link to heading")
Establishing CI/CD practices using tools such as GitHub and Terraform to manage your infrastructure assets is a great way to ensure base disaster recovery capabilities and to ensure you have a place to embed any \~tweaks you have to make operationally removing the potential to miss them when you have to scale from 1 node to 10. Having an automated pipeline also gives you a place to build a bigger house... what starts as your interest in building and managing a single AVAX node today can quickly change into you building an infrastructure operation for many different chains working with multiple different team members. I hope this may have inspired you to take a leap into automation in this context!
# Latitude
URL: /docs/nodes/on-third-party-services/latitude
Learn how to run an Avalanche node on Latitude.sh.
## Introduction[](#introduction "Direct link to heading")
This tutorial will guide you through setting up an Avalanche node on [Latitude.sh](https://latitude.sh/). Latitude.sh provides high-performance lighting-fast bare metal servers to ensure that your node is highly secure, available, and accessible.
To get started, you'll need:
* A Latitude.sh account
* A terminal with which to SSH into your Latitude.sh machine
For the instructions on creating an account and server with Latitude.sh, please reference their [GitHub tutorial](https://github.com/NottherealIllest/Latitude.sh-post/blob/main/avalanhe/avax-copy.md) , or visit [this page](https://www.latitude.sh/dashboard/signup) to sign up and create your first project.
This tutorial assumes your local machine has a Unix-style terminal. If you're on Windows, you'll have to adapt some of the commands used here.
## Configuring Your Server[](#configuring-your-server "Direct link to heading")
### Create a Latitude.sh Account[](#create-a-latitudesh-account "Direct link to heading")
At this point your account has been verified, and you have created a new project and deployed the server according to the instructions linked above.
### Access Your Server & Further Steps[](#access-your-server--further-steps "Direct link to heading")
All your Latitude.sh credentials are available by clicking the `server` under your project, and can be used to access your Latitude.sh machine from your local machine using a terminal.
You will need to install the `avalanche node installer script` directly in the server's terminal.
After gaining access, we'll need to set up our Avalanche node. To do this, follow the instructions here to install and run your node [Set Up Avalanche Node With Installer](/docs/nodes/using-install-script/installing-avalanche-go).
Your AvalancheGo node should now be running and in the process of bootstrapping, which can take a few hours. To check if it's done, you can issue an API call using `curl`. The request is:
```bash
curl -X POST --data '{
"jsonrpc":"2.0",
"id" :1,
"method" :"info.isBootstrapped",
"params": {
"chain":"X"
}
}' -H 'content-type:application/json;' 127.0.0.1:9650/ext/info
```
Once the node is finished bootstrapping, the response will be:
```json
{
"jsonrpc": "2.0",
"result": {
"isBootstrapped": true
},
"id": 1
}
```
You can continue on, even if AvalancheGo isn't done bootstrapping. In order to make your node a validator, you'll need its node ID. To get it, run:
```bash
curl -X POST --data '{
"jsonrpc": "2.0",
"id": 1,
"method": "info.getNodeID"
}' -H 'content-type:application/json;' 127.0.0.1:9650/ext/info
```
The response contains the node ID.
```json
{
"jsonrpc": "2.0",
"result": { "nodeID": "KhDnAoZDW8iRJ3F26iQgK5xXVFMPcaYeu" },
"id": 1
}
```
In the above example the node ID is `NodeID-KhDnAoZDW8iRJ3F26iQgK5xXVFMPcaYeu`.
AvalancheGo has other APIs, such as the [Health API](/docs/api-reference/health-api), that may be used to interact with the node. Some APIs are disabled by default. To enable such APIs, modify the ExecStart section of `/etc/systemd/system/avalanchego.service` (created during the installation process) to include flags that enable these endpoints. Don't manually enable any APIs unless you have a reason to.
Exit out of the SSH server by running:
### Upgrading Your Node[](#upgrading-your-node "Direct link to heading")
AvalancheGo is an ongoing project and there are regular version upgrades. Most upgrades are recommended but not required. Advance notice will be given for upgrades that are not backwards compatible. To update your node to the latest version, SSH into your server using a terminal and run the installer script again.
```bash
./avalanchego-installer.sh
```
Your machine is now running the newest AvalancheGo version. To see the status of the AvalancheGo service, run `sudo systemctl status avalanchego.`
## Wrap Up[](#wrap-up "Direct link to heading")
That's it! You now have an AvalancheGo node running on a Latitude.sh machine. We recommend setting up [node monitoring](/docs/nodes/maintain/monitoring) for your AvalancheGo node.
# Microsoft Azure
URL: /docs/nodes/on-third-party-services/microsoft-azure
How to run an Avalanche node on Microsoft Azure.
This document was written by a community member, some information may be out of date.
Running a validator and staking with Avalanche provides extremely competitive rewards of between 9.69% and 11.54% depending on the length you stake for. The maximum rate is earned by staking for a year, whilst the lowest rate for 14 days. There is also no slashing, so you don't need to worry about a hardware failure or bug in the client which causes you to lose part or all of your stake. Instead with Avalanche you only need to currently maintain at least 80% uptime to receive rewards. If you fail to meet this requirement you don't get slashed, but you don't receive the rewards. **You also do not need to put your private keys onto a node to begin validating on that node.** Even if someone breaks into your cloud environment and gains access to the node, the worst they can do is turn off the node.
Not only does running a validator node enable you to receive rewards in AVAX, but later you will also be able to validate other Avalanche L1s in the ecosystem as well and receive rewards in the token native to their Avalanche L1s.
Hardware requirements to run a validator are relatively modest: 8 CPU cores, 16 GB of RAM and 1 TB SSD. It also doesn't use enormous amounts of energy. Avalanche's [revolutionary consensus mechanism](/docs/quick-start/avalanche-consensus) is able to scale to millions of validators participating in consensus at once, offering unparalleled decentralisation.
Currently the minimum amount required to stake to become a validator is 2,000 AVAX. Alternatively, validators can also charge a small fee to enable users to delegate their stake with them to help towards running costs.
In this article we will step through the process of configuring a node on Microsoft Azure. This tutorial assumes no prior experience with Microsoft Azure and will go through each step with as few assumptions possible.
At the time of this article, spot pricing for a virtual machine with 2 Cores and 8 GB memory costs as little as 0.01060perhourwhichworksoutatabout0.01060 per hour which works out at about 113.44 a year, **a saving of 83.76%! compared to normal pay as you go prices.** In comparison a virtual machine in AWS with 2 Cores and 4 GB Memory with spot pricing is around \$462 a year.
## Initial Subscription Configuration[](#initial-subscription-configuration "Direct link to heading")
### Set up 2 Factor[](#set-up-2-factor "Direct link to heading")
First you will need a Microsoft Account, if you don't have one already you will see an option to create one at the following link. If you already have one, make sure to set up 2 Factor authentication to secure your node by going to the following link and then selecting "Two-step verification" and following the steps provided.
[https://account.microsoft.com/security](https://account.microsoft.com/security)
Once two factor has been configured log into the Azure portal by going to [https://portal.azure.com](https://portal.azure.com/) and signing in with your Microsoft account. When you login you won't have a subscription, so we need to create one first. Select "Subscriptions" as highlighted below:
Then select "+ Add" to add a new subscription
If you want to use Spot Instance VM Pricing (which will be considerably cheaper) you can't use a Free Trial account (and you will receive an error upon validation), so **make sure to select Pay-As-You-Go.**
Enter your billing details and confirm identity as part of the sign-up process, when you get to Add technical support select the without support option (unless you want to pay extra for support) and press Next.
## Create a Virtual Machine[](#create-a-virtual-machine "Direct link to heading")
Now that we have a subscription, we can create the Ubuntu Virtual Machine for our Avalanche Node. Select the Icon in the top left for the Menu and choose "+ Create a resource"
Select Ubuntu Server 18.04 LTS (this will normally be under the popular section or alternatively search for it in the marketplace)

This will take you to the Create a virtual machine page as shown below:
First, enter a virtual machine a name, this can be anything but in my example, I have called it Avalanche (This will also automatically change the resource group name to match)
Then select a region from the drop-down list. Select one of the recommended ones in a region that you prefer as these tend to be the larger ones with most features enabled and cheaper prices. In this example I have selected North Europe.
You have the option of using spot pricing to save significant amounts on running costs. Spot instances use a supply and demand market price structure. As demand for instances goes up, the price for the spot instance goes up. If there is insufficient capacity, then your VM will be turned off. The chances of this happening are incredibly low though, especially if you select the Capacity only option. Even in the unlikely event it does get turned off temporarily you only need to maintain at least 80% up time to receive the staking rewards and there is no slashing implemented in Avalanche.
Select Yes for Azure Spot instance, select Eviction type to Capacity Only and **make sure to set the eviction policy to Stop / Deallocate. This is very important otherwise the VM will be deleted**
Choose "Select size" to change the Virtual Machine size, and from the menu select D2s\_v4 under the D-Series v4 selection (This size has 2 Cores, 8 GB Memory and enables Premium SSDs). You can use F2s\_v2 instances instead, with are 2 Cores, 4 GB Memory and enables Premium SSDs) but the spot price actually works out cheaper for the larger VM currently with spot instance prices. You can use [this link](https://azure.microsoft.com/en-us/pricing/details/virtual-machines/linux/) to view the prices across the different regions.
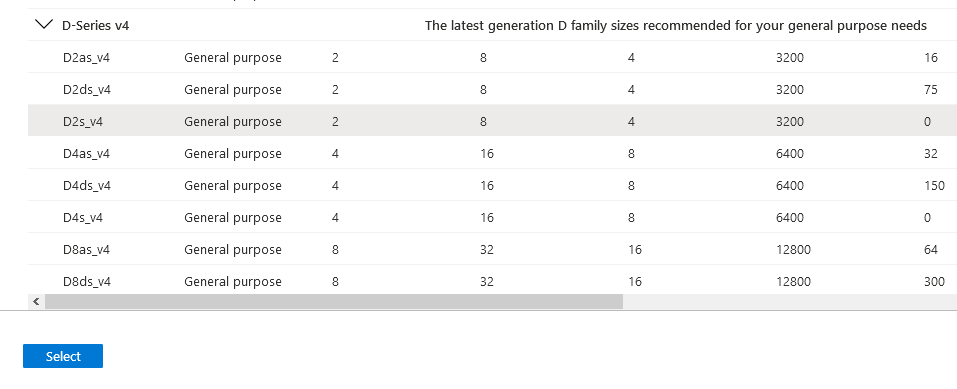
Once you have selected the size of the Virtual Machine, select "View pricing history and compare prices in nearby regions" to see how the spot price has changed over the last 3 months, and whether it's cheaper to use a nearby region which may have more spare capacity.

At the time of this article, spot pricing for D2s\_v4 in North Europe costs 0.07975perhour,oraround0.07975 per hour, or around 698.61 a year. With spot pricing, the price falls to 0.01295perhour,whichworksoutatabout0.01295 per hour, which works out at about 113.44 a year, **a saving of 83.76%!**
There are some regions which are even cheaper, East US for example is 0.01060perhouroraround0.01060 per hour or around 92.86 a year!
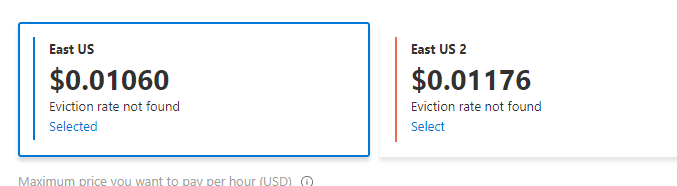
Below you can see the price history of the VM over the last 3 months for North Europe and regions nearby.
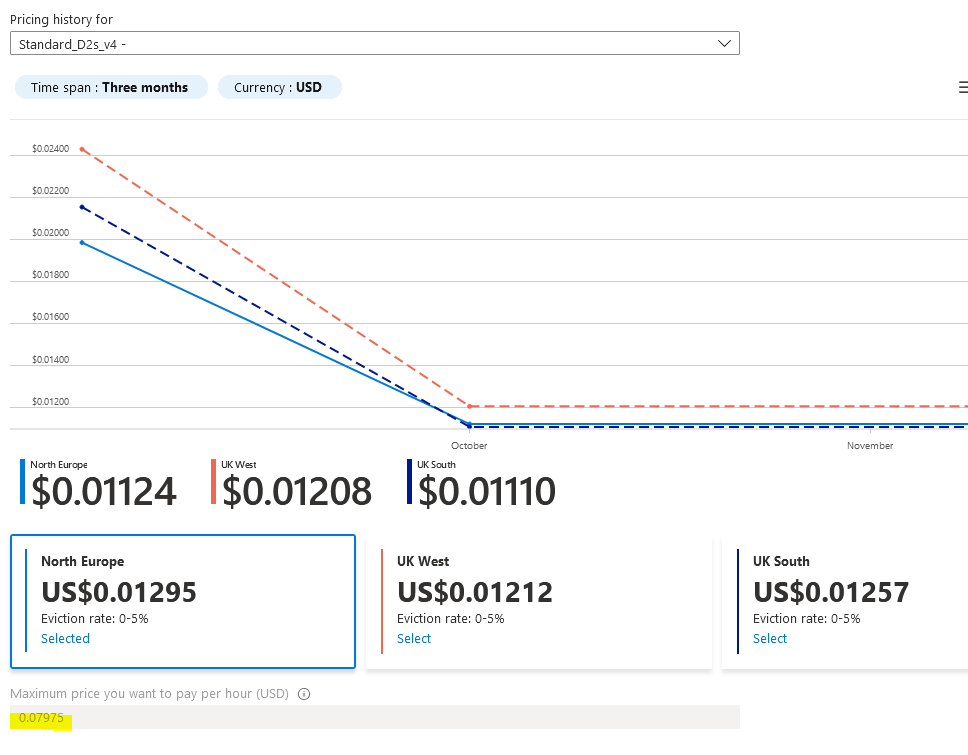
### Cheaper Than Amazon AWS[](#cheaper-than-amazon-aws "Direct link to heading")
As a comparison a c5.large instance costs 0.085USDperhouronAWS.Thistotals 0.085 USD per hour on AWS. This totals \~745 USD per year. Spot instances can save 62%, bringing that total down to \$462.
The next step is to change the username for the VM, to align with other Avalanche tutorials change the username to Ubuntu. Otherwise you will need to change several commands later in this article and swap out Ubuntu with your new username.
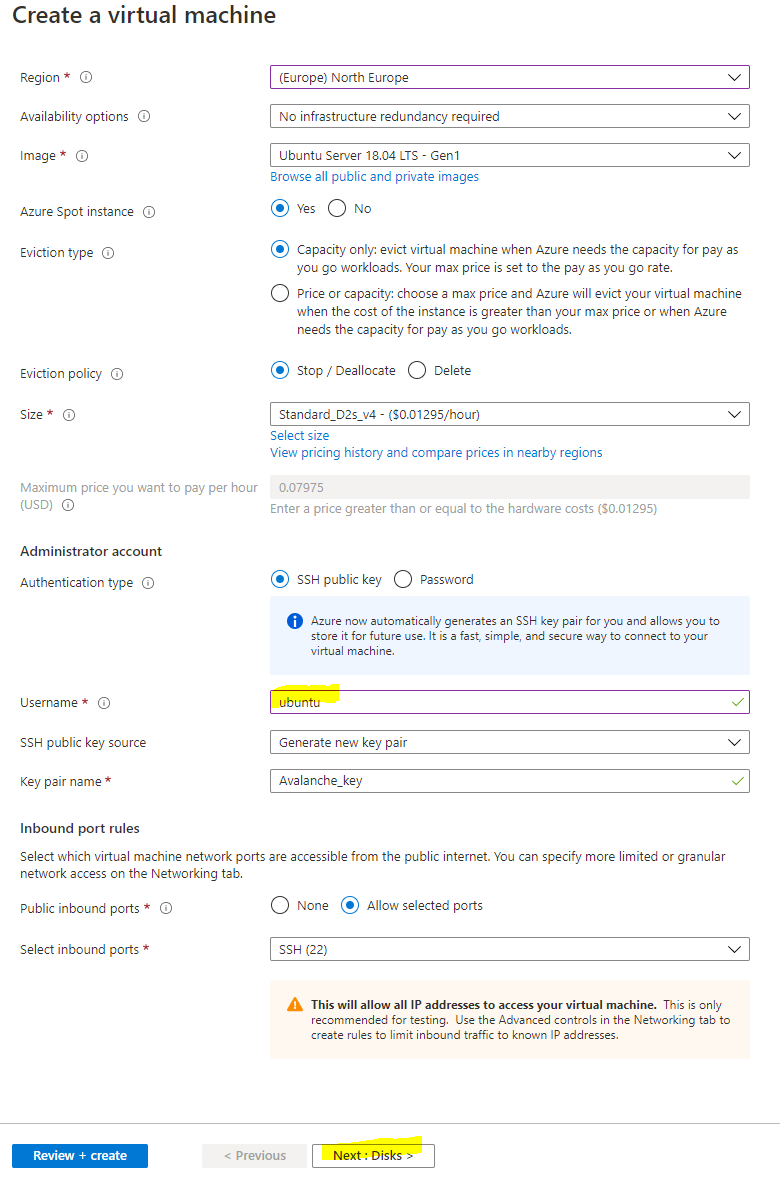
### Disks[](#disks "Direct link to heading")
Select Next: Disks to then configure the disks for the instance. There are 2 choices for disks, either Premium SSD which offer greater performance with a 64 GB disk costs around 10amonth,orthereisthestandardSSDwhichofferslowerperformanceandisaround10 a month, or there is the standard SSD which offers lower performance and is around 5 a month. You also have to pay \$0.002 per 10,000 transaction units (reads / writes and deletes) with the Standard SSD, whereas with Premium SSDs everything is included. Personally, I chose the Premium SSD for greater performance, but also because the disks are likely to be heavily used and so may even work out cheaper in the long run.
Select Next: Networking to move onto the network configuration
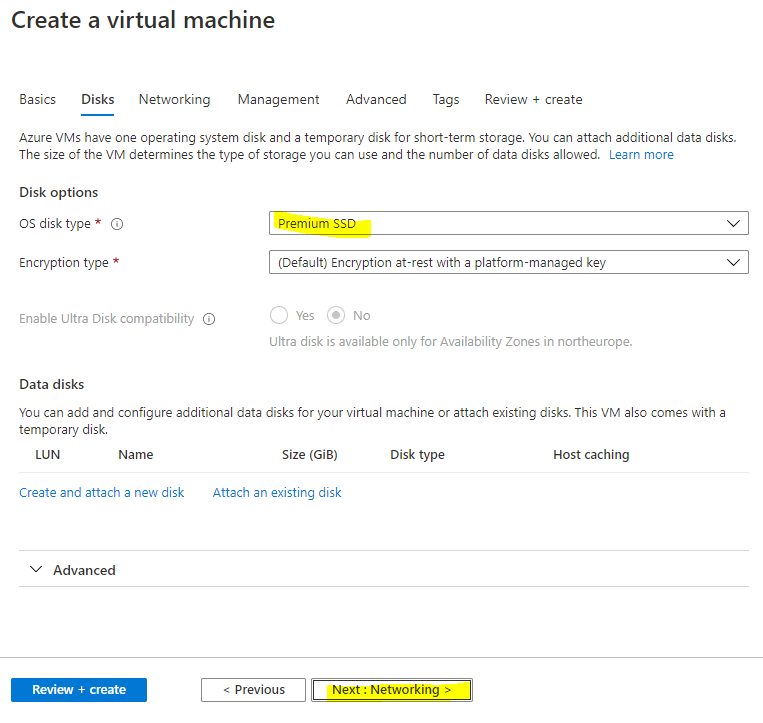
### Network Config[](#network-config "Direct link to heading")
You want to use a Static IP so that the public IP assigned to the node doesn't change in the event it stops. Under Public IP select "Create new"
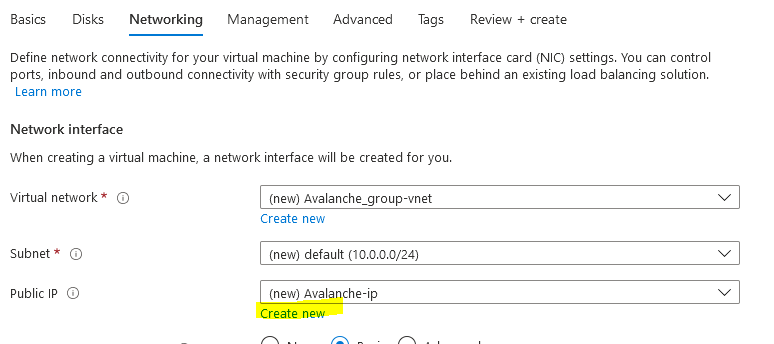
Then select "Static" as the Assignment type
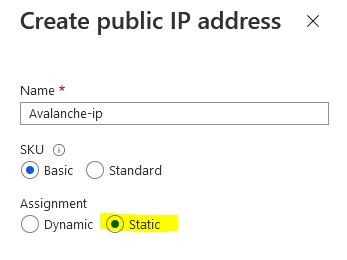
Then we need to configure the network security group to control access inbound to the Avalanche node. Select "Advanced" as the NIC network security group type and select "Create new"
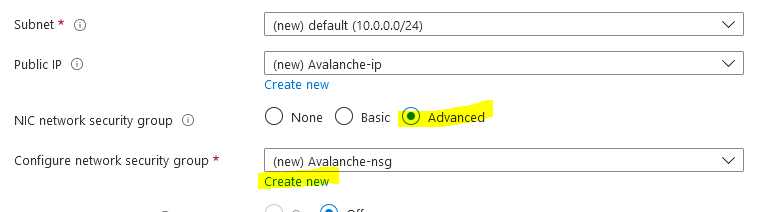
For security purposes you want to restrict who is able to remotely connect to your node. To do this you will first want to find out what your existing public IP is. This can be done by going to google and searching for "what's my IP"
It's likely that you have been assigned a dynamic public IP for your home, unless you have specifically requested it, and so your assigned public IP may change in the future. It's still recommended to restrict access to your current IP though, and then in the event your home IP changes and you are no longer able to remotely connect to the VM, you can just update the network security rules with your new public IP so you are able to connect again.
NOTE: If you need to change the network security group rules after deployment if your home IP has changed, search for "avalanche-nsg" and you can modify the rule for SSH and Port 9650 with the new IP. **Port 9651 needs to remain open to everyone** though as that's how it communicates with other Avalanche nodes.
Now that you have your public IP select the default allow ssh rule on the left under inbound rules to modify it. Change Source from "Any" to "IP Addresses" and then enter in your Public IP address that you found from google in the Source IP address field. Change the Priority towards the bottom to 100 and then press Save.
Then select "+ Add an inbound rule" to add another rule for RPC access, this should also be restricted to only your IP. Change Source to "IP Addresses" and enter in your public IP returned from google into the Source IP field. This time change the "Destination port ranges" field to 9650 and select "TCP" as the protocol. Change the priority to 110 and give it a name of "Avalanche\_RPC" and press Add.
Select "+ Add an inbound rule" to add a final rule for the Avalanche Protocol so that other nodes can communicate with your node. This rule needs to be open to everyone so keep "Source" set to "Any." Change the Destination port range to "9651" and change the protocol to "TCP." Enter a priority of 120 and a name of Avalanche\_Protocol and press Add.
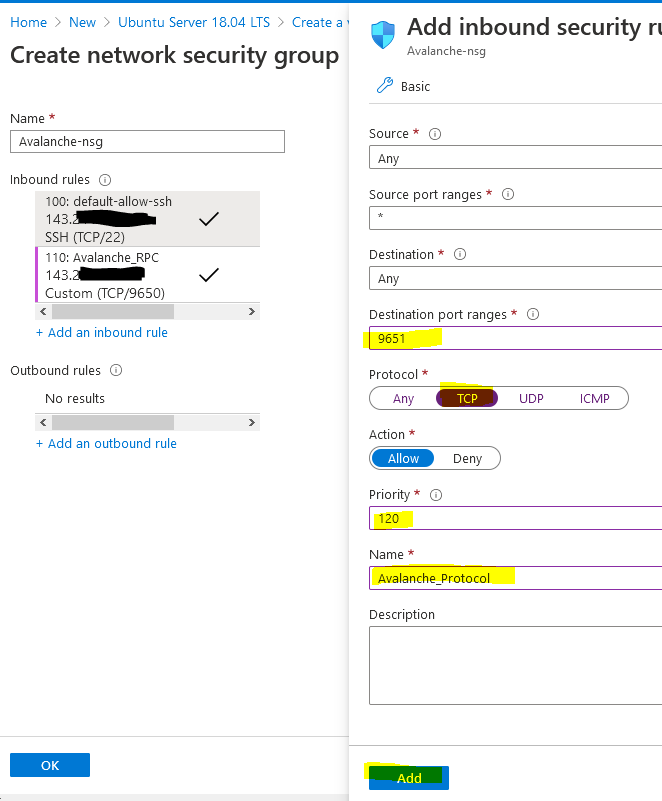
The network security group should look like the below (albeit your public IP address will be different) and press OK.
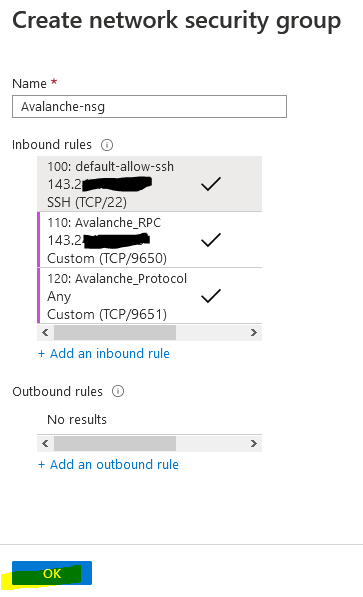
Leave the other settings as default and then press "Review + create" to create the Virtual machine.
First it will perform a validation test. If you receive an error here, make sure you selected Pay-As-You-Go subscription model and you are not using the Free Trial subscription as Spot instances are not available. Verify everything looks correct and press "Create"
You should then receive a prompt asking you to generate a new key pair to connect your virtual machine. Select "Download private key and create resource" to download the private key to your PC.
Once your deployment has finished, select "Go to resource"
## Change the Provisioned Disk Size[](#change-the-provisioned-disk-size "Direct link to heading")
By default, the Ubuntu VM will be provisioned with a 30 GB Premium SSD. You should increase this to 250 GB, to allow for database growth.
To change the Disk size, the VM needs to be stopped and deallocated. Select "Stop" and wait for the status to show deallocated. Then select "Disks" on the left.
Select the Disk name that's current provisioned to modify it
Select "Size + performance" on the left under settings and change the size to 250 GB and press "Resize"
Doing this now will also extend the partition automatically within Ubuntu. To go back to the virtual machine overview page, select Avalanche in the navigation setting.
Then start the VM
## Connect to the Avalanche Node[](#connect-to-the-avalanche-node "Direct link to heading")
The following instructions show how to connect to the Virtual Machine from a Windows 10 machine. For instructions on how to connect from a Ubuntu machine see the [AWS tutorial](/docs/nodes/on-third-party-services/amazon-web-services).
On your local PC, create a folder on the root of the C: drive called Avalanche and then move the Avalanche\_key.pem file you downloaded before into the folder. Then right click the file and select Properties. Go to the security tab and select "Advanced" at the bottom
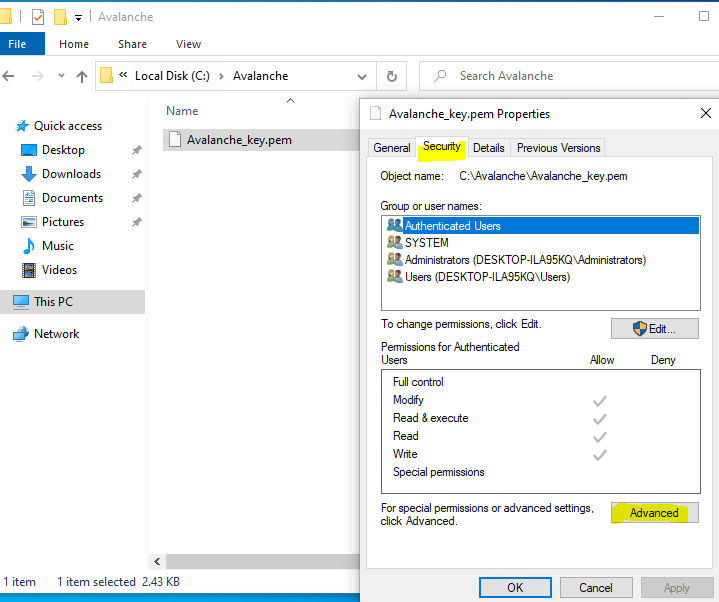
Select "Disable inheritance" and then "Remove all inherited permissions from this object" to remove all existing permissions on that file.
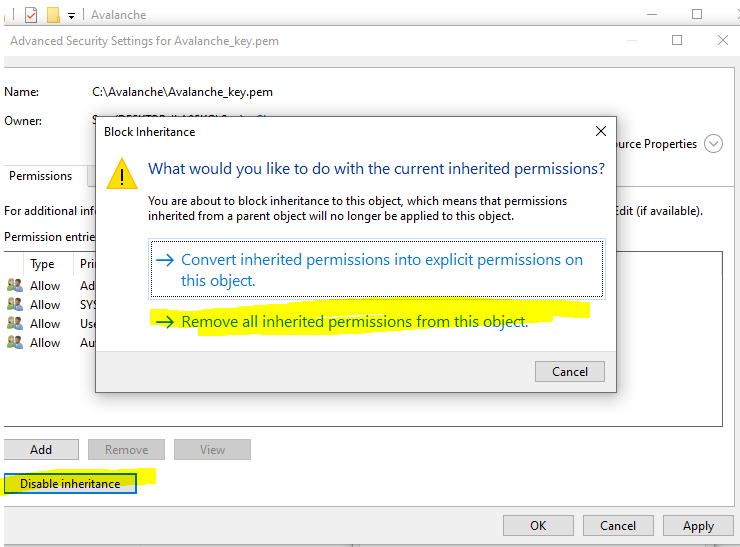
Then select "Add" to add a new permission and choose "Select a principal" at the top. From the pop-up box enter in your user account that you use to log into your machine. In this example I log on with a local user called Seq, you may have a Microsoft account that you use to log in, so use whatever account you login to your PC with and press "Check Names" and it should underline it to verify and press OK.
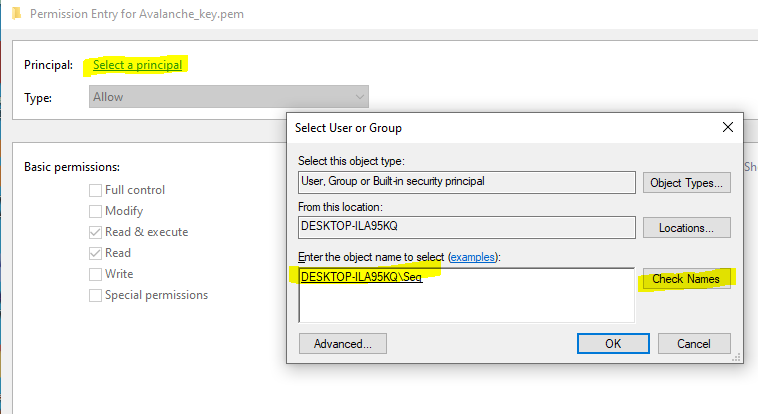
Then from the permissions section make sure only "Read & Execute" and "Read" are selected and press OK.
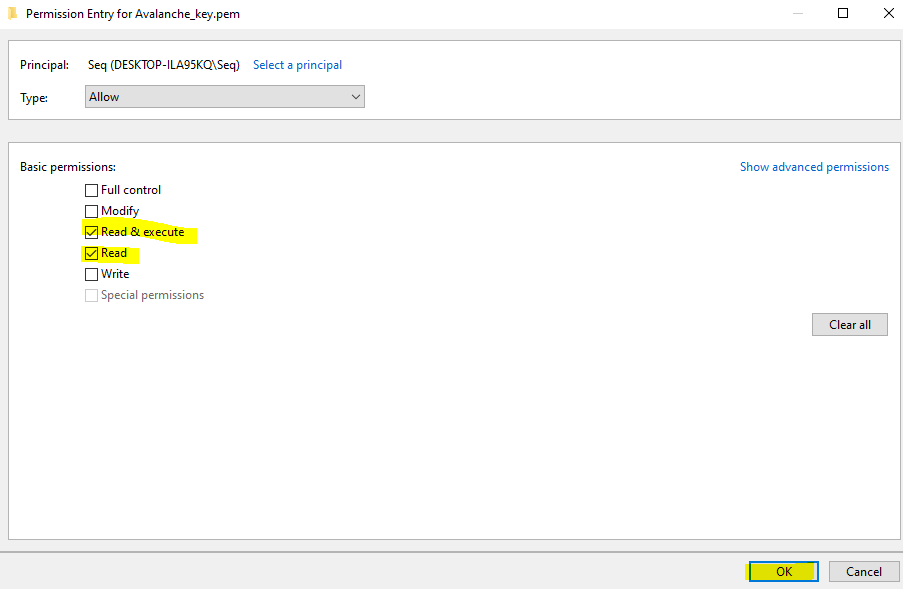
It should look something like the below, except with a different PC name / user account. This just means the key file can't be modified or accessed by any other accounts on this machine for security purposes so they can't access your Avalanche Node.
### Find your Avalanche Node Public IP[](#find-your-avalanche-node-public-ip "Direct link to heading")
From the Azure Portal make a note of your static public IP address that has been assigned to your node.
To log onto the Avalanche node, open command prompt by searching for `cmd` and selecting "Command Prompt" on your Windows 10 machine.
Then use the following command and replace the EnterYourAzureIPHere with the static IP address shown on the Azure portal.
ssh -i C:\Avalanche\Avalanche\_key.pem ubuntu\@EnterYourAzureIPHere
for my example its:
ssh -i C:\Avalanche\Avalanche\_key.pem
The first time you connect you will receive a prompt asking to continue, enter yes.

You should now be connected to your Node.
The following section is taken from Colin's excellent tutorial for [configuring an Avalanche Node on Amazon's AWS](/docs/nodes/on-third-party-services/amazon-web-services).
### Update Linux with Security Patches[](#update-linux-with-security-patches "Direct link to heading")
Now that we are on our node, it's a good idea to update it to the latest packages. To do this, run the following commands, one-at-a-time, in order:
```
sudo apt update
sudo apt upgrade -y
sudo reboot
```
This will make our instance up to date with the latest security patches for our operating system. This will also reboot the node. We'll give the node a minute or two to boot back up, then log in again, same as before.
### Set up the Avalanche Node[](#set-up-the-avalanche-node "Direct link to heading")
Now we'll need to set up our Avalanche node. To do this, follow the [Set Up Avalanche Node With Installer](/docs/nodes/using-install-script/installing-avalanche-go) tutorial which automates the installation process. You will need the "IPv4 Public IP" copied from the Azure Portal we set up earlier.
Once the installation is complete, our node should now be bootstrapping! We can run the following command to take a peek at the latest status of the AvalancheGo node:
```
sudo systemctl status avalanchego
```
To check the status of the bootstrap, we'll need to make a request to the local RPC using `curl`. This request is as follows:
```
curl -X POST --data '{
"jsonrpc":"2.0",
"id" :1,
"method" :"info.isBootstrapped",
"params": {
"chain":"X"
}
}' -H 'content-type:application/json;' 127.0.0.1:9650/ext/info
```
The node can take some time (upward of an hour at this moment writing) to bootstrap. Bootstrapping means that the node downloads and verifies the history of the chains. Give this some time. Once the node is finished bootstrapping, the response will be:
```
{
"jsonrpc": "2.0",
"result": {
"isBootstrapped": true
},
"id": 1
}
```
We can always use `sudo systemctl status avalanchego` to peek at the latest status of our service as before, as well.
### Get Your NodeID[](#get-your-nodeid "Direct link to heading")
We absolutely must get our NodeID if we plan to do any validating on this node. This is retrieved from the RPC as well. We call the following curl command to get our NodeID.
```
curl -X POST --data '{
"jsonrpc":"2.0",
"id" :1,
"method" :"info.getNodeID"
}' -H 'content-type:application/json;' 127.0.0.1:9650/ext/info
```
If all is well, the response should look something like:
```
{"jsonrpc":"2.0","result":{"nodeID":"NodeID-Lve2PzuCvXZrqn8Stqwy9vWZux6VyGUCR"},"id":1}
```
That portion that says, "NodeID-Lve2PzuCvXZrqn8Stqwy9vWZux6VyGUCR" is our NodeID, the entire thing. Copy that and keep that in our notes. There's nothing confidential or secure about this value, but it's an absolute must for when we submit this node to be a validator.
### Backup Your Staking Keys[](#backup-your-staking-keys "Direct link to heading")
The last thing that should be done is backing up our staking keys in the untimely event that our instance is corrupted or terminated. It's just good practice for us to keep these keys. To back them up, we use the following command:
```
scp -i C:\Avalanche\avalanche_key.pem -r ubuntu@EnterYourAzureIPHere:/home/ubuntu/.avalanchego/staking C:\Avalanche
```
As before, we'll need to replace "EnterYourAzureIPHere" with the appropriate value that we retrieved. This backs up our staking key and staking certificate into the C:\Avalanche folder we created before.
# Avalanche L1 Nodes
URL: /docs/nodes/run-a-node/avalanche-l1-nodes
Learn how to run an Avalanche node that tracks an Avalanche L1.
This article describes how to run a node that tracks an Avalanche L1. It requires building AvalancheGo, adding Virtual Machine binaries as plugins to your local data directory, and running AvalancheGo to track these binaries.
This tutorial specifically covers tracking an Avalanche L1 built with Avalanche's [Subnet-EVM](https://github.com/ava-labs/subnet-evm), the default [Virtual Machine](/docs/quick-start/virtual-machines) run by Avalanche L1s on Avalanche.
## Build AvalancheGo
It is recommended that you must complete [this comprehensive guide](/docs/nodes/run-a-node/from-source) which demonstrates how to build and run a basic Avalanche node from source.
## Build Avalanche L1 Binaries
After building AvalancheGo successfully,
Clone [Subnet-EVM](https://github.com/ava-labs/subnet-evm):
```bash
cd $GOPATH/src/github.com/ava-labs
git clone https://github.com/ava-labs/subnet-evm.git
```
In the Subnet-EVM directory, run the build script, and save it in the `plugins` folder of your `.avalanchego` data directory. Name the plugin after the `VMID` of the Avalanche L1 you wish to track. The `VMID` of the WAGMI Avalanche L1 is the value beginning with **srEX...**
```bash
cd $GOPATH/src/github.com/ava-labs/subnet-evm
./scripts/build.sh ~/.avalanchego/plugins/srEXiWaHuhNyGwPUi444Tu47ZEDwxTWrbQiuD7FmgSAQ6X7Dy
```
VMID, Avalanche L1 ID (SubnetID), ChainID, and all other parameters can be found in the "Chain Info" section of the Avalanche L1 Explorer.
* [Avalanche Mainnet](https://subnets.avax.network/c-chain)
* [Fuji Testnet](https://subnets-test.avax.network/c-chain)
Create a file named `config.json` and add a `track-subnets` field that is populated with the `SubnetID` you wish to track. The `SubnetID` of the WAGMI Avalanche L1 is the value beginning with **28nr...**
```bash
cd ~/.avalanchego
echo '{"track-subnets": "28nrH5T2BMvNrWecFcV3mfccjs6axM1TVyqe79MCv2Mhs8kxiY"}' > config.json
```
## Run the Node
Run AvalancheGo with the `—config-file` flag to start your node and ensure it tracks the Avalanche L1s included in the configuration file.
```bash
cd $GOPATH/src/github.com/ava-labs/avalanchego
./build/avalanchego --config-file ~/.avalanchego/config.json --network-id=fuji
```
Note: The above command includes the `--network-id=fuji` command because the WAGMI Avalanche L1 is deployed on Fuji Testnet.
If you would prefer to track Avalanche L1s using a command line flag, you can instead use the `--track-subnets` flag. For example:
```bash
./build/avalanchego --track-subnets 28nrH5T2BMvNrWecFcV3mfccjs6axM1TVyqe79MCv2Mhs8kxiY --network-id=fuji
```
You should now see terminal filled with logs and information to suggest the node is properly running and has began bootstrapping to the network.
## Bootstrapping and RPC Details
It may take a few hours for the node to fully [bootstrap](/docs/nodes/run-a-node/from-source#bootstrapping) to the Avalanche Primary Network and tracked Avalanche L1s.
When finished bootstrapping, the endpoint will be:
```bash
localhost:9650/ext/bc//rpc
```
if run locally, or:
```bash
XXX.XX.XX.XXX:9650/ext/bc//rpc
```
if run on a cloud provider. The “X”s should be replaced with the public IP of your EC2 instance.
For more information on the requests available at these endpoints, please see the [Subnet-EVM API Reference](/docs/api-reference/subnet-evm-api) documentation.
Because each node is also tracking the Primary Network, those [RPC endpoints](/docs/nodes/run-a-node/from-source#rpc) are available as well.
# Common Errors
URL: /docs/nodes/run-a-node/common-errors
Common errors while running a node and their solutions.
If you experience any issues building your node, here are some common errors and possible solutions.
### Failed to Connect to Bootstrap Nodes[](#failed-to-connect-to-bootstrap-nodes "Direct link to heading")
Error: `WARN node/node.go:291 failed to connect to bootstrap nodes`
This error can occur when the node doesn't have access to the Internet or if the NodeID is already being used by a different node in the network. This can occur when an old instance is running and not terminated.
### Cannot Query Unfinalized Data[](#cannot-query-unfinalized-data "Direct link to heading")
Error: `err="cannot query unfinalized data"`
There may be a number of reasons for this issue, but it is likely that the node is not connected properly to other validators, which is usually caused by networking misconfiguration (wrong public IP, closed p2p port 9651).
# Using Source Code
URL: /docs/nodes/run-a-node/from-source
Learn how to run an Avalanche node from AvalancheGo Source code.
The following steps walk through downloading the AvalancheGo source code and locally building the binary program. If you would like to run your node using a pre-built binary, follow [this](/docs/nodes/run-a-node/using-binary) guide.
## Install Dependencies
* Install [gcc](https://gcc.gnu.org/)
* Install [go](https://go.dev/doc/install)
## Build the Node Binary
Set the `$GOPATH`. You can follow [this](https://github.com/golang/go/wiki/SettingGOPATH) guide.
Create a directory in your `$GOPATH`:
```bash
mkdir -p $GOPATH/src/github.com/ava-labs
```
In the `$GOPATH`, clone [AvalancheGo](https://github.com/ava-labs/avalanchego), the consensus engine and node implementation that is the core of the Avalanche Network.
```bash
cd $GOPATH/src/github.com/ava-labs
git clone https://github.com/ava-labs/avalanchego.git
```
From the `avalanchego` directory, run the build script:
```bash
cd $GOPATH/src/github.com/ava-labs/avalanchego
./scripts/build.sh
```
## Start the Node
To be able to make API calls to your node from other machines, include the argument `--http-host=` when starting the node.
For running a node on the Avalanche Mainnet:
```bash
cd $GOPATH/src/github.com/ava-labs/avalanchego
./build/avalanchego
```
For running a node on the Fuji Testnet:
```bash
cd $GOPATH/src/github.com/ava-labs/avalanchego
./build/avalanchego --network-id=fuji
```
To kill the node, press `Ctrl + C`.
## Bootstrapping
A new node needs to catch up to the latest network state before it can participate in consensus and serve API calls. This process (called bootstrapping) currently takes several days for a new node connected to Mainnet, and a day or so for a new node connected to Fuji Testnet. When a given chain is done bootstrapping, it will print logs like this:
```bash
[09-09|17:01:45.295] INFO snowman/transitive.go:392 consensus starting {"lastAcceptedBlock": "2qaFwDJtmCCbMKP4jRpJwH8EFws82Q2yC1HhWgAiy3tGrpGFeb"}
[09-09|17:01:46.199] INFO snowman/transitive.go:392 consensus starting {"lastAcceptedBlock": "2ofmPJuWZbdroCPEMv6aHGvZ45oa8SBp2reEm9gNxvFjnfSGFP"}
[09-09|17:01:51.628] INFO snowman/transitive.go:334 consensus starting {"lenFrontier": 1}
```
### Check Bootstrapping Progress[](#check-bootstrapping-progress "Direct link to heading")
To check if a given chain is done bootstrapping, in another terminal window call [`info.isBootstrapped`](/docs/api-reference/info-api#infoisbootstrapped) by copying and pasting the following command:
```bash
curl -X POST --data '{
"jsonrpc":"2.0",
"id" :1,
"method" :"info.isBootstrapped",
"params": {
"chain":"X"
}
}' -H 'content-type:application/json;' 127.0.0.1:9650/ext/info
```
If this returns `true`, the chain is bootstrapped; otherwise, it returns `false`. If you make other API calls to a chain that is not done bootstrapping, it will return `API call rejected because chain is not done bootstrapping`. If you are still experiencing issues please contact us on [Discord.](https://chat.avalabs.org/)
The 3 chains will bootstrap in the following order: P-chain, X-chain, C-chain.
Learn more about bootstrapping [here](/docs/nodes/maintain/bootstrapping).
## RPC
When finished bootstrapping, the X, P, and C-Chain RPC endpoints will be:
```bash
localhost:9650/ext/bc/P
localhost:9650/ext/bc/X
localhost:9650/ext/bc/C/rpc
```
if run locally, or
```bash
XXX.XX.XX.XXX:9650/ext/bc/P
XXX.XX.XX.XXX:9650/ext/bc/X
XXX.XX.XX.XXX:9650/ext/bc/C/rpc
```
if run on a cloud provider. The “XXX.XX.XX.XXX" should be replaced with the public IP of your EC2 instance.
For more information on the requests available at these endpoints, please see the [AvalancheGo API Reference](/docs/api-reference/p-chain/api) documentation.
## Going Further
Your Avalanche node will perform consensus on its own, but it is not yet a validator on the network. This means that the rest of the network will not query your node when sampling the network during consensus. If you want to add your node as a validator, check out [Add a Validator](/docs/nodes/validate/node-validator) to take it a step further.
Also check out the [Maintain](/docs/nodes/maintain/bootstrapping) section to learn about how to maintain and customize your node to fit your needs.
To track an Avalanche L1 with your node, head to the [Avalanche L1 Node](/docs/nodes/run-a-node/avalanche-l1-nodes) tutorial.
# Using Pre-Built Binary
URL: /docs/nodes/run-a-node/using-binary
Learn how to run an Avalanche node from a pre-built binary program.
## Download Binary
To download a pre-built binary instead of building from source code, go to the official [AvalancheGo releases page](https://github.com/ava-labs/avalanchego/releases), and select the desired version.
Scroll down to the **Assets** section, and select the appropriate file. You can follow below rules to find out the right binary.
### For MacOS
Download the `avalanchego-macos-.zip` file and unzip using the below command:
```bash
unzip avalanchego-macos-.zip
```
The resulting folder, `avalanchego-`, contains the binaries.
### Linux (PCs or Cloud Providers)
Download the `avalanchego-linux-amd64-.tar.gz` file and unzip using the below command:
```bash
tar -xvf avalanchego-linux-amd64-.tar.gz
```
The resulting folder, `avalanchego--linux`, contains the binaries.
### Linux (Arm64)
Download the `avalanchego-linux-arm64-.tar.gz` file and unzip using the below command:
```bash
tar -xvf avalanchego-linux-arm64-.tar.gz
```
The resulting folder, `avalanchego--linux`, contains the binaries.
## Start the Node
To be able to make API calls to your node from other machines, include the argument `--http-host=` when starting the node.
### MacOS
For running a node on the Avalanche Mainnet:
```bash
./avalanchego-/build/avalanchego
```
For running a node on the Fuji Testnet:
```bash
./avalanchego-/build/avalanchego --network-id=fuji
```
### Linux
For running a node on the Avalanche Mainnet:
```bash
./avalanchego--linux/avalanchego
```
For running a node on the Fuji Testnet:
```bash
./avalanchego--linux/avalanchego --network-id=fuji
```
## Bootstrapping
A new node needs to catch up to the latest network state before it can participate in consensus and serve API calls. This process (called bootstrapping) currently takes several days for a new node connected to Mainnet, and a day or so for a new node connected to Fuji Testnet. When a given chain is done bootstrapping, it will print logs like this:
```bash
[09-09|17:01:45.295] INFO snowman/transitive.go:392 consensus starting {"lastAcceptedBlock": "2qaFwDJtmCCbMKP4jRpJwH8EFws82Q2yC1HhWgAiy3tGrpGFeb"}
[09-09|17:01:46.199] INFO snowman/transitive.go:392 consensus starting {"lastAcceptedBlock": "2ofmPJuWZbdroCPEMv6aHGvZ45oa8SBp2reEm9gNxvFjnfSGFP"}
[09-09|17:01:51.628] INFO snowman/transitive.go:334 consensus starting {"lenFrontier": 1}
```
### Check Bootstrapping Progress[](#check-bootstrapping-progress "Direct link to heading")
To check if a given chain is done bootstrapping, in another terminal window call [`info.isBootstrapped`](/docs/api-reference/info-api#infoisbootstrapped) by copying and pasting the following command:
```bash
curl -X POST --data '{
"jsonrpc":"2.0",
"id" :1,
"method" :"info.isBootstrapped",
"params": {
"chain":"X"
}
}' -H 'content-type:application/json;' 127.0.0.1:9650/ext/info
```
If this returns `true`, the chain is bootstrapped; otherwise, it returns `false`. If you make other API calls to a chain that is not done bootstrapping, it will return `API call rejected because chain is not done bootstrapping`. If you are still experiencing issues please contact us on [Discord.](https://chat.avalabs.org/)
The 3 chains will bootstrap in the following order: P-chain, X-chain, C-chain.
Learn more about bootstrapping [here](/docs/nodes/maintain/bootstrapping).
## RPC
When finished bootstrapping, the X, P, and C-Chain RPC endpoints will be:
```bash
localhost:9650/ext/bc/P
localhost:9650/ext/bc/X
localhost:9650/ext/bc/C/rpc
```
if run locally, or
```bash
XXX.XX.XX.XXX:9650/ext/bc/P
XXX.XX.XX.XXX:9650/ext/bc/X
XXX.XX.XX.XXX:9650/ext/bc/C/rpc
```
if run on a cloud provider. The “XXX.XX.XX.XXX" should be replaced with the public IP of your EC2 instance.
For more information on the requests available at these endpoints, please see the [AvalancheGo API Reference](/docs/api-reference/p-chain/api) documentation.
## Going Further
Your Avalanche node will perform consensus on its own, but it is not yet a validator on the network. This means that the rest of the network will not query your node when sampling the network during consensus. If you want to add your node as a validator, check out [Add a Validator](/docs/nodes/validate/node-validator) to take it a step further.
Also check out the [Maintain](/docs/nodes/maintain/bootstrapping) section to learn about how to maintain and customize your node to fit your needs.
To track an Avalanche L1 with your node, head to the [Avalanche L1 Node](/docs/nodes/run-a-node/avalanche-l1-nodes) tutorial.
# Using Docker
URL: /docs/nodes/run-a-node/using-docker
Learn how to run an Avalanche node using Docker.
## Prerequisites
Before beginning, you must ensure that:
* Docker is installed on your system
* You need to clone the [AvalancheGo repository](https://github.com/ava-labs/avalanchego)
* You need to install [GCC](https://gcc.gnu.org/) and [Go](https://go.dev/doc/install)
* Docker daemon is running on your machine
You can verify your Docker installation by running:
```bash
docker --version
```
## Building the Docker Image
To build the Docker image for the latest `avalanchego` branch:
1. Navigate to the project directory
2. Execute the build script:
```bash
./scripts/build_image.sh
```
This script will create a Docker image containing the latest version of AvalancheGo.
## Verifying the Build
After the build completes, verify the image was created successfully:
```bash
docker image ls
```
You should see an image with:
* Repository: `avaplatform/avalanchego`
* Tag: `xxxxxxxx` (where `xxxxxxxx` is the shortened commit hash of the source code used for the build)
## Running AvalancheGo Node
To start an AvalancheGo node, run the following command:
```bash
docker run -ti -p 9650:9650 -p 9651:9651 avaplatform/avalanchego:xxxxxxxx /avalanchego/build/avalanchego
```
This command:
* Creates an interactive container (`-ti`)
* Maps the following ports:
* `9650`: HTTP API port
* `9651`: P2P networking port
* Uses the built AvalancheGo image
* Executes the AvalancheGo binary inside the container
## Port Configuration
The default ports used by AvalancheGo are:
* `9650`: HTTP API
* `9651`: P2P networking
Ensure these ports are available on your host machine and not blocked by firewalls.
# Installing AvalancheGo
URL: /docs/nodes/using-install-script/installing-avalanche-go
Learn how to install AvalancheGo on your system.
## Running the Script
So, now that you prepared your system and have the info ready, let's get to it.
To download and run the script, enter the following in the terminal:
```bash
wget -nd -m https://raw.githubusercontent.com/ava-labs/avalanche-docs/master/scripts/avalanchego-installer.sh;\
chmod 755 avalanchego-installer.sh;\
./avalanchego-installer.sh
```
And we're off! The output should look something like this:
```bash
AvalancheGo installer
---------------------
Preparing environment...
Found arm64 architecture...
Looking for the latest arm64 build...
Will attempt to download:
https://github.com/ava-labs/avalanchego/releases/download/v1.1.1/avalanchego-linux-arm64-v1.1.1.tar.gz
avalanchego-linux-arm64-v1.1.1.tar.gz 100%[=========================================================================>] 29.83M 75.8MB/s in 0.4s
2020-12-28 14:57:47 URL:https://github-production-release-asset-2e65be.s3.amazonaws.com/246387644/f4d27b00-4161-11eb-8fb2-156a992fd2c8?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20201228%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201228T145747Z&X-Amz-Expires=300&X-Amz-Signature=ea838877f39ae940a37a076137c4c2689494c7e683cb95a5a4714c062e6ba018&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=246387644&response-content-disposition=attachment%3B%20filename%3Davalanchego-linux-arm64-v1.1.1.tar.gz&response-content-type=application%2Foctet-stream [31283052/31283052] -> "avalanchego-linux-arm64-v1.1.1.tar.gz" [1]
Unpacking node files...
avalanchego-v1.1.1/plugins/
avalanchego-v1.1.1/plugins/evm
avalanchego-v1.1.1/avalanchego
Node files unpacked into /home/ubuntu/avalanche-node
```
And then the script will prompt you for information about the network environment:
```bash
To complete the setup some networking information is needed.
Where is the node installed:
1) residential network (dynamic IP)
2) cloud provider (static IP)
Enter your connection type [1,2]:
```
Enter `1` if you have dynamic IP, and `2` if you have a static IP. If you are on a static IP, it will try to auto-detect the IP and ask for confirmation.
```bash
Detected '3.15.152.14' as your public IP. Is this correct? [y,n]:
```
Confirm with `y`, or `n` if the detected IP is wrong (or empty), and then enter the correct IP at the next prompt.
Next, you have to set up RPC port access for your node. Those are used to query the node for its internal state, to send commands to the node, or to interact with the platform and its chains (sending transactions, for example). You will be prompted:
```bash
RPC port should be public (this is a public API node) or private (this is a validator)? [public, private]:
```
* `private`: this setting only allows RPC requests from the node machine itself.
* `public`: this setting exposes the RPC port to all network interfaces.
As this is a sensitive setting you will be asked to confirm if choosing `public`. Please read the following note carefully:
If you choose to allow RPC requests on any network interface you will need to set up a firewall to only let through RPC requests from known IP addresses, otherwise your node will be accessible to anyone and might be overwhelmed by RPC calls from malicious actors! If you do not plan to use your node to send RPC calls remotely, enter `private`.
The script will then prompt you to choose whether to enable state sync setting or not:
```bash
Do you want state sync bootstrapping to be turned on or off? [on, off]:
```
Turning state sync on will greatly increase the speed of bootstrapping, but will sync only the current network state. If you intend to use your node for accessing historical data (archival node) you should select `off`. Otherwise, select `on`. Validators can be bootstrapped with state sync turned on.
The script will then continue with system service creation and finish with starting the service.
```bash
Created symlink /etc/systemd/system/multi-user.target.wants/avalanchego.service → /etc/systemd/system/avalanchego.service.
Done!
Your node should now be bootstrapping.
Node configuration file is /home/ubuntu/.avalanchego/configs/node.json
C-Chain configuration file is /home/ubuntu/.avalanchego/configs/chains/C/config.json
Plugin directory, for storing subnet VM binaries, is /home/ubuntu/.avalanchego/plugins
To check that the service is running use the following command (q to exit):
sudo systemctl status avalanchego
To follow the log use (ctrl-c to stop):
sudo journalctl -u avalanchego -f
Reach us over on https://chat.avax.network if you're having problems.
```
The script is finished, and you should see the system prompt again.
## Post Installation
AvalancheGo should be running in the background as a service. You can check that it's running with:
```bash
sudo systemctl status avalanchego
```
Below is an example of what the node's latest logs should look like:
```bash
● avalanchego.service - AvalancheGo systemd service
Loaded: loaded (/etc/systemd/system/avalanchego.service; enabled; vendor preset: enabled)
Active: active (running) since Tue 2021-01-05 10:38:21 UTC; 51s ago
Main PID: 2142 (avalanchego)
Tasks: 8 (limit: 4495)
Memory: 223.0M
CGroup: /system.slice/avalanchego.service
└─2142 /home/ubuntu/avalanche-node/avalanchego --public-ip-resolution-service=opendns --http-host=
Jan 05 10:38:45 ip-172-31-30-64 avalanchego[2142]: INFO [01-05|10:38:45] avalanchego/vms/platformvm/vm.go#322: initializing last accepted block as 2FUFPVPxbTpKNn39moGSzsmGroYES4NZRdw3mJgNvMkMiMHJ9e
Jan 05 10:38:45 ip-172-31-30-64 avalanchego[2142]: INFO [01-05|10:38:45]
avalanchego/snow/engine/snowman/transitive.go#58: initializing consensus engine
Jan 05 10:38:45 ip-172-31-30-64 avalanchego[2142]: INFO [01-05|10:38:45] avalanchego/api/server.go#143: adding route /ext/bc/11111111111111111111111111111111LpoYY
Jan 05 10:38:45 ip-172-31-30-64 avalanchego[2142]: INFO [01-05|10:38:45] avalanchego/api/server.go#88: HTTP API server listening on ":9650"
Jan 05 10:38:58 ip-172-31-30-64 avalanchego[2142]: INFO [01-05|10:38:58]
avalanchego/snow/engine/common/bootstrapper.go#185: Bootstrapping started syncing with 1 vertices in the accepted frontier
Jan 05 10:39:02 ip-172-31-30-64 avalanchego[2142]: INFO [01-05|10:39:02]
avalanchego/snow/engine/snowman/bootstrap/bootstrapper.go#210: fetched 2500 blocks
Jan 05 10:39:04 ip-172-31-30-64 avalanchego[2142]: INFO [01-05|10:39:04]
avalanchego/snow/engine/snowman/bootstrap/bootstrapper.go#210: fetched 5000 blocks
Jan 05 10:39:06 ip-172-31-30-64 avalanchego[2142]: INFO [01-05|10:39:06]
avalanchego/snow/engine/snowman/bootstrap/bootstrapper.go#210: fetched 7500 blocks
Jan 05 10:39:09 ip-172-31-30-64 avalanchego[2142]: INFO [01-05|10:39:09]
avalanchego/snow/engine/snowman/bootstrap/bootstrapper.go#210: fetched 10000 blocks
Jan 05 10:39:11 ip-172-31-30-64 avalanchego[2142]: INFO [01-05|10:39:11]
avalanchego/snow/engine/snowman/bootstrap/bootstrapper.go#210: fetched 12500 blocks
```
Note the `active (running)` which indicates the service is running OK. You may need to press `q` to return to the command prompt.
To find out your NodeID, which is used to identify your node to the network, run the following command:
```bash
sudo journalctl -u avalanchego | grep "NodeID"
```
It will produce output like:
```bash
Jan 05 10:38:38 ip-172-31-30-64 avalanchego[2142]: INFO [01-05|10:38:38] avalanchego/node/node.go#428: Set node's ID to 6seStrauyCnVV7NEVwRbfaT9B6EnXEzfY
```
Prepend `NodeID-` to the value to get, for example, `NodeID-6seStrauyCnVV7NEVwRbfaT9B6EnXEzfY`. Store that; it will be needed for staking or looking up your node.
Your node should be in the process of bootstrapping now. You can monitor the progress by issuing the following command:
```bash
sudo journalctl -u avalanchego -f
```
Press `ctrl+C` when you wish to stop reading node output.
# Managing AvalancheGo
URL: /docs/nodes/using-install-script/managing-avalanche-go
Learn how to start, stop and upgrade your AvalancheGo node
## Stop Your Node
To stop AvalancheGo, run:
```bash
sudo systemctl stop avalanchego
```
## Start Your Node
To start your node again, run:
```bash
sudo systemctl start avalanchego
```
## Upgrade Your Node
AvalancheGo is an ongoing project and there are regular version upgrades. Most upgrades are recommended but not required. Advance notice will be given for upgrades that are not backwards compatible. When a new version of the node is released, you will notice log lines like:
```bash
Jan 08 10:26:45 ip-172-31-16-229 avalanchego[6335]: INFO [01-08|10:26:45] avalanchego/network/peer.go#526: beacon 9CkG9MBNavnw7EVSRsuFr7ws9gascDQy3 attempting to connect with newer version avalanche/1.1.1. You may want to update your client
```
It is recommended to always upgrade to the latest version, because new versions bring bug fixes, new features and upgrades.
To upgrade your node, just run the installer script again:
```bash
./avalanchego-installer.sh
```
It will detect that you already have AvalancheGo installed:
```bash
AvalancheGo installer
---------------------
Preparing environment...
Found 64bit Intel/AMD architecture...
Found AvalancheGo systemd service already installed, switching to upgrade mode.
Stopping service...
```
It will then upgrade your node to the latest version, and after it's done, start the node back up, and print out the information about the latest version:
```bash
Node upgraded, starting service...
New node version:
avalanche/1.1.1 [network=mainnet, database=v1.0.0, commit=f76f1fd5f99736cf468413bbac158d6626f712d2]
Done!
```
# Node Config and Maintenance
URL: /docs/nodes/using-install-script/node-config-maintenance
Advanced options for configuring and maintaining your AvalancheGo node.
## Advanced Node Configuration
Without any additional arguments, the script installs the node in a most common configuration. But the script also enables various advanced options to be configured, via the command line prompts. Following is a list of advanced options and their usage:
* `admin` - [Admin API](/docs/api-reference/admin-api) will be enabled
* `archival` - disables database pruning and preserves the complete transaction history
* `state-sync` - if `on` state-sync for the C-Chain is used, if `off` it will use regular transaction replay to bootstrap; state-sync is much faster, but has no historical data
* `db-dir` - use to provide the full path to the location where the database will be stored
* `fuji` - node will connect to Fuji testnet instead of the Mainnet
* `index` - [Index API](/docs/api-reference/index-api) will be enabled
* `ip` - use `dynamic`, `static` arguments, of enter a desired IP directly to be used as the public IP node will advertise to the network
* `rpc` - use `any` or `local` argument to select any or local network interface to be used to listen for RPC calls
* `version` - install a specific node version, instead of the latest. See [here](#using-a-previous-version) for usage.
Configuring the `index` and `archival` options on an existing node will require a fresh bootstrap to recreate the database.
Complete script usage can be displayed by entering:
```bash
./avalanchego-installer.sh --help
```
### Unattended Installation[](#unattended-installation "Direct link to heading")
If you want to use the script in an automated environment where you cannot enter the data at the prompts you must provide at least the `rpc` and `ip` options. For example:
```bash
./avalanchego-installer.sh --ip 1.2.3.4 --rpc local
```
### Usage Examples[](#usage-examples "Direct link to heading")
* To run a Fuji node with indexing enabled and autodetected static IP:
```bash
./avalanchego-installer.sh --fuji --ip static --index
```
* To run an archival Mainnet node with dynamic IP and database located at `/home/node/db`:
```bash
./avalanchego-installer.sh --archival --ip dynamic --db-dir /home/node/db
```
* To use C-Chain state-sync to quickly bootstrap a Mainnet node, with dynamic IP and local RPC only:
```bash
./avalanchego-installer.sh --state-sync on --ip dynamic --rpc local
```
* To reinstall the node using node version 1.7.10 and use specific IP and local RPC only:
```bash
./avalanchego-installer.sh --reinstall --ip 1.2.3.4 --version v1.7.10 --rpc local
```
## Node Configuration[](#node-configuration "Direct link to heading")
The file that configures node operation is `~/.avalanchego/configs/node.json`. You can edit it to add or change configuration options. The documentation of configuration options can be found [here](/docs/nodes/configure/configs-flags). Configuration may look like this:
```json
{
"public-ip-resolution-service": "opendns",
"http-host": ""
}
```
Note that the configuration file needs to be a properly formatted `JSON` file, so switches should formatted differently than they would be for the command line. Therefore, don't enter options like `--public-ip-resolution-service=opendns` as shown in the example above.
The script also creates an empty C-Chain config file, located at `~/.avalanchego/configs/chains/C/config.json`. By editing that file, you can configure the C-Chain, as described in detail [here](/docs/nodes/configure/configs-flags).
## Using a Previous Version[](#using-a-previous-version "Direct link to heading")
The installer script can also be used to install a version of AvalancheGo other than the latest version.
To see a list of available versions for installation, run:
```bash
./avalanchego-installer.sh --list
```
It will print out a list, something like:
```bash
AvalancheGo installer
---------------------
Available versions:
v1.3.2
v1.3.1
v1.3.0
v1.2.4-arm-fix
v1.2.4
v1.2.3-signed
v1.2.3
v1.2.2
v1.2.1
v1.2.0
```
To install a specific version, run the script with `--version` followed by the tag of the version. For example:
```bash
./avalanchego-installer.sh --version v1.3.1
```
Note that not all AvalancheGo versions are compatible. You should generally run the latest version. Running a version other than latest may lead to your node not working properly and, for validators, not receiving a staking reward.
Thanks to community member [Jean Zundel](https://github.com/jzu) for the inspiration and help implementing support for installing non-latest node versions.
## Reinstall and Script Update[](#reinstall-and-script-update "Direct link to heading")
The installer script gets updated from time to time, with new features and capabilities added. To take advantage of new features or to recover from modifications that made the node fail, you may want to reinstall the node. To do that, fetch the latest version of the script from the web with:
```bash
wget -nd -m https://raw.githubusercontent.com/ava-labs/builders-hub/master/scripts/avalanchego-installer.sh
```
After the script has updated, run it again with the `--reinstall` config flag:
```bash
./avalanchego-installer.sh --reinstall
```
This will delete the existing service file, and run the installer from scratch, like it was started for the first time. Note that the database and NodeID will be left intact.
## Removing the Node Installation[](#removing-the-node-installation "Direct link to heading")
If you want to remove the node installation from the machine, you can run the script with the `--remove` option, like this:
```bash
./avalanchego-installer.sh --remove
```
This will remove the service, service definition file and node binaries. It will not remove the working directory, node ID definition or the node database. To remove those as well, you can type:
Please note that this is irreversible and the database and node ID will be deleted!
## What Next?[](#what-next "Direct link to heading")
That's it, you're running an AvalancheGo node! Congratulations! Let us know you did it on our [X](https://x.com/avax), [Telegram](https://t.me/avalancheavax) or [Reddit](https://www.reddit.com/r/Avax/)!
If you're on a residential network (dynamic IP), don't forget to set up port forwarding. If you're on a cloud service provider, you're good to go.
Now you can [interact with your node](/docs/api-reference/standards/guides/issuing-api-calls), [stake your tokens](/docs/nodes/validate/what-is-staking), or level up your installation by setting up [node monitoring](/docs/nodes/maintain/monitoring) to get a better insight into what your node is doing. Also, you might want to use our [Postman Collection](/docs/tooling/avalanche-postman/add-postman-collection) to more easily issue commands to your node.
Finally, if you haven't already, it is a good idea to [back up](/docs/nodes/maintain/backup-restore) important files in case you ever need to restore your node to a different machine.
If you have any questions, or need help, feel free to contact us on our [Discord](https://chat.avalabs.org/) server.
# Preparing Your Environment
URL: /docs/nodes/using-install-script/preparing-environment
Learn how to prepare your environment before using install script.
We have a shell (bash) script that installs AvalancheGo on your computer. This script sets up full, running node in a matter of minutes with minimal user input required. Script can also be used for unattended, automated installs.
This install script assumes:
* AvalancheGo is not running and not already installed as a service
* User running the script has superuser privileges (can run `sudo`)
## Environment Considerations[](#environment-considerations "Direct link to heading")
If you run a different flavor of Linux, the script might not work as intended. It assumes `systemd` is used to run system services. Other Linux flavors might use something else, or might have files in different places than is assumed by the script. It will probably work on any distribution that uses `systemd` but it has been developed for and tested on Ubuntu.
If you have a node already running on the computer, stop it before running the script. Script won't touch the node working directory so you won't need to bootstrap the node again.
### Node Running from Terminal[](#node-running-from-terminal "Direct link to heading")
If your node is running in a terminal stop it by pressing `ctrl+C`.
### Node Running as a Service[](#node-running-as-a-service "Direct link to heading")
If your node is already running as a service, then you probably don't need this script. You're good to go.
### Node Running in the Background[](#node-running-in-the-background "Direct link to heading")
If your node is running in the background (by running with `nohup`, for example) then find the process running the node by running `ps aux | grep avalanche`. This will produce output like:
```bash
ubuntu 6834 0.0 0.0 2828 676 pts/1 S+ 19:54 0:00 grep avalanche
ubuntu 2630 26.1 9.4 2459236 753316 ? Sl Dec02 1220:52 /home/ubuntu/build/avalanchego
```
Look for line that doesn't have `grep` on it. In this example, that is the second line. It shows information about your node. Note the process id, in this case, `2630`. Stop the node by running `kill -2 2630`.
### Node Working Files[](#node-working-files "Direct link to heading")
If you previously ran an AvalancheGo node on this computer, you will have local node files stored in `$HOME/.avalanchego` directory. Those files will not be disturbed, and node set up by the script will continue operation with the same identity and state it had before. That being said, for your node's security, back up `staker.crt` and `staker.key` files, found in `$HOME/.avalanchego/staking` and store them somewhere secure. You can use those files to recreate your node on a different computer if you ever need to. Check out this [tutorial](/docs/nodes/maintain/backup-restore) for backup and restore procedure.
## Networking Considerations[](#networking-considerations "Direct link to heading")
To run successfully, AvalancheGo needs to accept connections from the Internet on the network port `9651`. Before you proceed with the installation, you need to determine the networking environment your node will run in.
### Running on a Cloud Provider[](#running-on-a-cloud-provider "Direct link to heading")
If your node is running on a cloud provider computer instance, it will have a static IP. Find out what that static IP is, or set it up if you didn't already. The script will try to find out the IP by itself, but that might not work in all environments, so you will need to check the IP or enter it yourself.
### Running on a Home Connection[](#running-on-a-home-connection "Direct link to heading")
If you're running a node on a computer that is on a residential internet connection, you have a dynamic IP; that is, your IP will change periodically. The install script will configure the node appropriately for that situation. But, for a home connection, you will need to set up inbound port forwarding of port `9651` from the internet to the computer the node is installed on.
As there are too many models and router configurations, we cannot provide instructions on what exactly to do, but there are online guides to be found (like [this](https://www.noip.com/support/knowledgebase/general-port-forwarding-guide/), or [this](https://www.howtogeek.com/66214/how-to-forward-ports-on-your-router/) ), and your service provider support might help too.
Please note that a fully connected Avalanche node maintains and communicates over a couple of thousand of live TCP connections. For some low-powered and older home routers that might be too much to handle. If that is the case you may experience lagging on other computers connected to the same router, node getting benched, failing to sync and similar issues.
# How to Stake
URL: /docs/nodes/validate/how-to-stake
Learn how to stake on Avalanche.
## Staking Parameters on Avalanche[](#staking-parameters-on-avalanche "Direct link to heading")
When a validator is done validating the [Primary Network](http://support.avalabs.org/en/articles/4135650-what-is-the-primary-network), it receives back the AVAX tokens it staked. It may receive a reward for helping to secure the network. A validator only receives a [validation reward](http://support.avalabs.org/en/articles/4587396-what-are-validator-staking-rewards) if it is sufficiently responsive and correct during the time it validates. Read the [Avalanche token white paper](https://www.avalabs.org/whitepapers) to learn more about AVAX and the mechanics of staking.
Staking rewards are sent to your wallet address at the end of the staking term **as long as all of these parameters are met**.
### Mainnet[](#mainnet "Direct link to heading")
* The minimum amount that a validator must stake is 2,000 AVAX
* The minimum amount that a delegator must delegate is 25 AVAX
* The minimum amount of time one can stake funds for validation is 2 weeks
* The maximum amount of time one can stake funds for validation is 1 year
* The minimum amount of time one can stake funds for delegation is 2 weeks
* The maximum amount of time one can stake funds for delegation is 1 year
* The minimum delegation fee rate is 2%
* The maximum weight of a validator (their own stake + stake delegated to them) is the minimum of 3 million AVAX and 5 times the amount the validator staked. For example, if you staked 2,000 AVAX to become a validator, only 8000 AVAX can be delegated to your node total (not per delegator)
A validator will receive a staking reward if they are online and response for more than 80% of their validation period, as measured by a majority of validators, weighted by stake. **You should aim for your validator be online and responsive 100% of the time.**
You can call API method `info.uptime` on your node to learn its weighted uptime and what percentage of the network currently thinks your node has an uptime high enough to receive a staking reward. See [here.](/docs/api-reference/info-api#infouptime) You can get another opinion on your node's uptime from Avalanche's [Validator Health dashboard](https://stats.avax.network/dashboard/validator-health-check/). If your reported uptime is not close to 100%, there may be something wrong with your node setup, which may jeopardize your staking reward. If this is the case, please see [here](#why-is-my-uptime-low) or contact us on [Discord](https://chat.avax.network/) so we can help you find the issue. Note that only checking the uptime of your validator as measured by non-staking nodes, validators with small stake, or validators that have not been online for the full duration of your validation period can provide an inaccurate view of your node's true uptime.
### Fuji Testnet[](#fuji-testnet "Direct link to heading")
On Fuji Testnet, all staking parameters are the same as those on Mainnet except the following ones:
* The minimum amount that a validator must stake is 1 AVAX
* The minimum amount that a delegator must delegate is 1 AVAX
* The minimum amount of time one can stake funds for validation is 24 hours
* The minimum amount of time one can stake funds for delegation is 24 hours
## Validators[](#validators "Direct link to heading")
**Validators** secure Avalanche, create new blocks, and process transactions. To achieve consensus, validators repeatedly sample each other. The probability that a given validator is sampled is proportional to its stake.
When you add a node to the validator set, you specify:
* Your node's ID
* Your node's BLS key and BLS signature
* When you want to start and stop validating
* How many AVAX you are staking
* The address to send any rewards to
* Your delegation fee rate (see below)
The minimum amount that a validator must stake is 2,000 AVAX.
Note that once you issue the transaction to add a node as a validator, there is no way to change the parameters. **You can't remove your stake early or change the stake amount, node ID, or reward address.**
Please make sure you're using the correct values in the API calls below. If you're not sure, ask for help on [Discord](https://chat.avax.network/). If you want to add more tokens to your own validator, you can delegate the tokens to this node - but you cannot increase the base validation amount (so delegating to yourself goes against your delegation cap).
### Running a Validator[](#running-a-validator "Direct link to heading")
If you're running a validator, it's important that your node is well connected to ensure that you receive a reward.
When you issue the transaction to add a validator, the staked tokens and transaction fee (which is 0) are deducted from the addresses you control. When you are done validating, the staked funds are returned to the addresses they came from. If you earned a reward, it is sent to the address you specified when you added yourself as a validator.
#### Allow API Calls[](#allow-api-calls "Direct link to heading")
To make API calls to your node from remote machines, allow traffic on the API port (`9650` by default), and run your node with argument `--http-host=`
You should disable all APIs you will not use via command-line arguments. You should configure your network to only allow access to the API port from trusted machines (for example, your personal computer.)
#### Why Is My Uptime Low?[](#why-is-my-uptime-low "Direct link to heading")
Every validator on Avalanche keeps track of the uptime of other validators. Every validator has a weight (that is the amount staked on it.) The more weight a validator has, the more influence they have when validators vote on whether your node should receive a staking reward. You can call API method `info.uptime` on your node to learn its weighted uptime and what percentage of the network stake currently thinks your node has an uptime high enough to receive a staking reward.
You can also see the connections a node has by calling `info.peers`, as well as the uptime of each connection. **This is only one node's point of view**. Other nodes may perceive the uptime of your node differently. Just because one node perceives your uptime as being low does not mean that you will not receive staking rewards.
If your node's uptime is low, make sure you're setting config option `--public-ip=[NODE'S PUBLIC IP]` and that your node can receive incoming TCP traffic on port 9651.
#### Secret Management[](#secret-management "Direct link to heading")
The only secret that you need on your validating node is its Staking Key, the TLS key that determines your node's ID. The first time you start a node, the Staking Key is created and put in `$HOME/.avalanchego/staking/staker.key`. You should back up this file (and `staker.crt`) somewhere secure. Losing your Staking Key could jeopardize your validation reward, as your node will have a new ID.
You do not need to have AVAX funds on your validating node. In fact, it's best practice to **not** have a lot of funds on your node. Almost all of your funds should be in "cold" addresses whose private key is not on any computer.
#### Monitoring[](#monitoring "Direct link to heading")
Follow this [tutorial](/docs/nodes/maintain/monitoring) to learn how to monitor your node's uptime, general health, etc.
### Reward Formula[](#reward-formula "Direct link to heading")
Consider a validator which stakes a $Stake$ amount of Avax for $StakingPeriod$ seconds.
Assume that at the start of the staking period there is a $Supply$ amount of Avax in the Primary Network.
The maximum amount of Avax is $MaximumSupply$ . Then at the end of its staking period, a responsive validator receives a reward calculated as follows:
$$
Reward = \left(MaximumSupply - Supply \right) \times \frac{Stake}{Supply} \times \frac{Staking Period}{Minting Period} \times EffectiveConsumptionRate
$$
where,
$$
EffectiveConsumptionRate =
$$
$$
\frac{MinConsumptionRate}{PercentDenominator} \times \left(1- \frac{Staking Period}{Minting Period}\right) + \frac{MaxConsumptionRate}{PercentDenominator} \times \frac{Staking Period}{Minting Period}
$$
Note that $StakingPeriod$ is the staker's entire staking period, not just the staker's uptime, that is the aggregated time during which the staker has been responsive. The uptime comes into play only to decide whether a staker should be rewarded; to calculate the actual reward, only the staking period duration is taken into account.
$EffectiveConsumptionRate$ is a linear combination of $MinConsumptionRate$ and $MaxConsumptionRate$.
$MinConsumptionRate$ and $MaxConsumptionRate$ bound $EffectiveConsumptionRate$ because
$$
MinConsumptionRate \leq EffectiveConsumptionRate \leq MaxConsumptionRate
$$
The larger $StakingPeriod$ is, the closer $EffectiveConsumptionRate$ is to $MaxConsumptionRate$.
A staker achieves the maximum reward for its stake if $StakingPeriod$ = $Minting Period$.
The reward is:
$$
Max Reward = \left(MaximumSupply - Supply \right) \times \frac{Stake}{Supply} \times \frac{MaxConsumptionRate}{PercentDenominator}
$$
## Delegators[](#delegators "Direct link to heading")
A delegator is a token holder, who wants to participate in staking, but chooses to trust an existing validating node through delegation.
When you delegate stake to a validator, you specify:
* The ID of the node you're delegating to
* When you want to start/stop delegating stake (must be while the validator is validating)
* How many AVAX you are staking
* The address to send any rewards to
The minimum amount that a delegator must delegate is 25 AVAX.
Note that once you issue the transaction to add your stake to a delegator, there is no way to change the parameters. **You can't remove your stake early or change the stake amount, node ID, or reward address.** If you're not sure, ask for help on [Discord](https://chat.avax.network/).
### Delegator Rewards[](#delegator-rewards "Direct link to heading")
If the validator that you delegate tokens to is sufficiently correct and responsive, you will receive a reward when you are done delegating. Delegators are rewarded according to the same function as validators. However, the validator that you delegate to keeps a portion of your reward specified by the validator's delegation fee rate.
When you issue the transaction to delegate tokens, the staked tokens and transaction fee are deducted from the addresses you control. When you are done delegating, the staked tokens are returned to your address. If you earned a reward, it is sent to the address you specified when you delegated tokens. Rewards are sent to delegators right after the delegation ends with the return of staked tokens, and before the validation period of the node they're delegating to is complete.
## FAQ[](#faq "Direct link to heading")
### Is There a Tool to Check the Health of a Validator?[](#is-there-a-tool-to-check-the-health-of-a-validator "Direct link to heading")
Yes, just enter your node's ID in the Avalanche Stats [Validator Health Dashboard](https://stats.avax.network/dashboard/validator-health-check/?nodeid=NodeID-Jp4dLMTHd6huttS1jZhqNnBN9ZMNmTmWC).
### How Is It Determined Whether a Validator Receives a Staking Reward?[](#how-is-it-determined-whether-a-validator-receives-a-staking-reward "Direct link to heading")
When a node leaves the validator set, the validators vote on whether the leaving node should receive a staking reward or not. If a validator calculates that the leaving node was responsive for more than the required uptime (currently 80%), the validator will vote for the leaving node to receive a staking reward. Otherwise, the validator will vote that the leaving node should not receive a staking reward. The result of this vote, which is weighted by stake, determines whether the leaving node receives a reward or not.
Each validator only votes "yes" or "no." It does not share its data such as the leaving node's uptime.
Each validation period is considered separately. That is, suppose a node joins the validator set, and then leaves. Then it joins and leaves again. The node's uptime during its first period in the validator set does not affect the uptime calculation in the second period, hence, has no impact on whether the node receives a staking reward for its second period in the validator set.
### How Are Delegation Fees Distributed To Validators?[](#how-are-delegation-fees-distributed-to-validators "Direct link to heading")
If a validator is online for 80% of a delegation period, they receive a % of the reward (the fee) earned by the delegator. The P-Chain used to distribute this fee as a separate UTXO per delegation period. After the [Cortina Activation](https://medium.com/avalancheavax/cortina-x-chain-linearization-a1d9305553f6), instead of sending a fee UTXO for each successful delegation period, fees are now batched during a node's entire validation period and are distributed when it is unstaked.
### Error: Couldn't Issue TX: Validator Would Be Over Delegated[](#error-couldnt-issue-tx-validator-would-be-over-delegated "Direct link to heading")
This error occurs whenever the delegator can not delegate to the named validator. This can be caused by the following.
* The delegator `startTime` is before the validator `startTime`
* The delegator `endTime` is after the validator `endTime`
* The delegator weight would result in the validator total weight exceeding its maximum weight
# Turn Node Into Validator
URL: /docs/nodes/validate/node-validator
This tutorial will show you how to add a node to the validator set of Primary Network on Avalanche.
## Introduction
The [Primary Network](/docs/quick-start/primary-network)
is inherent to the Avalanche platform and validates Avalanche's built-in
blockchains. In this
tutorial, we'll add a node to the Primary Network on Avalanche.
The P-Chain manages metadata on Avalanche. This includes tracking which nodes
are in which Avalanche L1s, which blockchains exist, and which Avalanche L1s are validating
which blockchains. To add a validator, we'll issue
[transactions](http://support.avalabs.org/en/articles/4587384-what-is-a-transaction)
to the P-Chain.
Note that once you issue the transaction to add a node as a validator, there is
no way to change the parameters. **You can't remove your stake early or change
the stake amount, node ID, or reward address.** Please make sure you're using
the correct values in the API calls below. If you're not sure, feel free to join
our [Discord](https://chat.avalabs.org/) to ask questions.
## Requirements
You've completed [Run an Avalanche Node](/docs/nodes/run-a-node/from-source) and are familiar with
[Avalanche's architecture](/docs/quick-start/primary-network). In this
tutorial, we use [AvalancheJS](/docs/tooling/avalanche-js) and
[Avalanche's Postman collection](/docs/tooling/avalanchego-postman-collection)
to help us make API calls.
In order to ensure your node is well-connected, make sure that your node can
receive and send TCP traffic on the staking port (`9651` by default) and your node
has a public IP address(it's optional to set --public-ip=\[YOUR NODE'S PUBLIC IP HERE]
when executing the AvalancheGo binary, as by default, the node will attempt to perform
NAT traversal to get the node's IP according to its router). Failing to do either of
these may jeopardize your staking reward.
## Add a Validator with Core extension
First, we show you how to add your node as a validator by using [Core web](https://core.app).
### Retrieve the Node ID, the BLS signature and the BLS key
Get this info by calling [`info.getNodeID`](/docs/api-reference/info-api#infogetnodeid):
```bash
curl -X POST --data '{
"jsonrpc":"2.0",
"id" :1,
"method" :"info.getNodeID"
}' -H 'content-type:application/json' 127.0.0.1:9650/ext/info
```
The response has your node's ID, the BLS key (public key) and the BLS signature (proof of possession):
```json
{
"jsonrpc": "2.0",
"result": {
"nodeID": "NodeID-5mb46qkSBj81k9g9e4VFjGGSbaaSLFRzD",
"nodePOP": {
"publicKey": "0x8f95423f7142d00a48e1014a3de8d28907d420dc33b3052a6dee03a3f2941a393c2351e354704ca66a3fc29870282e15",
"proofOfPossession": "0x86a3ab4c45cfe31cae34c1d06f212434ac71b1be6cfe046c80c162e057614a94a5bc9f1ded1a7029deb0ba4ca7c9b71411e293438691be79c2dbf19d1ca7c3eadb9c756246fc5de5b7b89511c7d7302ae051d9e03d7991138299b5ed6a570a98"
}
},
"id": 1
}
```
### Add as a Validator
Connect [Core extension](https://core.app) to [Core web](https://core.app), and go the 'Staking' tab.
Here, choose 'Validate' from the menu.
Fill out the staking parameters. They are explained in more detail in [this doc](/docs/nodes/validate/how-to-stake). When you've
filled in all the staking parameters and double-checked them, click `Submit Validation`. Make sure the staking period is at
least 2 weeks, the delegation fee rate is at least 2%, and you're staking at
least 2,000 AVAX on Mainnet (1 AVAX on Fuji Testnet). A full guide about this can be found
[here](https://support.avax.network/en/articles/8117267-core-web-how-do-i-validate-in-core-stake).
You should see a success message, and your balance should be updated.
Go back to the `Stake` tab, and you'll see here an overview of your validation,
with information like the amount staked, staking time, and more.
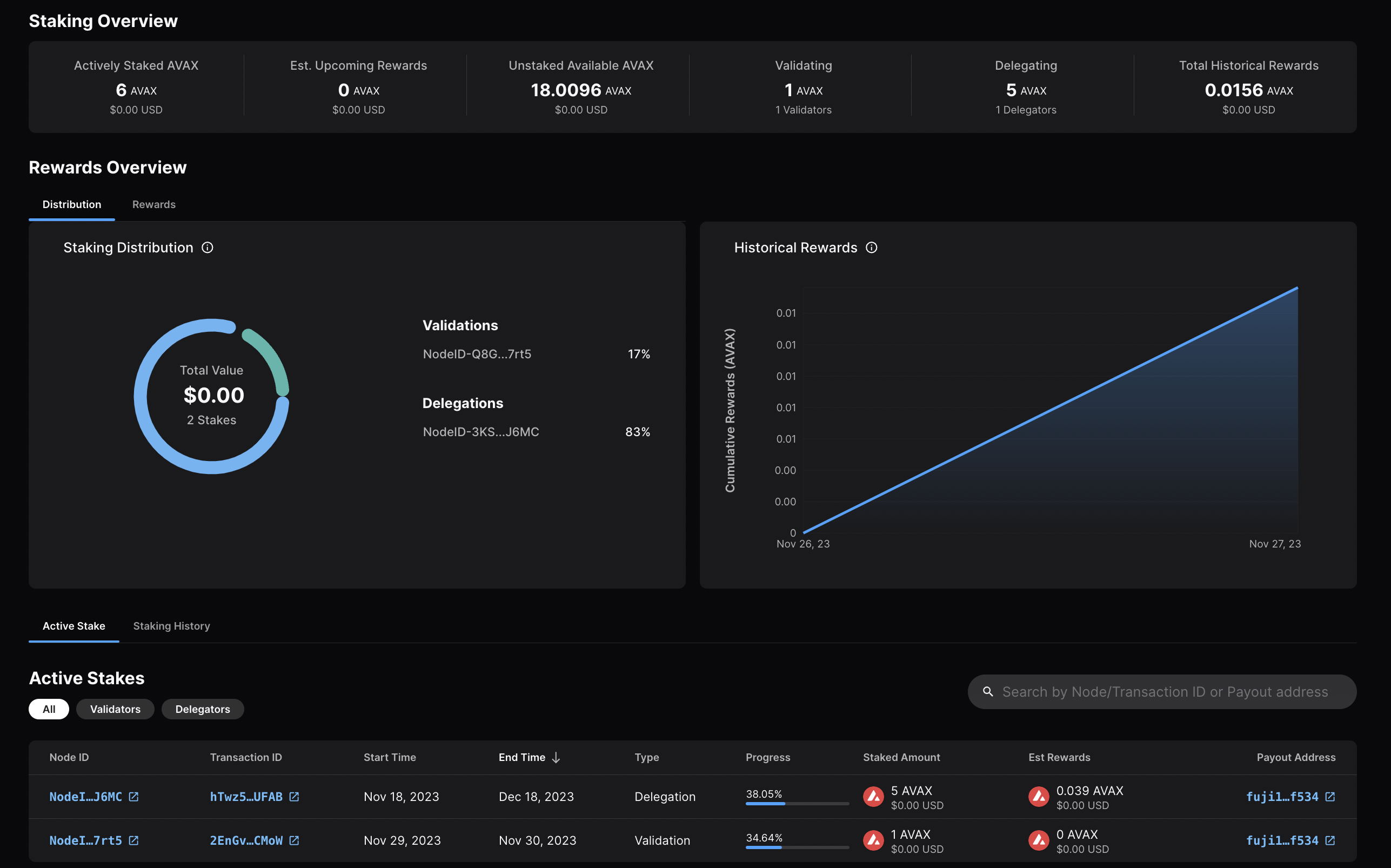
Calling
[`platform.getPendingValidators`](/docs/api-reference/p-chain/api#platformgetpendingvalidators)
verifies that your transaction was accepted. Note that this API call should be
made before your node's validation start time, otherwise, the return will not
include your node's id as it is no longer pending.
You can also call
[`platform.getCurrentValidators`](/docs/api-reference/p-chain/api#platformgetcurrentvalidators)
to check that your node's id is included in the response.
That's it!
## Add a Validator with AvalancheJS
We can also add a node to the validator set using [AvalancheJS](/docs/tooling/avalanche-js).
### Install AvalancheJS
To use AvalancheJS, you can clone the repo:
```bash
git clone https://github.com/ava-labs/avalanchejs.git
```
The repository cloning method used is HTTPS, but SSH can be used too:
`git clone git@github.com:ava-labs/avalanchejs.git`
You can find more about SSH and how to use it
[here](https://docs.github.com/en/authentication/connecting-to-github-with-ssh/about-ssh).
or add it to an existing project:
```bash
yarn add @avalabs/avalanchejs
```
For this tutorial we will use [`ts-node`](https://www.npmjs.com/package/ts-node)
to run the example scripts directly from an AvalancheJS directory.
### Fuji Workflow
In this section, we will use Fuji Testnet to show how to add a node to the validator set.
Open your AvalancheJS directory and select the
[**`examples/p-chain`**](https://github.com/ava-labs/avalanchejs/tree/master/examples/p-chain)
folder to view the source code for the examples scripts.
We will use the
[**`validate.ts`**](https://github.com/ava-labs/avalanchejs/blob/master/examples/p-chain/validate.ts)
script to add a validator.
#### Add Necessary Environment Variables
Locate the `.env.example` file at the root of AvalancheJS, and remove `.example`
from the title. Now, this will be the `.env` file for global variables.
Add the private key and the P-Chain address associated with it.
The API URL is already set to Fuji (`https://api.avax-test.network/`).
#### Retrieve the Node ID, the BLS signature and the BLS key
Get this info by calling [`info.getNodeID`](/docs/api-reference/info-api#infogetnodeid):
```bash
curl -X POST --data '{
"jsonrpc":"2.0",
"id" :1,
"method" :"info.getNodeID"
}' -H 'content-type:application/json' 127.0.0.1:9650/ext/info
```
The response has your node's ID, the BLS key (public key) and the BLS signature (proof of possession):
```json
{
"jsonrpc": "2.0",
"result": {
"nodeID": "NodeID-JXJNyJXhgXzvVGisLkrDiZvF938zJxnT5",
"nodePOP": {
"publicKey": "0xb982b485916c1d74e3b749e7ce49730ac0e52d28279ce4c5c989d75a43256d3012e04b1de0561276631ea6c2c8dc4429",
"proofOfPossession": "0xb6cdf3927783dba3245565bd9451b0c2a39af2087fdf401956489b42461452ec7639b9082195b7181907177b1ea09a6200a0d32ebbc668d9c1e9156872633cfb7e161fbd0e75943034d28b25ec9d9cdf2edad4aaf010adf804af8f6d0d5440c5"
}
},
"id": 1
}
```
#### Fill in the Node ID, the BLS signature and the BLS key
After retrieving this data, go to `examples/p-chain/validate.ts`.
Replace the `nodeID`, `blsPublicKey` and `blsSignature` with your
own node's values.

#### Settings for Validation
Next we need to specify the node's validation period and delegation fee.
#### Validation Period
The validation period is set by default to 21 days, the start date
being the date and time the transaction is issued. The start date
cannot be modified.
The end date can be adjusted in the code.
Let's say we want the validation period to end after 50 days.
You can achieve this by adding the number of desired days to
`endTime.getDate()`, in this case `50`.
```ts
// move ending date 50 days into the future
endTime.setDate(endTime.getDate() + 50);
```
Now let's say you want the staking period to end on a specific
date and time, for example May 15, 2024, at 11:20 AM.
It can be achieved as shown in the code below.
```ts
const startTime = await new PVMApi().getTimestamp();
const startDate = new Date(startTime.timestamp);
const start = BigInt(startDate.getTime() / 1000);
// Set the end time to a specific date and time
const endTime = new Date('2024-05-15T11:20:00'); // May 15, 2024, at 11:20 AM
const end = BigInt(endTime.getTime() / 1000);
```
#### Delegation Fee Rate
Avalanche allows for delegation of stake. This parameter is the percent fee this
validator charges when others delegate stake to them. For example, if
`delegationFeeRate` is `10` and someone delegates to this validator, then when
the delegation period is over, 10% of the reward goes to the validator and the
rest goes to the delegator, if this node meets the validation reward
requirements.
The delegation fee on AvalancheJS is set `20`. To change this, you need
to provide the desired fee percent as a parameter to `newAddPermissionlessValidatorTx`,
which is by default `1e4 * 20`.
For example, if you'd want it to be `10`, the updated code would look like this:
```ts
const tx = newAddPermissionlessValidatorTx(
context,
utxos,
[bech32ToBytes(P_CHAIN_ADDRESS)],
nodeID,
PrimaryNetworkID.toString(),
start,
end,
BigInt(1e9),
[bech32ToBytes(P_CHAIN_ADDRESS)],
[bech32ToBytes(P_CHAIN_ADDRESS)],
1e4 * 10, // delegation fee, replaced 20 with 10
undefined,
1,
0n,
blsPublicKey,
blsSignature,
);
```
#### Stake Amount
Set the amount being locked for validation when calling
`newAddPermissionlessValidatorTx` by replacing `weight` with a number
in the unit of nAVAX. For example, `2 AVAX` would be `2e9 nAVAX`.
```ts
const tx = newAddPermissionlessValidatorTx(
context,
utxos,
[bech32ToBytes(P_CHAIN_ADDRESS)],
nodeID,
PrimaryNetworkID.toString(),
start,
end,
BigInt(2e9), // the amount to stake
[bech32ToBytes(P_CHAIN_ADDRESS)],
[bech32ToBytes(P_CHAIN_ADDRESS)],
1e4 * 10,
undefined,
1,
0n,
blsPublicKey,
blsSignature,
);
```
#### Execute the Code
Now that we have made all of the necessary changes to the example script, it's
time to add a validator to the Fuji Network.
Run the command:
```bash
node --loader ts-node/esm examples/p-chain/validate.ts
```
The response:
```bash
laviniatalpas@Lavinias-MacBook-Pro avalanchejs % node --loader ts-node/esm examples/p-chain/validate.ts
(node:87616) ExperimentalWarning: `--experimental-loader` may be removed in the future; instead use `register()`:
--import 'data:text/javascript,import { register } from "node:module"; import { pathToFileURL } from "node:url"; register("ts-node/esm", pathToFileURL("./"));'
(Use `node --trace-warnings ...` to show where the warning was created)
{ txID: 'RVe3CFRieRbBvKXKPu24Zbt1QehdyGVT6X4tPWVBeACPX3Ab8' }
```
We can check the transaction's status by running the example script with
[`platform.getTxStatus`](/docs/api-reference/p-chain/api#platformgettxstatus)
or looking up the validator directly on the
[explorer](https://subnets-test.avax.network/validators/NodeID-JXJNyJXhgXzvVGisLkrDiZvF938zJxnT5).
### Mainnet Workflow
The Fuji workflow above can be adapted to Mainnet with the following modifications:
* `AVAX_PUBLIC_URL` should be `https://api.avax.network/`.
* `P_CHAIN_ADDRESS` should be the Mainnet P-Chain address.
* Set the correct amount to stake.
* The `blsPublicKey`, `blsSignature` and `nodeID` need to be the ones for your Mainnet Node.
# Validate vs. Delegate
URL: /docs/nodes/validate/validate-vs-delegate
Understand the difference between validation and delegation.
## Validation[](#validation "Direct link to heading")
Validation in the context of staking refers to the act of running a node on the blockchain network to validate transactions and secure the network.
* **Stake Requirement**: To become a validator on the Avalanche network, one must stake a minimum amount of 2,000 AVAX tokens on the Mainnet (1 AVAX on the Fuji Testnet).
* **Process**: Validators participate in achieving consensus by repeatedly sampling other validators. The probability of being sampled is proportional to the validator's stake, meaning the more tokens a validator stakes, the more influential they are in the consensus process.
* **Rewards**: Validators are eligible to receive rewards for their efforts in securing the network. To receive rewards, a validator must be online and responsive for more than 80% of their validation period.
## Delegation[](#delegation "Direct link to heading")
Delegation allows token holders who do not wish to run their own validator node to still participate in staking by "delegating" their tokens to an existing validator node.
* **Stake Requirement**: To delegate on the Avalanche network, a minimum of 25 AVAX tokens is required on the Mainnet (1 AVAX on the Fuji Testnet).
* **Process**: Delegators choose a specific validator node to delegate their tokens to, trusting that the validator will behave correctly and help secure the network on their behalf.
* **Rewards**: Delegators are also eligible to receive rewards for their stake. The validator they delegate to shares a portion of the reward with them, according to the validator's delegation fee rate.
## Key Differences[](#key-differences "Direct link to heading")
* **Responsibilities**: Validators actively run a node, validate transactions, and actively participate in securing the network. Delegators, on the other hand, do not run a node themselves but entrust their tokens to a validator to participate on their behalf.
* **Stake Requirement**: Validators have a higher minimum stake requirement compared to delegators, as they take on more responsibility in the network.
* **Rewards Distribution**: Validators receive rewards directly for their validation efforts. Delegators receive rewards indirectly through the validator they delegate to, sharing a portion of the validator's reward.
In summary, validation involves actively participating in securing the network by running a node, while delegation allows token holders to participate passively by trusting their stake to a chosen validator. Both validators and delegators can earn rewards, but validators have higher stakes and more direct involvement in the Avalanche network.
# What Is Staking?
URL: /docs/nodes/validate/what-is-staking
Learn about staking and how it works in Avalanche.
Staking is the process where users lock up their tokens to support a blockchain network and, in return, receive rewards. It is an essential part of proof-of-stake (PoS) consensus mechanisms used by many blockchain networks, including Avalanche. PoS systems require participants to stake a certain amount of tokens as collateral to participate in the network and validate transactions.
## How Does Proof-of-Stake Work?[](#how-does-proof-of-stake-work "Direct link to heading")
To resist [sybil attacks](https://support.avalabs.org/en/articles/4064853-what-is-a-sybil-attack), a decentralized network must require that network influence is paid with a scarce resource. This makes it infeasibly expensive for an attacker to gain enough influence over the network to compromise its security. On Avalanche, the scarce resource is the native token, [AVAX](/docs/quick-start/avax-token). For a node to validate a blockchain on Avalanche, it must stake AVAX.
# Complex Golang VM
URL: /docs/virtual-machines/golang-vms/complex-golang-vm
In this tutorial, we'll walk through how to build a virtual machine by referencing the BlobVM.
The [BlobVM](https://github.com/ava-labs/blobvm) is a virtual machine that can be used to implement a decentralized key-value store. A blob (shorthand for "binary large object") is an arbitrary piece of data.
BlobVM stores a key-value pair by breaking it apart into multiple chunks stored with their hashes as their keys in the blockchain. A root key-value pair has references to these chunks for lookups. By default, the maximum chunk size is set to 200 KiB.
## Components
A VM defines how a blockchain should be built. A block is populated with a set of transactions which mutate the state of the blockchain when executed. When a block with a set of transactions is applied to a given state, a state transition occurs by executing all of the transactions in the block in-order and applying it to the previous block of the blockchain. By executing a series of blocks chronologically, anyone can verify and reconstruct the state of the blockchain at an arbitrary point in time.
The BlobVM repository has a few components to handle the lifecycle of tasks from a transaction being issued to a block being accepted across the network:
* **Transaction**: A state transition
* **Mempool**: Stores pending transactions that haven't been finalized yet
* **Network**: Propagates transactions from the mempool other nodes in the network
* **Block**: Defines the block format, how to verify it, and how it should be accepted or rejected across the network
* **Block Builder**: Builds blocks by including transactions from the mempool
* **Virtual Machine**: Application-level logic. Implements the VM interface needed to interact with Avalanche consensus and defines the blueprint for the blockchain.
* **Service**: Exposes APIs so users can interact with the VM
* **Factory**: Used to initialize the VM
## Lifecycle of a Transaction
A VM will often times expose a set of APIs so users can interact with the it. In the blockchain, blocks can contain a set of transactions which mutate the blockchain's state. Let's dive into the lifecycle of a transaction from its issuance to its finalization on the blockchain.
* A user makes an API request to `service.IssueRawTx` to issue their transaction. This API will deserialize the user's transaction and forward it to the VM
* The transaction is submitted to the VM which is then added to the VM's mempool
* The VM asynchronously periodically gossips new transactions in its mempool to other nodes in the network so they can learn about them
* The VM sends the Avalanche consensus engine a message to indicate that it has transactions in the mempool that are ready to be built into a block
* The VM proposes the block with to consensus
* Consensus verifies that the block is valid and well-formed
* Consensus gets the network to vote on whether the block should be accepted or rejected. If a block is rejected, its transactions are reclaimed by the mempool so they can be included in a future block. If a block is accepted, it's finalized by writing it to the blockchain.
## Coding the Virtual Machine
We'll dive into a few of the packages that are in the The BlobVM repository to learn more about how they work:
1. [`vm`](https://github.com/ava-labs/blobvm/tree/master/vm)
* `block_builder.go`
* `chain_vm.go`
* `network.go`
* `service.go`
* `vm.go`
2. [`chain`](https://github.com/ava-labs/blobvm/tree/master/chain)
* `unsigned_tx.go`
* `base_tx.go`
* `transfer_tx.go`
* `set_tx.go`
* `tx.go`
* `block.go`
* `mempool.go`
* `storage.go`
* `builder.go`
3. [`mempool`](https://github.com/ava-labs/blobvm/tree/master/mempool)
* `mempool.go`
### Transactions
The state the blockchain can only be mutated by getting the network to accept a signed transaction. A signed transaction contains the transaction to be executed alongside the signature of the issuer. The signature is required to cryptographically verify the sender's identity. A VM can define an arbitrary amount of unique transactions types to support different operations on the blockchain. The BlobVM implements two different transactions types:
* [TransferTx](https://github.com/ava-labs/blobvm/blob/master/chain/transfer_tx.go) - Transfers coins between accounts.
* [SetTx](https://github.com/ava-labs/blobvm/blob/master/chain/set_tx.go) - Stores a key-value pair on the blockchain.
#### UnsignedTransaction
All transactions in the BlobVM implement the common [`UnsignedTransaction`](https://github.com/ava-labs/blobvm/blob/master/chain/unsigned_tx.go) interface, which exposes shared functionality for all transaction types.
```go
type UnsignedTransaction interface {
Copy() UnsignedTransaction
GetBlockID() ids.ID
GetMagic() uint64
GetPrice() uint64
SetBlockID(ids.ID)
SetMagic(uint64)
SetPrice(uint64)
FeeUnits(*Genesis) uint64 // number of units to mine tx
LoadUnits(*Genesis) uint64 // units that should impact fee rate
ExecuteBase(*Genesis) error
Execute(*TransactionContext) error
TypedData() *tdata.TypedData
Activity() *Activity
}
```
#### BaseTx
Common functionality and metadata for transaction types are implemented by [`BaseTx`](https://github.com/ava-labs/blobvm/blob/master/chain/base_tx.go).
* [`SetBlockID`](https://github.com/ava-labs/blobvm/blob/master/chain/base_tx.go#L26) sets the transaction's block ID.
* [`GetBlockID`](https://github.com/ava-labs/blobvm/blob/master/chain/base_tx.go#L22) returns the transaction's block ID.
* [`SetMagic`](https://github.com/ava-labs/blobvm/blob/master/chain/base_tx.go#L34) sets the magic number. The magic number is used to differentiate chains to prevent replay attacks
* [`GetMagic`](https://github.com/ava-labs/blobvm/blob/master/chain/base_tx.go#L30) returns the magic number. Magic number is defined in genesis.
* [`SetPrice`](https://github.com/ava-labs/blobvm/blob/master/chain/base_tx.go#L42) sets the price per fee unit for this transaction.
* [`GetPrice`](https://github.com/ava-labs/blobvm/blob/master/chain/base_tx.go#L38) returns the price for this transaction.
* [`FeeUnits`](https://github.com/ava-labs/blobvm/blob/master/chain/base_tx.go#L59) returns the fee units this transaction will consume.
* [`LoadUnits`](https://github.com/ava-labs/blobvm/blob/master/chain/base_tx.go#L63) identical to `FeeUnits`
* [`ExecuteBase`](https://github.com/ava-labs/blobvm/blob/master/chain/base_tx.go#L46) executes common validation checks across different transaction types. This validates the transaction contains a valid block ID, magic number, and gas price as defined by genesis.
#### TransferTx
[`TransferTx`](https://github.com/ava-labs/blobvm/blob/master/chain/transfer_tx.go#L16) supports the transfer of tokens from one account to another.
```go
type TransferTx struct {
*BaseTx `serialize:"true" json:"baseTx"`
// To is the recipient of the [Units].
To common.Address `serialize:"true" json:"to"`
// Units are transferred to [To].
Units uint64 `serialize:"true" json:"units"`
}
```
`TransferTx` embeds `BaseTx` to avoid re-implementing common operations with other transactions, but implements its own [`Execute`](https://github.com/ava-labs/blobvm/blob/master/chain/transfer_tx.go#L26) to support token transfers.
This performs a few checks to ensure that the transfer is valid before transferring the tokens between the two accounts.
```go
func (t *TransferTx) Execute(c *TransactionContext) error {
// Must transfer to someone
if bytes.Equal(t.To[:], zeroAddress[:]) {
return ErrNonActionable
}
// This prevents someone from transferring to themselves.
if bytes.Equal(t.To[:], c.Sender[:]) {
return ErrNonActionable
}
if t.Units == 0 {
return ErrNonActionable
}
if _, err := ModifyBalance(c.Database, c.Sender, false, t.Units); err != nil {
return err
}
if _, err := ModifyBalance(c.Database, t.To, true, t.Units); err != nil {
return err
}
return nil
}
```
#### SetTx
`SetTx` is used to assign a value to a key.
```go
type SetTx struct {
*BaseTx `serialize:"true" json:"baseTx"`
Value []byte `serialize:"true" json:"value"`
}
```
`SetTx` implements its own [`FeeUnits`](https://github.com/ava-labs/blobvm/blob/master/chain/set_tx.go#L48) method to compensate the network according to the size of the blob being stored.
```go
func (s *SetTx) FeeUnits(g *Genesis) uint64 {
// We don't subtract by 1 here because we want to charge extra for any
// value-based interaction (even if it is small or a delete).
return s.BaseTx.FeeUnits(g) + valueUnits(g, uint64(len(s.Value)))
}
```
`SetTx`'s [`Execute`](https://github.com/ava-labs/blobvm/blob/master/chain/set_tx.go#L21) method performs a few safety checks to validate that the blob meets the size constraints enforced by genesis and doesn't overwrite an existing key before writing it to the blockchain.
```go
func (s *SetTx) Execute(t *TransactionContext) error {
g := t.Genesis
switch {
case len(s.Value) == 0:
return ErrValueEmpty
case uint64(len(s.Value)) > g.MaxValueSize:
return ErrValueTooBig
}
k := ValueHash(s.Value)
// Do not allow duplicate value setting
_, exists, err := GetValueMeta(t.Database, k)
if err != nil {
return err
}
if exists {
return ErrKeyExists
}
return PutKey(t.Database, k, &ValueMeta{
Size: uint64(len(s.Value)),
TxID: t.TxID,
Created: t.BlockTime,
})
}
```
#### Signed Transaction
The unsigned transactions mentioned previously can't be issued to the network without first being signed. BlobVM implements signed transactions by embedding the unsigned transaction alongside its signature in [`Transaction`](https://github.com/ava-labs/blobvm/blob/master/chain/tx.go). In BlobVM, a signature is defined as the [ECDSA signature](https://en.wikipedia.org/wiki/Elliptic_Curve_Digital_Signature_Algorithm) of the issuer's private key of the [KECCAK256](https://keccak.team/keccak.html) hash of the unsigned transaction's data ([digest hash](https://eips.ethereum.org/EIPS/eip-712)).
```go
type Transaction struct {
UnsignedTransaction `serialize:"true" json:"unsignedTransaction"`
Signature []byte `serialize:"true" json:"signature"`
digestHash []byte
bytes []byte
id ids.ID
size uint64
sender common.Address
}
```
The `Transaction` type wraps any unsigned transaction. When a `Transaction` is executed, it calls the `Execute` method of the underlying embedded `UnsignedTx` and performs the following sanity checks:
1. The underlying `UnsignedTx` must meet the requirements set by genesis. This includes checks to make sure that the transaction contains the correct magic number and meets the minimum gas price as defined by genesis
2. The transaction's block ID must be a recently accepted block
3. The transaction must not be a recently issued transaction
4. The issuer of the transaction must have enough gas
5. The transaction's gas price must be meet the next expected block's minimum gas price
6. The transaction must execute without error
If the transaction is successfully verified, it's submitted as a pending write to the blockchain.
```go
func (t *Transaction) Execute(g *Genesis, db database.Database, blk *StatelessBlock, context *Context) error {
if err := t.UnsignedTransaction.ExecuteBase(g); err != nil {
return err
}
if !context.RecentBlockIDs.Contains(t.GetBlockID()) {
// Hash must be recent to be any good
// Should not happen because of mempool cleanup
return ErrInvalidBlockID
}
if context.RecentTxIDs.Contains(t.ID()) {
// Tx hash must not be recently executed (otherwise could be replayed)
//
// NOTE: We only need to keep cached tx hashes around as long as the
// block hash referenced in the tx is valid
return ErrDuplicateTx
}
// Ensure sender has balance
if _, err := ModifyBalance(db, t.sender, false, t.FeeUnits(g)*t.GetPrice()); err != nil {
return err
}
if t.GetPrice() < context.NextPrice {
return ErrInsufficientPrice
}
if err := t.UnsignedTransaction.Execute(&TransactionContext{
Genesis: g,
Database: db,
BlockTime: uint64(blk.Tmstmp),
TxID: t.id,
Sender: t.sender,
}); err != nil {
return err
}
if err := SetTransaction(db, t); err != nil {
return err
}
return nil
}
```
##### Example
Let's walk through an example on how to issue a `SetTx` transaction to the BlobVM to write a key-value pair.
1. Create the unsigned transaction for `SetTx`
```go
utx := &chain.SetTx{
BaseTx: &chain.BaseTx{},
Value: []byte("data"),
}
utx.SetBlockID(lastAcceptedID)
utx.SetMagic(genesis.Magic)
utx.SetPrice(price + blockCost/utx.FeeUnits(genesis))
```
2. Calculate the [digest hash](https://github.com/ava-labs/blobvm/blob/master/chain/tx.go#L41) for the transaction.
```go
digest, err := chain.DigestHash(utx)
```
3. [Sign](https://github.com/ava-labs/blobvm/blob/master/chain/crypto.go#L17) the digest hash with the issuer's private key.
```go
signature, err := chain.Sign(digest, privateKey)
```
4. Create and initialize the new signed transaction.
```go
tx := chain.NewTx(utx, sig)
if err := tx.Init(g); err != nil {
return ids.Empty, 0, err
}
```
5. Issue the request with the client
```
txID, err = cli.IssueRawTx(ctx, tx.Bytes())
```
### Mempool
#### Overview
The [mempool](https://github.com/ava-labs/blobvm/blob/master/mempool/mempool.go) is a buffer of volatile memory that stores pending transactions. Transactions are stored in the mempool whenever a node learns about a new transaction either through gossip with other nodes or through an API call issued by a user.
The mempool is implemented as a min-max [heap](https://en.wikipedia.org/wiki/Heap_data_structure) ordered by each transaction's gas price. The mempool is created during the [initialization](https://github.com/ava-labs/blobvm/blob/master/vm/vm.go#L93) of VM.
```go
vm.mempool = mempool.New(vm.genesis, vm.config.MempoolSize)
```
Whenever a transaction is submitted to VM, it first gets initialized, verified, and executed locally. If the transaction looks valid, then it's added to the [mempool](https://github.com/ava-labs/blobvm/blob/master/vm/vm.go#L414).
#### Add Method
When a transaction is added to the mempool, [`Add`](https://github.com/ava-labs/blobvm/blob/master/mempool/mempool.go#L43) is called. This performs the following:
* Checks if the transaction being added already exists in the mempool or not
* The transaction is added to the min-max heap
* If the mempool's heap size is larger than the maximum configured value, then the lowest paying transaction is evicted
* The transaction is added to the list of transactions that are able to be gossiped to other peers
* A notification is sent through the in the `mempool.Pending` channel to indicate that the consensus engine should build a new block
### Block Builder
#### Overview
The [`TimeBuilder`](https://github.com/ava-labs/blobvm/blob/master/vm/block_builder.go) implementation for `BlockBuilder` acts as an intermediary notification service between the mempool and the consensus engine. It serves the following functions:
* Periodically gossips new transactions to other nodes in the network
* Periodically notifies the consensus engine that new transactions from the mempool are ready to be built into blocks
`TimeBuilder` and can exist in 3 states:
* `dontBuild` - There are no transactions in the mempool that are ready to be included in a block
* `building` - The consensus engine has been notified that it should build a block and there are currently transactions in the mempool that are eligible to be included into a block
* `mayBuild` - There are transactions in the mempool that are eligible to be included into a block, but the consensus engine has not been notified yet
#### Gossip Method
The [`Gossip`](https://github.com/ava-labs/blobvm/blob/master/vm/block_builder.go#L183) method initiates the gossip of new transactions from the mempool at periodically as defined by `vm.config.GossipInterval`.
#### Build Method
The [`Build`](https://github.com/ava-labs/blobvm/blob/master/vm/block_builder.go#L166) method consumes transactions from the mempool and signals the consensus engine when it's ready to build a block.
If the mempool signals the `TimeBuilder` that it has available transactions, `TimeBuilder` will signal consensus that the VM is ready to build a block by sending the consensus engine a `common.PendingTxs` message.
When the consensus engine receives the `common.PendingTxs` message it calls the VM's `BuildBlock` method. The VM will then build a block from eligible transactions in the mempool.
If there are still remaining transactions in the mempool after a block is built, then the `TimeBuilder` is put into the `mayBuild` state to indicate that there are still transactions that are eligible to be built into block, but the consensus engine isn't aware of it yet.
### Network
[Network](https://github.com/ava-labs/blobvm/blob/master/vm/network.go) handles the workflow of gossiping transactions from a node's mempool to other nodes in the network.
#### GossipNewTxs Method
`GossipNewTxs` sends a list of transactions to other nodes in the network. `TimeBuilder` calls the network's `GossipNewTxs` function to gossip new transactions in the mempool.
```go
func (n *PushNetwork) GossipNewTxs(newTxs []*chain.Transaction) error {
txs := []*chain.Transaction{}
// Gossip at most the target units of a block at once
for _, tx := range newTxs {
if _, exists := n.gossipedTxs.Get(tx.ID()); exists {
log.Debug("already gossiped, skipping", "txId", tx.ID())
continue
}
n.gossipedTxs.Put(tx.ID(), nil)
txs = append(txs, tx)
}
return n.sendTxs(txs)
}
```
Recently gossiped transactions are maintained in a cache to avoid DDoSing a node from repeated gossip failures.
Other nodes in the network will receive the gossiped transactions through their `AppGossip` handler. Once a gossip message is received, it's deserialized and the new transactions are submitted to the VM.
```go
func (vm *VM) AppGossip(nodeID ids.NodeID, msg []byte) error {
txs := make([]*chain.Transaction, 0)
if _, err := chain.Unmarshal(msg, &txs); err != nil {
return nil
}
// submit incoming gossip
log.Debug("AppGossip transactions are being submitted", "txs", len(txs))
if errs := vm.Submit(txs...); len(errs) > 0 {
for _, err := range errs {
}
}
return nil
}
```
### Block
Blocks go through a lifecycle of being proposed by a validator, verified, and decided by consensus. Upon acceptance, a block will be committed and will be finalized on the blockchain.
BlobVM implements two types of blocks, `StatefulBlock` and `StatelessBlock`.
#### StatefulBlock
A [`StatefulBlock`](https://github.com/ava-labs/blobvm/blob/master/chain/block.go#L27) contains strictly the metadata about the block that needs to be written to the database.
```go
type StatefulBlock struct {
Prnt ids.ID `serialize:"true" json:"parent"`
Tmstmp int64 `serialize:"true" json:"timestamp"`
Hght uint64 `serialize:"true" json:"height"`
Price uint64 `serialize:"true" json:"price"`
Cost uint64 `serialize:"true" json:"cost"`
AccessProof common.Hash `serialize:"true" json:"accessProof"`
Txs []*Transaction `serialize:"true" json:"txs"`
}
```
#### StatelessBlock
[StatelessBlock](https://github.com/ava-labs/blobvm/blob/master/chain/block.go#L40) is a superset of `StatefulBlock` and additionally contains fields that are needed to support block-level operations like verification and acceptance throughout its lifecycle in the VM.
```go
type StatelessBlock struct {
*StatefulBlock `serialize:"true" json:"block"`
id ids.ID
st choices.Status
t time.Time
bytes []byte
vm VM
children []*StatelessBlock
onAcceptDB *versiondb.Database
}
```
Let's have a look at the fields of StatelessBlock:
* `StatefulBlock`: The metadata about the block that will be written to the database upon acceptance
* `bytes`: The serialized form of the `StatefulBlock`.
* `id`: The Keccak256 hash of `bytes`.
* `st`: The status of the block in consensus (i.e `Processing`, `Accepted`, or `Rejected`)
* `children`: The children of this block
* `onAcceptDB`: The database this block should be written to upon acceptance.
When the consensus engine tries to build a block by calling the VM's `BuildBlock`, the VM calls the [`block.NewBlock`](https://github.com/ava-labs/blobvm/blob/master/chain/block.go#L53) function to get a new block that is a child of the currently preferred block.
```go
func NewBlock(vm VM, parent snowman.Block, tmstp int64, context *Context) *StatelessBlock {
return &StatelessBlock{
StatefulBlock: &StatefulBlock{
Tmstmp: tmstp,
Prnt: parent.ID(),
Hght: parent.Height() + 1,
Price: context.NextPrice,
Cost: context.NextCost,
},
vm: vm,
st: choices.Processing,
}
}
```
Some `StatelessBlock` fields like the block ID, byte representation, and timestamp aren't populated immediately. These are set during the `StatelessBlock`'s [`init`](https://github.com/ava-labs/blobvm/blob/master/chain/block.go#L113) method, which initializes these fields once the block has been populated with transactions.
```go
func (b *StatelessBlock) init() error {
bytes, err := Marshal(b.StatefulBlock)
if err != nil {
return err
}
b.bytes = bytes
id, err := ids.ToID(crypto.Keccak256(b.bytes))
if err != nil {
return err
}
b.id = id
b.t = time.Unix(b.StatefulBlock.Tmstmp, 0)
g := b.vm.Genesis()
for _, tx := range b.StatefulBlock.Txs {
if err := tx.Init(g); err != nil {
return err
}
}
return nil
}
```
To build the block, the VM will try to remove as many of the highest-paying transactions from the mempool to include them in the new block until the maximum block fee set by genesis is reached.
A block once built, can exist in two states:
1. Rejected: The block was not accepted by consensus. In this case, the mempool will reclaim the rejected block's transactions so they can be included in a future block.
2. Accepted: The block was accepted by consensus. In this case, we write the block to the blockchain by committing it to the database.
When the consensus engine receives the built block, it calls the block's [`Verify`](https://github.com/ava-labs/blobvm/blob/master/chain/block.go#L228) method to validate that the block is well-formed. In BlobVM, the following constraints are placed on valid blocks:
1. A block must contain at least one transaction and the block's timestamp must be within 10s into the future.
```go
if len(b.Txs) == 0 {
return nil, nil, ErrNoTxs
}
if b.Timestamp().Unix() >= time.Now().Add(futureBound).Unix() {
return nil, nil, ErrTimestampTooLate
}
```
2. The sum of the gas units consumed by the transactions in the block must not exceed the gas limit defined by genesis.
```go
blockSize := uint64(0)
for _, tx := range b.Txs {
blockSize += tx.LoadUnits(g)
if blockSize > g.MaxBlockSize {
return nil, nil, ErrBlockTooBig
}
}
```
3. The parent block of the proposed block must exist and have an earlier timestamp.
```go
parent, err := b.vm.GetStatelessBlock(b.Prnt)
if err != nil {
log.Debug("could not get parent", "id", b.Prnt)
return nil, nil, err
}
if b.Timestamp().Unix() < parent.Timestamp().Unix() {
return nil, nil, ErrTimestampTooEarly
}
```
4. The target block price and minimum gas price must meet the minimum enforced by the VM.
```go
context, err := b.vm.ExecutionContext(b.Tmstmp, parent)
if err != nil {
return nil, nil, err
}
if b.Cost != context.NextCost {
return nil, nil, ErrInvalidCost
}
if b.Price != context.NextPrice {
return nil, nil, ErrInvalidPrice
}
```
After the results of consensus are complete, the block is either accepted by committing the block to the database or rejected by returning the block's transactions into the mempool.
```go
// implements "snowman.Block.choices.Decidable"
func (b *StatelessBlock) Accept() error {
if err := b.onAcceptDB.Commit(); err != nil {
return err
}
for _, child := range b.children {
if err := child.onAcceptDB.SetDatabase(b.vm.State()); err != nil {
return err
}
}
b.st = choices.Accepted
b.vm.Accepted(b)
return nil
}
// implements "snowman.Block.choices.Decidable"
func (b *StatelessBlock) Reject() error {
b.st = choices.Rejected
b.vm.Rejected(b)
return nil
}
```
### API
[Service](https://github.com/ava-labs/blobvm/blob/master/vm/public_service.go) implements an API server so users can interact with the VM. The VM implements the interface method [`CreateHandlers`](https://github.com/ava-labs/blobvm/blob/master/vm/vm.go#L267) that exposes the VM's RPC API.
```go
func (vm *VM) CreateHandlers() (map[string]*common.HTTPHandler, error) {
apis := map[string]*common.HTTPHandler{}
public, err := newHandler(Name, &PublicService{vm: vm})
if err != nil {
return nil, err
}
apis[PublicEndpoint] = public
return apis, nil
}
```
One API that's exposed is [`IssueRawTx`](https://github.com/ava-labs/blobvm/blob/master/vm/public_service.go#L63) to allow users to issue transactions to the BlobVM. It accepts an `IssueRawTxArgs` that contains the transaction the user wants to issue and forwards it to the VM.
```go
func (svc *PublicService) IssueRawTx(_ *http.Request, args *IssueRawTxArgs, reply *IssueRawTxReply) error {
tx := new(chain.Transaction)
if _, err := chain.Unmarshal(args.Tx, tx); err != nil {
return err
}
// otherwise, unexported tx.id field is empty
if err := tx.Init(svc.vm.genesis); err != nil {
return err
}
reply.TxID = tx.ID()
errs := svc.vm.Submit(tx)
if len(errs) == 0 {
return nil
}
if len(errs) == 1 {
return errs[0]
}
return fmt.Errorf("%v", errs)
}
```
### Virtual Machine
We have learned about all the components used in the BlobVM. Most of these components are referenced in the `vm.go` file, which acts as the entry point for the consensus engine as well as users interacting with the blockchain.
For example, the engine calls `vm.BuildBlock()`, that in turn calls `chain.BuildBlock()`. Another example is when a user issues a raw transaction through service APIs, the `vm.Submit()` method is called.
Let's look at some of the important methods of `vm.go` that must be implemented:
#### Initialize Method
[Initialize](https://github.com/ava-labs/blobvm/blob/master/vm/vm.go#L93) is invoked by `avalanchego` when creating the blockchain. `avalanchego` passes some parameters to the implementing VM.
* `ctx` - Metadata about the VM's execution
* `dbManager` - The database that the VM can write to
* `genesisBytes` - The serialized representation of the genesis state of this VM
* `upgradeBytes` - The serialized representation of network upgrades
* `configBytes` - The serialized VM-specific [configuration](https://github.com/ava-labs/blobvm/blob/master/vm/config.go#L10)
* `toEngine` - The channel used to send messages to the consensus engine
* `fxs` - Feature extensions that attach to this VM
* `appSender` - Used to send messages to other nodes in the network
BlobVM upon initialization persists these fields in its own state to use them throughout the lifetime of its execution.
```go
// implements "snowmanblock.ChainVM.common.VM"
func (vm *VM) Initialize(
ctx *snow.Context,
dbManager manager.Manager,
genesisBytes []byte,
upgradeBytes []byte,
configBytes []byte,
toEngine chan<- common.Message,
_ []*common.Fx,
appSender common.AppSender,
) error {
log.Info("initializing blobvm", "version", version.Version)
// Load config
vm.config.SetDefaults()
if len(configBytes) > 0 {
if err := ejson.Unmarshal(configBytes, &vm.config); err != nil {
return fmt.Errorf("failed to unmarshal config %s: %w", string(configBytes), err)
}
}
vm.ctx = ctx
vm.db = dbManager.Current().Database
vm.activityCache = make([]*chain.Activity, vm.config.ActivityCacheSize)
// Init channels before initializing other structs
vm.stop = make(chan struct{})
vm.builderStop = make(chan struct{})
vm.doneBuild = make(chan struct{})
vm.doneGossip = make(chan struct{})
vm.appSender = appSender
vm.network = vm.NewPushNetwork()
vm.blocks = &cache.LRU{Size: blocksLRUSize}
vm.verifiedBlocks = make(map[ids.ID]*chain.StatelessBlock)
vm.toEngine = toEngine
vm.builder = vm.NewTimeBuilder()
// Try to load last accepted
has, err := chain.HasLastAccepted(vm.db)
if err != nil {
log.Error("could not determine if have last accepted")
return err
}
// Parse genesis data
vm.genesis = new(chain.Genesis)
if err := ejson.Unmarshal(genesisBytes, vm.genesis); err != nil {
log.Error("could not unmarshal genesis bytes")
return err
}
if err := vm.genesis.Verify(); err != nil {
log.Error("genesis is invalid")
return err
}
targetUnitsPerSecond := vm.genesis.TargetBlockSize / uint64(vm.genesis.TargetBlockRate)
vm.targetRangeUnits = targetUnitsPerSecond * uint64(vm.genesis.LookbackWindow)
log.Debug("loaded genesis", "genesis", string(genesisBytes), "target range units", vm.targetRangeUnits)
vm.mempool = mempool.New(vm.genesis, vm.config.MempoolSize)
if has { //nolint:nestif
blkID, err := chain.GetLastAccepted(vm.db)
if err != nil {
log.Error("could not get last accepted", "err", err)
return err
}
blk, err := vm.GetStatelessBlock(blkID)
if err != nil {
log.Error("could not load last accepted", "err", err)
return err
}
vm.preferred, vm.lastAccepted = blkID, blk
log.Info("initialized blobvm from last accepted", "block", blkID)
} else {
genesisBlk, err := chain.ParseStatefulBlock(
vm.genesis.StatefulBlock(),
nil,
choices.Accepted,
vm,
)
if err != nil {
log.Error("unable to init genesis block", "err", err)
return err
}
// Set Balances
if err := vm.genesis.Load(vm.db, vm.AirdropData); err != nil {
log.Error("could not set genesis allocation", "err", err)
return err
}
if err := chain.SetLastAccepted(vm.db, genesisBlk); err != nil {
log.Error("could not set genesis as last accepted", "err", err)
return err
}
gBlkID := genesisBlk.ID()
vm.preferred, vm.lastAccepted = gBlkID, genesisBlk
log.Info("initialized blobvm from genesis", "block", gBlkID)
}
vm.AirdropData = nil
}
```
After initializing its own state, BlobVM also starts asynchronous workers to build blocks and gossip transactions to the rest of the network.
```
{
go vm.builder.Build()
go vm.builder.Gossip()
return nil
}
```
#### GetBlock Method
[`GetBlock`](https://github.com/ava-labs/blobvm/blob/master/vm/vm.go#L318) returns the block with the provided ID. GetBlock will attempt to fetch the given block from the database, and return an non-nil error if it wasn't able to get it.
```go
func (vm *VM) GetBlock(id ids.ID) (snowman.Block, error) {
b, err := vm.GetStatelessBlock(id)
if err != nil {
log.Warn("failed to get block", "err", err)
}
return b, err
}
```
#### ParseBlock Method
[`ParseBlock`](https://github.com/ava-labs/blobvm/blob/master/vm/vm.go#L373) deserializes a block.
```go
func (vm *VM) ParseBlock(source []byte) (snowman.Block, error) {
newBlk, err := chain.ParseBlock(
source,
choices.Processing,
vm,
)
if err != nil {
log.Error("could not parse block", "err", err)
return nil, err
}
log.Debug("parsed block", "id", newBlk.ID())
// If we have seen this block before, return it with the most
// up-to-date info
if oldBlk, err := vm.GetBlock(newBlk.ID()); err == nil {
log.Debug("returning previously parsed block", "id", oldBlk.ID())
return oldBlk, nil
}
return newBlk, nil
}
```
#### BuildBlock Method
Avalanche consensus calls [`BuildBlock`](https://github.com/ava-labs/blobvm/blob/master/vm/vm.go#L397) when it receives a notification from the VM that it has pending transactions that are ready to be issued into a block.
```go
func (vm *VM) BuildBlock() (snowman.Block, error) {
log.Debug("BuildBlock triggered")
blk, err := chain.BuildBlock(vm, vm.preferred)
vm.builder.HandleGenerateBlock()
if err != nil {
log.Debug("BuildBlock failed", "error", err)
return nil, err
}
sblk, ok := blk.(*chain.StatelessBlock)
if !ok {
return nil, fmt.Errorf("unexpected snowman.Block %T, expected *StatelessBlock", blk)
}
log.Debug("BuildBlock success", "blkID", blk.ID(), "txs", len(sblk.Txs))
return blk, nil
}
```
#### SetPreference Method
[`SetPreference`](https://github.com/ava-labs/blobvm/blob/master/vm/vm.go#L457) sets the block ID preferred by this node. A node votes to accept or reject a block based on its current preference in consensus.
```go
func (vm *VM) SetPreference(id ids.ID) error {
log.Debug("set preference", "id", id)
vm.preferred = id
return nil
}
```
#### LastAccepted Method
[LastAccepted](https://github.com/ava-labs/blobvm/blob/master/vm/vm.go#L465) returns the block ID of the block that was most recently accepted by this node.
```go
func (vm *VM) LastAccepted() (ids.ID, error) {
return vm.lastAccepted.ID(), nil
}
```
### CLI
BlobVM implements a generic key-value store, but support to read and write arbitrary files into the BlobVM blockchain is implemented in the `blob-cli`
To write a file, BlobVM breaks apart an arbitrarily large file into many small chunks. Each chunk is submitted to the VM in a `SetTx`. A root key is generated which contains all of the hashes of the chunks.
```go
func Upload(
ctx context.Context, cli client.Client, priv *ecdsa.PrivateKey,
f io.Reader, chunkSize int,
) (common.Hash, error) {
hashes := []common.Hash{}
chunk := make([]byte, chunkSize)
shouldExit := false
opts := []client.OpOption{client.WithPollTx()}
totalCost := uint64(0)
uploaded := map[common.Hash]struct{}{}
for !shouldExit {
read, err := f.Read(chunk)
if errors.Is(err, io.EOF) || read == 0 {
break
}
if err != nil {
return common.Hash{}, fmt.Errorf("%w: read error", err)
}
if read < chunkSize {
shouldExit = true
chunk = chunk[:read]
// Use small file optimization
if len(hashes) == 0 {
break
}
}
k := chain.ValueHash(chunk)
if _, ok := uploaded[k]; ok {
color.Yellow("already uploaded k=%s, skipping", k)
} else if exists, _, _, err := cli.Resolve(ctx, k); err == nil && exists {
color.Yellow("already on-chain k=%s, skipping", k)
uploaded[k] = struct{}{}
} else {
tx := &chain.SetTx{
BaseTx: &chain.BaseTx{},
Value: chunk,
}
txID, cost, err := client.SignIssueRawTx(ctx, cli, tx, priv, opts...)
if err != nil {
return common.Hash{}, err
}
totalCost += cost
color.Yellow("uploaded k=%s txID=%s cost=%d totalCost=%d", k, txID, cost, totalCost)
uploaded[k] = struct{}{}
}
hashes = append(hashes, k)
}
r := &Root{}
if len(hashes) == 0 {
if len(chunk) == 0 {
return common.Hash{}, ErrEmpty
}
r.Contents = chunk
} else {
r.Children = hashes
}
rb, err := json.Marshal(r)
if err != nil {
return common.Hash{}, err
}
rk := chain.ValueHash(rb)
tx := &chain.SetTx{
BaseTx: &chain.BaseTx{},
Value: rb,
}
txID, cost, err := client.SignIssueRawTx(ctx, cli, tx, priv, opts...)
if err != nil {
return common.Hash{}, err
}
totalCost += cost
color.Yellow("uploaded root=%v txID=%s cost=%d totalCost=%d", rk, txID, cost, totalCost)
return rk, nil
}
```
#### Example 1
```bash
blob-cli set-file ~/Downloads/computer.gif -> 6fe5a52f52b34fb1e07ba90bad47811c645176d0d49ef0c7a7b4b22013f676c8
```
Given the root hash, a file can be looked up by deserializing all of its children chunk values and reconstructing the original file.
```go
// TODO: make multi-threaded
func Download(ctx context.Context, cli client.Client, root common.Hash, f io.Writer) error {
exists, rb, _, err := cli.Resolve(ctx, root)
if err != nil {
return err
}
if !exists {
return fmt.Errorf("%w:%v", ErrMissing, root)
}
var r Root
if err := json.Unmarshal(rb, &r); err != nil {
return err
}
// Use small file optimization
if contentLen := len(r.Contents); contentLen > 0 {
if _, err := f.Write(r.Contents); err != nil {
return err
}
color.Yellow("downloaded root=%v size=%fKB", root, float64(contentLen)/units.KiB)
return nil
}
if len(r.Children) == 0 {
return ErrEmpty
}
amountDownloaded := 0
for _, h := range r.Children {
exists, b, _, err := cli.Resolve(ctx, h)
if err != nil {
return err
}
if !exists {
return fmt.Errorf("%w:%s", ErrMissing, h)
}
if _, err := f.Write(b); err != nil {
return err
}
size := len(b)
color.Yellow("downloaded chunk=%v size=%fKB", h, float64(size)/units.KiB)
amountDownloaded += size
}
color.Yellow("download complete root=%v size=%fMB", root, float64(amountDownloaded)/units.MiB)
return nil
}
```
#### Example 2
```bash
blob-cli resolve-file 6fe5a52f52b34fb1e07ba90bad47811c645176d0d49ef0c7a7b4b22013f676c8 computer_copy.gif
```
## Conclusion
This documentation covers concepts about Virtual Machine by walking through a VM that implements a decentralized key-value store.
You can learn more about the BlobVM by referencing the [README](https://github.com/ava-labs/blobvm/blob/master/README.md) in the GitHub repository.
# Simple Golang VM
URL: /docs/virtual-machines/golang-vms/simple-golang-vm
In this tutorial, we will learn how to build a virtual machine by referencing the TimestampVM.
In this tutorial, we'll create a very simple VM called the [TimestampVM](https://github.com/ava-labs/timestampvm/tree/v1.2.1). Each block in the TimestampVM's blockchain contains a strictly increasing timestamp when the block was created and a 32-byte payload of data.
Such a server is useful because it can be used to prove a piece of data existed at the time the block was created. Suppose you have a book manuscript, and you want to be able to prove in the future that the manuscript exists today. You can add a block to the blockchain where the block's payload is a hash of your manuscript. In the future, you can prove that the manuscript existed today by showing that the block has the hash of your manuscript in its payload (this follows from the fact that finding the pre-image of a hash is impossible).
## TimestampVM Implementation
Now we know the interface our VM must implement and the libraries we can use to build a VM.
Let's write our VM, which implements `block.ChainVM` and whose blocks implement `snowman.Block`. You can also follow the code in the [TimestampVM repository](https://github.com/ava-labs/timestampvm/tree/main).
### Codec
`Codec` is required to encode/decode the block into byte representation. TimestampVM uses the default codec and manager.
```go title="timestampvm/codec.go"
const (
// CodecVersion is the current default codec version
CodecVersion = 0
)
// Codecs do serialization and deserialization
var (
Codec codec.Manager
)
func init() {
// Create default codec and manager
c := linearcodec.NewDefault()
Codec = codec.NewDefaultManager()
// Register codec to manager with CodecVersion
if err := Codec.RegisterCodec(CodecVersion, c); err != nil {
panic(err)
}
}
```
### State
The `State` interface defines the database layer and connections. Each VM should define their own database methods. `State` embeds the `BlockState` which defines block-related state operations.
```go title="timestampvm/state.go"
var (
// These are prefixes for db keys.
// It's important to set different prefixes for each separate database objects.
singletonStatePrefix = []byte("singleton")
blockStatePrefix = []byte("block")
_ State = &state{}
)
// State is a wrapper around avax.SingleTonState and BlockState
// State also exposes a few methods needed for managing database commits and close.
type State interface {
// SingletonState is defined in avalanchego,
// it is used to understand if db is initialized already.
avax.SingletonState
BlockState
Commit() error
Close() error
}
type state struct {
avax.SingletonState
BlockState
baseDB *versiondb.Database
}
func NewState(db database.Database, vm *VM) State {
// create a new baseDB
baseDB := versiondb.New(db)
// create a prefixed "blockDB" from baseDB
blockDB := prefixdb.New(blockStatePrefix, baseDB)
// create a prefixed "singletonDB" from baseDB
singletonDB := prefixdb.New(singletonStatePrefix, baseDB)
// return state with created sub state components
return &state{
BlockState: NewBlockState(blockDB, vm),
SingletonState: avax.NewSingletonState(singletonDB),
baseDB: baseDB,
}
}
// Commit commits pending operations to baseDB
func (s *state) Commit() error {
return s.baseDB.Commit()
}
// Close closes the underlying base database
func (s *state) Close() error {
return s.baseDB.Close()
}
```
#### Block State
This interface and implementation provides storage functions to VM to store and retrieve blocks.
```go title="timestampvm/block_state.go"
const (
lastAcceptedByte byte = iota
)
const (
// maximum block capacity of the cache
blockCacheSize = 8192
)
// persists lastAccepted block IDs with this key
var lastAcceptedKey = []byte{lastAcceptedByte}
var _ BlockState = &blockState{}
// BlockState defines methods to manage state with Blocks and LastAcceptedIDs.
type BlockState interface {
GetBlock(blkID ids.ID) (*Block, error)
PutBlock(blk *Block) error
GetLastAccepted() (ids.ID, error)
SetLastAccepted(ids.ID) error
}
// blockState implements BlocksState interface with database and cache.
type blockState struct {
// cache to store blocks
blkCache cache.Cacher
// block database
blockDB database.Database
lastAccepted ids.ID
// vm reference
vm *VM
}
// blkWrapper wraps the actual blk bytes and status to persist them together
type blkWrapper struct {
Blk []byte `serialize:"true"`
Status choices.Status `serialize:"true"`
}
// NewBlockState returns BlockState with a new cache and given db
func NewBlockState(db database.Database, vm *VM) BlockState {
return &blockState{
blkCache: &cache.LRU{Size: blockCacheSize},
blockDB: db,
vm: vm,
}
}
// GetBlock gets Block from either cache or database
func (s *blockState) GetBlock(blkID ids.ID) (*Block, error) {
// Check if cache has this blkID
if blkIntf, cached := s.blkCache.Get(blkID); cached {
// there is a key but value is nil, so return an error
if blkIntf == nil {
return nil, database.ErrNotFound
}
// We found it return the block in cache
return blkIntf.(*Block), nil
}
// get block bytes from db with the blkID key
wrappedBytes, err := s.blockDB.Get(blkID[:])
if err != nil {
// we could not find it in the db, let's cache this blkID with nil value
// so next time we try to fetch the same key we can return error
// without hitting the database
if err == database.ErrNotFound {
s.blkCache.Put(blkID, nil)
}
// could not find the block, return error
return nil, err
}
// first decode/unmarshal the block wrapper so we can have status and block bytes
blkw := blkWrapper{}
if _, err := Codec.Unmarshal(wrappedBytes, &blkw); err != nil {
return nil, err
}
// now decode/unmarshal the actual block bytes to block
blk := &Block{}
if _, err := Codec.Unmarshal(blkw.Blk, blk); err != nil {
return nil, err
}
// initialize block with block bytes, status and vm
blk.Initialize(blkw.Blk, blkw.Status, s.vm)
// put block into cache
s.blkCache.Put(blkID, blk)
return blk, nil
}
// PutBlock puts block into both database and cache
func (s *blockState) PutBlock(blk *Block) error {
// create block wrapper with block bytes and status
blkw := blkWrapper{
Blk: blk.Bytes(),
Status: blk.Status(),
}
// encode block wrapper to its byte representation
wrappedBytes, err := Codec.Marshal(CodecVersion, &blkw)
if err != nil {
return err
}
blkID := blk.ID()
// put actual block to cache, so we can directly fetch it from cache
s.blkCache.Put(blkID, blk)
// put wrapped block bytes into database
return s.blockDB.Put(blkID[:], wrappedBytes)
}
// DeleteBlock deletes block from both cache and database
func (s *blockState) DeleteBlock(blkID ids.ID) error {
s.blkCache.Put(blkID, nil)
return s.blockDB.Delete(blkID[:])
}
// GetLastAccepted returns last accepted block ID
func (s *blockState) GetLastAccepted() (ids.ID, error) {
// check if we already have lastAccepted ID in state memory
if s.lastAccepted != ids.Empty {
return s.lastAccepted, nil
}
// get lastAccepted bytes from database with the fixed lastAcceptedKey
lastAcceptedBytes, err := s.blockDB.Get(lastAcceptedKey)
if err != nil {
return ids.ID{}, err
}
// parse bytes to ID
lastAccepted, err := ids.ToID(lastAcceptedBytes)
if err != nil {
return ids.ID{}, err
}
// put lastAccepted ID into memory
s.lastAccepted = lastAccepted
return lastAccepted, nil
}
// SetLastAccepted persists lastAccepted ID into both cache and database
func (s *blockState) SetLastAccepted(lastAccepted ids.ID) error {
// if the ID in memory and the given memory are same don't do anything
if s.lastAccepted == lastAccepted {
return nil
}
// put lastAccepted ID to memory
s.lastAccepted = lastAccepted
// persist lastAccepted ID to database with fixed lastAcceptedKey
return s.blockDB.Put(lastAcceptedKey, lastAccepted[:])
}
```
### Block
Let's look at our block implementation. The type declaration is:
```go title="timestampvm/block.go"
// Block is a block on the chain.
// Each block contains:
// 1) ParentID
// 2) Height
// 3) Timestamp
// 4) A piece of data (a string)
type Block struct {
PrntID ids.ID `serialize:"true" json:"parentID"` // parent's ID
Hght uint64 `serialize:"true" json:"height"` // This block's height. The genesis block is at height 0.
Tmstmp int64 `serialize:"true" json:"timestamp"` // Time this block was proposed at
Dt [dataLen]byte `serialize:"true" json:"data"` // Arbitrary data
id ids.ID // hold this block's ID
bytes []byte // this block's encoded bytes
status choices.Status // block's status
vm *VM // the underlying VM reference, mostly used for state
}
```
The `serialize:"true"` tag indicates that the field should be included in the byte representation of the block used when persisting the block or sending it to other nodes.
#### Verify
This method verifies that a block is valid and stores it in the memory. It is important to store the verified block in the memory and return them in the `vm.GetBlock` method.
```go title="timestampvm/block.go"
// Verify returns nil iff this block is valid.
// To be valid, it must be that:
// b.parent.Timestamp < b.Timestamp <= [local time] + 1 hour
func (b *Block) Verify() error {
// Get [b]'s parent
parentID := b.Parent()
parent, err := b.vm.getBlock(parentID)
if err != nil {
return errDatabaseGet
}
// Ensure [b]'s height comes right after its parent's height
if expectedHeight := parent.Height() + 1; expectedHeight != b.Hght {
return fmt.Errorf(
"expected block to have height %d, but found %d",
expectedHeight,
b.Hght,
)
}
// Ensure [b]'s timestamp is after its parent's timestamp.
if b.Timestamp().Unix() < parent.Timestamp().Unix() {
return errTimestampTooEarly
}
// Ensure [b]'s timestamp is not more than an hour
// ahead of this node's time
if b.Timestamp().Unix() >= time.Now().Add(time.Hour).Unix() {
return errTimestampTooLate
}
// Put that block to verified blocks in memory
b.vm.verifiedBlocks[b.ID()] = b
return nil
}
```
#### Accept
`Accept` is called by the consensus to indicate this block is accepted.
```go title="timestampvm/block.go"
// Accept sets this block's status to Accepted and sets lastAccepted to this
// block's ID and saves this info to b.vm.DB
func (b *Block) Accept() error {
b.SetStatus(choices.Accepted) // Change state of this block
blkID := b.ID()
// Persist data
if err := b.vm.state.PutBlock(b); err != nil {
return err
}
// Set last accepted ID to this block ID
if err := b.vm.state.SetLastAccepted(blkID); err != nil {
return err
}
// Delete this block from verified blocks as it's accepted
delete(b.vm.verifiedBlocks, b.ID())
// Commit changes to database
return b.vm.state.Commit()
}
```
#### Reject
`Reject` is called by the consensus to indicate this block is rejected.
```go title="timestampvm/block.go"
// Reject sets this block's status to Rejected and saves the status in state
// Recall that b.vm.DB.Commit() must be called to persist to the DB
func (b *Block) Reject() error {
b.SetStatus(choices.Rejected) // Change state of this block
if err := b.vm.state.PutBlock(b); err != nil {
return err
}
// Delete this block from verified blocks as it's rejected
delete(b.vm.verifiedBlocks, b.ID())
// Commit changes to database
return b.vm.state.Commit()
}
```
#### Block Field Methods
These methods are required by the `snowman.Block` interface.
```go title="timestampvm/block.go"
// ID returns the ID of this block
func (b *Block) ID() ids.ID { return b.id }
// ParentID returns [b]'s parent's ID
func (b *Block) Parent() ids.ID { return b.PrntID }
// Height returns this block's height. The genesis block has height 0.
func (b *Block) Height() uint64 { return b.Hght }
// Timestamp returns this block's time. The genesis block has time 0.
func (b *Block) Timestamp() time.Time { return time.Unix(b.Tmstmp, 0) }
// Status returns the status of this block
func (b *Block) Status() choices.Status { return b.status }
// Bytes returns the byte repr. of this block
func (b *Block) Bytes() []byte { return b.bytes }
```
#### Helper Functions
These methods are convenience methods for blocks, they're not a part of the block interface.
```go
// Initialize sets [b.bytes] to [bytes], [b.id] to hash([b.bytes]),
// [b.status] to [status] and [b.vm] to [vm]
func (b *Block) Initialize(bytes []byte, status choices.Status, vm *VM) {
b.bytes = bytes
b.id = hashing.ComputeHash256Array(b.bytes)
b.status = status
b.vm = vm
}
// SetStatus sets the status of this block
func (b *Block) SetStatus(status choices.Status) { b.status = status }
```
### Virtual Machine
Now, let's look at our timestamp VM implementation, which implements the `block.ChainVM` interface. The declaration is:
```go title="timestampvm/vm.go"
// This Virtual Machine defines a blockchain that acts as a timestamp server
// Each block contains data (a payload) and the timestamp when it was created
const (
dataLen = 32
Name = "timestampvm"
)
// VM implements the snowman.VM interface
// Each block in this chain contains a Unix timestamp
// and a piece of data (a string)
type VM struct {
// The context of this vm
ctx *snow.Context
dbManager manager.Manager
// State of this VM
state State
// ID of the preferred block
preferred ids.ID
// channel to send messages to the consensus engine
toEngine chan<- common.Message
// Proposed pieces of data that haven't been put into a block and proposed yet
mempool [][dataLen]byte
// Block ID --> Block
// Each element is a block that passed verification but
// hasn't yet been accepted/rejected
verifiedBlocks map[ids.ID]*Block
}
```
#### Initialize
This method is called when a new instance of VM is initialized. Genesis block is created under this method.
```go title="timestampvm/vm.go"
// Initialize this vm
// [ctx] is this vm's context
// [dbManager] is the manager of this vm's database
// [toEngine] is used to notify the consensus engine that new blocks are
// ready to be added to consensus
// The data in the genesis block is [genesisData]
func (vm *VM) Initialize(
ctx *snow.Context,
dbManager manager.Manager,
genesisData []byte,
upgradeData []byte,
configData []byte,
toEngine chan<- common.Message,
_ []*common.Fx,
_ common.AppSender,
) error {
version, err := vm.Version()
if err != nil {
log.Error("error initializing Timestamp VM: %v", err)
return err
}
log.Info("Initializing Timestamp VM", "Version", version)
vm.dbManager = dbManager
vm.ctx = ctx
vm.toEngine = toEngine
vm.verifiedBlocks = make(map[ids.ID]*Block)
// Create new state
vm.state = NewState(vm.dbManager.Current().Database, vm)
// Initialize genesis
if err := vm.initGenesis(genesisData); err != nil {
return err
}
// Get last accepted
lastAccepted, err := vm.state.GetLastAccepted()
if err != nil {
return err
}
ctx.Log.Info("initializing last accepted block as %s", lastAccepted)
// Build off the most recently accepted block
return vm.SetPreference(lastAccepted)
}
```
#### `initGenesis`
`initGenesis` is a helper method which initializes the genesis block from given bytes and puts into the state.
```go title="timestampvm/vm.go"
// Initializes Genesis if required
func (vm *VM) initGenesis(genesisData []byte) error {
stateInitialized, err := vm.state.IsInitialized()
if err != nil {
return err
}
// if state is already initialized, skip init genesis.
if stateInitialized {
return nil
}
if len(genesisData) > dataLen {
return errBadGenesisBytes
}
// genesisData is a byte slice but each block contains an byte array
// Take the first [dataLen] bytes from genesisData and put them in an array
var genesisDataArr [dataLen]byte
copy(genesisDataArr[:], genesisData)
// Create the genesis block
// Timestamp of genesis block is 0. It has no parent.
genesisBlock, err := vm.NewBlock(ids.Empty, 0, genesisDataArr, time.Unix(0, 0))
if err != nil {
log.Error("error while creating genesis block: %v", err)
return err
}
// Put genesis block to state
if err := vm.state.PutBlock(genesisBlock); err != nil {
log.Error("error while saving genesis block: %v", err)
return err
}
// Accept the genesis block
// Sets [vm.lastAccepted] and [vm.preferred]
if err := genesisBlock.Accept(); err != nil {
return fmt.Errorf("error accepting genesis block: %w", err)
}
// Mark this vm's state as initialized, so we can skip initGenesis in further restarts
if err := vm.state.SetInitialized(); err != nil {
return fmt.Errorf("error while setting db to initialized: %w", err)
}
// Flush VM's database to underlying db
return vm.state.Commit()
}
```
#### CreateHandlers
Registered handlers defined in `Service`. See [below](/docs/virtual-machines/golang-vms/simple-golang-vm#api) for more on APIs.
```go title="timestampvm/vm.go"
// CreateHandlers returns a map where:
// Keys: The path extension for this blockchain's API (empty in this case)
// Values: The handler for the API
// In this case, our blockchain has only one API, which we name timestamp,
// and it has no path extension, so the API endpoint:
// [Node IP]/ext/bc/[this blockchain's ID]
// See API section in documentation for more information
func (vm *VM) CreateHandlers() (map[string]*common.HTTPHandler, error) {
server := rpc.NewServer()
server.RegisterCodec(json.NewCodec(), "application/json")
server.RegisterCodec(json.NewCodec(), "application/json;charset=UTF-8")
// Name is "timestampvm"
if err := server.RegisterService(&Service{vm: vm}, Name); err != nil {
return nil, err
}
return map[string]*common.HTTPHandler{
"": {
Handler: server,
},
}, nil
}
```
#### CreateStaticHandlers
Registers static handlers defined in `StaticService`. See [below](/docs/virtual-machines/golang-vms/simple-golang-vm#static-api) for more on static APIs.
```go title="timestampvm/vm.go"
// CreateStaticHandlers returns a map where:
// Keys: The path extension for this VM's static API
// Values: The handler for that static API
func (vm *VM) CreateStaticHandlers() (map[string]*common.HTTPHandler, error) {
server := rpc.NewServer()
server.RegisterCodec(json.NewCodec(), "application/json")
server.RegisterCodec(json.NewCodec(), "application/json;charset=UTF-8")
if err := server.RegisterService(&StaticService{}, Name); err != nil {
return nil, err
}
return map[string]*common.HTTPHandler{
"": {
LockOptions: common.NoLock,
Handler: server,
},
}, nil
}
```
#### BuildBock
`BuildBlock` builds a new block and returns it. This is mainly requested by the consensus engine.
```go title="timestampvm/vm.go"
// BuildBlock returns a block that this vm wants to add to consensus
func (vm *VM) BuildBlock() (snowman.Block, error) {
if len(vm.mempool) == 0 { // There is no block to be built
return nil, errNoPendingBlocks
}
// Get the value to put in the new block
value := vm.mempool[0]
vm.mempool = vm.mempool[1:]
// Notify consensus engine that there are more pending data for blocks
// (if that is the case) when done building this block
if len(vm.mempool) > 0 {
defer vm.NotifyBlockReady()
}
// Gets Preferred Block
preferredBlock, err := vm.getBlock(vm.preferred)
if err != nil {
return nil, fmt.Errorf("couldn't get preferred block: %w", err)
}
preferredHeight := preferredBlock.Height()
// Build the block with preferred height
newBlock, err := vm.NewBlock(vm.preferred, preferredHeight+1, value, time.Now())
if err != nil {
return nil, fmt.Errorf("couldn't build block: %w", err)
}
// Verifies block
if err := newBlock.Verify(); err != nil {
return nil, err
}
return newBlock, nil
}
```
#### NotifyBlockReady
`NotifyBlockReady` is a helper method that can send messages to the consensus engine through `toEngine` channel.
```go title="timestampvm/vm.go"
// NotifyBlockReady tells the consensus engine that a new block
// is ready to be created
func (vm *VM) NotifyBlockReady() {
select {
case vm.toEngine <- common.PendingTxs:
default:
vm.ctx.Log.Debug("dropping message to consensus engine")
}
}
```
#### GetBlock
`GetBlock` returns the block with the given block ID.
```go title="timestampvm/vm.go"
// GetBlock implements the snowman.ChainVM interface
func (vm *VM) GetBlock(blkID ids.ID) (snowman.Block, error) { return vm.getBlock(blkID) }
func (vm *VM) getBlock(blkID ids.ID) (*Block, error) {
// If block is in memory, return it.
if blk, exists := vm.verifiedBlocks[blkID]; exists {
return blk, nil
}
return vm.state.GetBlock(blkID)
}
```
#### `proposeBlock`
This method adds a piece of data to the mempool and notifies the consensus layer of the blockchain that a new block is ready to be built and voted on. This is called by API method `ProposeBlock`, which we'll see later.
```go title="timestampvm/vm.go"
// proposeBlock appends [data] to [p.mempool].
// Then it notifies the consensus engine
// that a new block is ready to be added to consensus
// (namely, a block with data [data])
func (vm *VM) proposeBlock(data [dataLen]byte) {
vm.mempool = append(vm.mempool, data)
vm.NotifyBlockReady()
}
```
#### ParseBlock
Parse a block from its byte representation.
```go title="timestampvm/vm.go"
// ParseBlock parses [bytes] to a snowman.Block
// This function is used by the vm's state to unmarshal blocks saved in state
// and by the consensus layer when it receives the byte representation of a block
// from another node
func (vm *VM) ParseBlock(bytes []byte) (snowman.Block, error) {
// A new empty block
block := &Block{}
// Unmarshal the byte repr. of the block into our empty block
_, err := Codec.Unmarshal(bytes, block)
if err != nil {
return nil, err
}
// Initialize the block
block.Initialize(bytes, choices.Processing, vm)
if blk, err := vm.getBlock(block.ID()); err == nil {
// If we have seen this block before, return it with the most up-to-date
// info
return blk, nil
}
// Return the block
return block, nil
}
```
#### NewBlock
`NewBlock` creates a new block with given block parameters.
```go title="timestampvm/vm.go"
// NewBlock returns a new Block where:
// - the block's parent is [parentID]
// - the block's data is [data]
// - the block's timestamp is [timestamp]
func (vm *VM) NewBlock(parentID ids.ID, height uint64, data [dataLen]byte, timestamp time.Time) (*Block, error) {
block := &Block{
PrntID: parentID,
Hght: height,
Tmstmp: timestamp.Unix(),
Dt: data,
}
// Get the byte representation of the block
blockBytes, err := Codec.Marshal(CodecVersion, block)
if err != nil {
return nil, err
}
// Initialize the block by providing it with its byte representation
// and a reference to this VM
block.Initialize(blockBytes, choices.Processing, vm)
return block, nil
}
```
#### SetPreference
`SetPreference` implements the `block.ChainVM`. It sets the preferred block ID.
```go title="timestampvm/vm.go"
// SetPreference sets the block with ID [ID] as the preferred block
func (vm *VM) SetPreference(id ids.ID) error {
vm.preferred = id
return nil
}
```
#### Other Functions
These functions needs to be implemented for `block.ChainVM`. Most of them are just blank functions returning `nil`.
```go title="timestampvm/vm.go"
// Bootstrapped marks this VM as bootstrapped
func (vm *VM) Bootstrapped() error { return nil }
// Bootstrapping marks this VM as bootstrapping
func (vm *VM) Bootstrapping() error { return nil }
// Returns this VM's version
func (vm *VM) Version() (string, error) {
return Version.String(), nil
}
func (vm *VM) Connected(id ids.ShortID, nodeVersion version.Application) error {
return nil // noop
}
func (vm *VM) Disconnected(id ids.ShortID) error {
return nil // noop
}
// This VM doesn't (currently) have any app-specific messages
func (vm *VM) AppGossip(nodeID ids.ShortID, msg []byte) error {
return nil
}
// This VM doesn't (currently) have any app-specific messages
func (vm *VM) AppRequest(nodeID ids.ShortID, requestID uint32, time time.Time, request []byte) error {
return nil
}
// This VM doesn't (currently) have any app-specific messages
func (vm *VM) AppResponse(nodeID ids.ShortID, requestID uint32, response []byte) error {
return nil
}
// This VM doesn't (currently) have any app-specific messages
func (vm *VM) AppRequestFailed(nodeID ids.ShortID, requestID uint32) error {
return nil
}
// Health implements the common.VM interface
func (vm *VM) HealthCheck() (interface{}, error) { return nil, nil }
```
### Factory
VMs should implement the `Factory` interface. `New` method in the interface returns a new VM instance.
```go title="timestampvm/factory.go"
var _ vms.Factory = &Factory{}
// Factory ...
type Factory struct{}
// New ...
func (f *Factory) New(*snow.Context) (interface{}, error) { return &VM{}, nil }
```
### Static API
A VM may have a static API, which allows clients to call methods that do not query or update the state of a particular blockchain, but rather apply to the VM as a whole. This is analogous to static methods in computer programming. AvalancheGo uses [Gorilla's RPC library](https://www.gorillatoolkit.org/pkg/rpc) to implement HTTP APIs. `StaticService` implements the static API for our VM.
```go title="timestampvm/static_service.go"
// StaticService defines the static API for the timestamp vm
type StaticService struct{}
```
#### Encode
For each API method, there is:
* A struct that defines the method's arguments
* A struct that defines the method's return values
* A method that implements the API method, and is parameterized on the above 2 structs
This API method encodes a string to its byte representation using a given encoding scheme. It can be used to encode data that is then put in a block and proposed as the next block for this chain.
```go title="timestampvm/static_service.go"
// EncodeArgs are arguments for Encode
type EncodeArgs struct {
Data string `json:"data"`
Encoding formatting.Encoding `json:"encoding"`
Length int32 `json:"length"`
}
// EncodeReply is the reply from Encoder
type EncodeReply struct {
Bytes string `json:"bytes"`
Encoding formatting.Encoding `json:"encoding"`
}
// Encoder returns the encoded data
func (ss *StaticService) Encode(_ *http.Request, args *EncodeArgs, reply *EncodeReply) error {
if len(args.Data) == 0 {
return fmt.Errorf("argument Data cannot be empty")
}
var argBytes []byte
if args.Length > 0 {
argBytes = make([]byte, args.Length)
copy(argBytes, args.Data)
} else {
argBytes = []byte(args.Data)
}
bytes, err := formatting.EncodeWithChecksum(args.Encoding, argBytes)
if err != nil {
return fmt.Errorf("couldn't encode data as string: %s", err)
}
reply.Bytes = bytes
reply.Encoding = args.Encoding
return nil
}
```
#### Decode
This API method is the inverse of `Encode`.
```go title="timestampvm/static_service.go"
// DecoderArgs are arguments for Decode
type DecoderArgs struct {
Bytes string `json:"bytes"`
Encoding formatting.Encoding `json:"encoding"`
}
// DecoderReply is the reply from Decoder
type DecoderReply struct {
Data string `json:"data"`
Encoding formatting.Encoding `json:"encoding"`
}
// Decoder returns the Decoded data
func (ss *StaticService) Decode(_ *http.Request, args *DecoderArgs, reply *DecoderReply) error {
bytes, err := formatting.Decode(args.Encoding, args.Bytes)
if err != nil {
return fmt.Errorf("couldn't Decode data as string: %s", err)
}
reply.Data = string(bytes)
reply.Encoding = args.Encoding
return nil
}
```
### API
A VM may also have a non-static HTTP API, which allows clients to query and update the blockchain's state. `Service`'s declaration is:
```go title="timestampvm/service.go"
// Service is the API service for this VM
type Service struct{ vm *VM }
```
Note that this struct has a reference to the VM, so it can query and update state.
This VM's API has two methods. One allows a client to get a block by its ID. The other allows a client to propose the next block of this blockchain. The blockchain ID in the endpoint changes, since every blockchain has an unique ID.
#### `timestampvm.getBlock`
Get a block by its ID. If no ID is provided, get the latest block.
##### `getBlock` Signature
```
timestampvm.getBlock({id: string}) ->
{
id: string,
data: string,
timestamp: int,
parentID: string
}
```
* `id` is the ID of the block being retrieved. If omitted from arguments, gets the latest block
* `data` is the base 58 (with checksum) representation of the block's 32 byte payload
* `timestamp` is the Unix timestamp when this block was created
* `parentID` is the block's parent
##### `getBlock` Example Call
```bash
curl -X POST --data '{
"jsonrpc": "2.0",
"method": "timestampvm.getBlock",
"params":{
"id":"xqQV1jDnCXDxhfnNT7tDBcXeoH2jC3Hh7Pyv4GXE1z1hfup5K"
},
"id": 1
}' -H 'content-type:application/json;' 127.0.0.1:9650/ext/bc/sw813hGSWH8pdU9uzaYy9fCtYFfY7AjDd2c9rm64SbApnvjmk
```
##### `getBlock` Example Response
```json
{
"jsonrpc": "2.0",
"result": {
"timestamp": "1581717416",
"data": "11111111111111111111111111111111LpoYY",
"id": "xqQV1jDnCXDxhfnNT7tDBcXeoH2jC3Hh7Pyv4GXE1z1hfup5K",
"parentID": "22XLgiM5dfCwTY9iZnVk8ZPuPe3aSrdVr5Dfrbxd3ejpJd7oef"
},
"id": 1
}
```
##### `getBlock` Implementation
```go title="timestampvm/service.go"
// GetBlockArgs are the arguments to GetBlock
type GetBlockArgs struct {
// ID of the block we're getting.
// If left blank, gets the latest block
ID *ids.ID `json:"id"`
}
// GetBlockReply is the reply from GetBlock
type GetBlockReply struct {
Timestamp json.Uint64 `json:"timestamp"` // Timestamp of most recent block
Data string `json:"data"` // Data in the most recent block. Base 58 repr. of 5 bytes.
ID ids.ID `json:"id"` // String repr. of ID of the most recent block
ParentID ids.ID `json:"parentID"` // String repr. of ID of the most recent block's parent
}
// GetBlock gets the block whose ID is [args.ID]
// If [args.ID] is empty, get the latest block
func (s *Service) GetBlock(_ *http.Request, args *GetBlockArgs, reply *GetBlockReply) error {
// If an ID is given, parse its string representation to an ids.ID
// If no ID is given, ID becomes the ID of last accepted block
var (
id ids.ID
err error
)
if args.ID == nil {
id, err = s.vm.state.GetLastAccepted()
if err != nil {
return errCannotGetLastAccepted
}
} else {
id = *args.ID
}
// Get the block from the database
block, err := s.vm.getBlock(id)
if err != nil {
return errNoSuchBlock
}
// Fill out the response with the block's data
reply.ID = block.ID()
reply.Timestamp = json.Uint64(block.Timestamp().Unix())
reply.ParentID = block.Parent()
data := block.Data()
reply.Data, err = formatting.EncodeWithChecksum(formatting.CB58, data[:])
return err
}
```
#### `timestampvm.proposeBlock`
Propose the next block on this blockchain.
##### `proposeBlock` Signature
```go
timestampvm.proposeBlock({data: string}) -> {success: bool}
```
* `data` is the base 58 (with checksum) representation of the proposed block's 32 byte payload.
##### `proposeBlock` Example Call
```bash
curl -X POST --data '{
"jsonrpc": "2.0",
"method": "timestampvm.proposeBlock",
"params":{
"data":"SkB92YpWm4Q2iPnLGCuDPZPgUQMxajqQQuz91oi3xD984f8r"
},
"id": 1
}' -H 'content-type:application/json;' 127.0.0.1:9650/ext/bc/sw813hGSWH8pdU9uzaYy9fCtYFfY7AjDd2c9rm64SbApnvjmk
```
###### `proposeBlock` Example Response
```json
{
"jsonrpc": "2.0",
"result": {
"Success": true
},
"id": 1
}
```
##### `proposeBlock` Implementation
```go title="timestampvm/service.go"
// ProposeBlockArgs are the arguments to ProposeValue
type ProposeBlockArgs struct {
// Data for the new block. Must be base 58 encoding (with checksum) of 32 bytes.
Data string
}
// ProposeBlockReply is the reply from function ProposeBlock
type ProposeBlockReply struct{
// True if the operation was successful
Success bool
}
// ProposeBlock is an API method to propose a new block whose data is [args].Data.
// [args].Data must be a string repr. of a 32 byte array
func (s *Service) ProposeBlock(_ *http.Request, args *ProposeBlockArgs, reply *ProposeBlockReply) error {
bytes, err := formatting.Decode(formatting.CB58, args.Data)
if err != nil || len(bytes) != dataLen {
return errBadData
}
var data [dataLen]byte // The data as an array of bytes
copy(data[:], bytes[:dataLen]) // Copy the bytes in dataSlice to data
s.vm.proposeBlock(data)
reply.Success = true
return nil
}
```
### Plugin
In order to make this VM compatible with `go-plugin`, we need to define a `main` package and method, which serves our VM over gRPC so that AvalancheGo can call its methods. `main.go`'s contents are:
```go title="main/main.go"
func main() {
log.Root().SetHandler(log.LvlFilterHandler(log.LvlDebug, log.StreamHandler(os.Stderr, log.TerminalFormat())))
plugin.Serve(&plugin.ServeConfig{
HandshakeConfig: rpcchainvm.Handshake,
Plugins: map[string]plugin.Plugin{
"vm": rpcchainvm.New(×tampvm.VM{}),
},
// A non-nil value here enables gRPC serving for this plugin...
GRPCServer: plugin.DefaultGRPCServer,
})
}
```
Now AvalancheGo's `rpcchainvm` can connect to this plugin and calls its methods.
### Executable Binary
This VM has a [build script](https://github.com/ava-labs/timestampvm/blob/v1.2.1/scripts/build.sh) that builds an executable of this VM (when invoked, it runs the `main` method from above.)
The path to the executable, as well as its name, can be provided to the build script via arguments. For example:
```bash
./scripts/build.sh ../avalanchego/build/plugins timestampvm
```
If no argument is given, the path defaults to a binary named with default VM ID: `$GOPATH/src/github.com/ava-labs/avalanchego/build/plugins/tGas3T58KzdjLHhBDMnH2TvrddhqTji5iZAMZ3RXs2NLpSnhH`
This name `tGas3T58KzdjLHhBDMnH2TvrddhqTji5iZAMZ3RXs2NLpSnhH` is the CB58 encoded 32 byte identifier for the VM. For the timestampvm, this is the string "timestamp" zero-extended in a 32 byte array and encoded in CB58.
### VM Aliases
Each VM has a predefined, static ID. For instance, the default ID of the TimestampVM is: `tGas3T58KzdjLHhBDMnH2TvrddhqTji5iZAMZ3RXs2NLpSnhH`.
It's possible to give an alias for these IDs. For example, we can alias `TimestampVM` by creating a JSON file at `~/.avalanchego/configs/vms/aliases.json` with:
The name of the VM binary is also its static ID and should not be changed manually. Changing the name of the VM binary will result in AvalancheGo failing to start the VM. To reference a VM by another name, define a VM alias as described below.
```json
{
"tGas3T58KzdjLHhBDMnH2TvrddhqTji5iZAMZ3RXs2NLpSnhH": [
"timestampvm",
"timestamp"
]
}
```
### Installing a VM
AvalancheGo searches for and registers plugins under the `plugins` [directory](/docs/nodes/configure/configs-flags#--plugin-dir-string).
To install the virtual machine onto your node, you need to move the built virtual machine binary under this directory. Virtual machine executable names must be either a full virtual machine ID (encoded in CB58), or a VM alias.
Copy the binary into the plugins directory.
```bash
cp -n $GOPATH/src/github.com/ava-labs/avalanchego/build/plugins/
```
#### Node Is Not Running
If your node isn't running yet, you can install all virtual machines under your `plugin` directory by starting the node.
#### Node Is Already Running
Load the binary with the `loadVMs` API.
```bash
curl -sX POST --data '{
"jsonrpc":"2.0",
"id" :1,
"method" :"admin.loadVMs",
"params" :{}
}' -H 'content-type:application/json;' 127.0.0.1:9650/ext/admin
```
Confirm the response of `loadVMs` contains the newly installed virtual machine `tGas3T58KzdjLHhBDMnH2TvrddhqTji5iZAMZ3RXs2NLpSnhH`. You'll see this virtual machine as well as any others that weren't already installed previously in the response.
```json
{
"jsonrpc": "2.0",
"result": {
"newVMs": {
"tGas3T58KzdjLHhBDMnH2TvrddhqTji5iZAMZ3RXs2NLpSnhH": [
"timestampvm",
"timestamp"
],
"spdxUxVJQbX85MGxMHbKw1sHxMnSqJ3QBzDyDYEP3h6TLuxqQ": []
}
},
"id": 1
}
```
Now, this VM's static API can be accessed at endpoints `/ext/vm/timestampvm` and `/ext/vm/timestamp`. For more details about VM configs, see [here](/docs/nodes/configure/configs-flags#virtual-machine-vm-configs).
In this tutorial, we used the VM's ID as the executable name to simplify the process. However, AvalancheGo would also accept `timestampvm` or `timestamp` since those are registered aliases in previous step.
## Wrapping Up
That's it! That's the entire implementation of a VM which defines a blockchain-based timestamp server.
In this tutorial, we learned:
* The `block.ChainVM` interface, which all VMs that define a linear chain must implement
* The `snowman.Block` interface, which all blocks that are part of a linear chain must implement
* The `rpcchainvm` type, which allows blockchains to run in their own processes.
* An actual implementation of `block.ChainVM` and `snowman.Block`.
# Background and Requirements
URL: /docs/virtual-machines/custom-precompiles/background-requirements
Learn about the background and requirements for customizing Ethereum Virtual Machine.
This is a brief overview of what this tutorial will cover.
* Write a Solidity interface
* Generate the precompile template
* Implement the precompile functions in Golang
* Write and run tests
Stateful precompiles are [alpha software](https://en.wikipedia.org/wiki/Software_release_life_cycle#Alpha). Build at your own risk.
In this tutorial, we used a branch based on Subnet-EVM version `v0.5.2`. You can find the branch [here](https://github.com/ava-labs/subnet-evm/tree/helloworld-official-tutorial-v2). The code in this branch is the same as Subnet-EVM except for the `precompile/contracts/helloworld` directory. The directory contains the code for the `HelloWorld` precompile. We will be using this precompile as an example to learn how to write a stateful precompile. The code in this branch can become outdated. You should always use the latest version of Subnet-EVM when you develop your own precompile.
## Precompile-EVM
Subnet-EVM precompiles can be registered from an external repo. This allows developer to build their precompiles without maintaining a fork of Subnet-EVM. The precompiles are then registered in the Subnet-EVM at build time.
The difference between using Subnet-EVM and Precompile-EVM is that with Subnet-EVM you can change EVM internals to interact with your precompiles. Such as changing fee structure, adding new opcodes, changing how to build a block, etc. With Precompile-EVM you can only add new stateful precompiles that can interact with the StateDB. Precompiles built with Precompile-EVM are still very powerful because it can directly access to the state and modify it.
There is a template repo for how to build a precompile with this way called [Precompile-EVM](https://github.com/ava-labs/precompile-evm). Both Subnet-EVM and Precompile-EVM share similar directory structures and common codes.
You can reference the Precompile-EVM PR that adds Hello World precompile [here](https://github.com/ava-labs/precompile-evm/pull/12).
## Requirements
This tutorial assumes familiarity with Golang and JavaScript.
Additionally, users should be deeply familiar with the EVM in order to understand its invariants since adding a Stateful Precompile modifies the EVM itself.
Here are some recommended resources to learn the ins and outs of the EVM:
* [The Ethereum Virtual Machine](https://github.com/ethereumbook/ethereumbook/blob/develop/13evm.asciidoc)
* [Precompiles in Solidity](https://medium.com/@rbkhmrcr/precompiles-solidity-e5d29bd428c4)
* [Deconstructing a Smart Contract](https://blog.openzeppelin.com/deconstructing-a-solidity-contract-part-i-introduction-832efd2d7737/)
* [Layout of State Variables in Storage](https://docs.soliditylang.org/en/v0.8.10/internals/layout_in_storage.html)
* [Layout in Memory](https://docs.soliditylang.org/en/v0.8.10/internals/layout_in_memory.html)
* [Layout of Call Data](https://docs.soliditylang.org/en/v0.8.10/internals/layout_in_calldata.html)
* [Contract ABI Specification](https://docs.soliditylang.org/en/v0.8.10/abi-spec.html)
* [Customizing the EVM with Stateful Precompiles](https://medium.com/avalancheavax/customizing-the-evm-with-stateful-precompiles-f44a34f39efd)
Please install the following before getting started.
First, install the latest version of Go. Follow the instructions [here](https://go.dev/doc/install). You can verify by running `go version`.
Set the `$GOPATH` environment variable properly for Go to look for Go Workspaces. Please read [this](https://go.dev/doc/gopath_code) for details. You can verify by running `echo $GOPATH`.
See [here](https://github.com/golang/go/wiki/SettingGOPATH) for instructions on setting the GOPATH based on system configurations.
As a few things will be installed into `$GOPATH/bin`, please make sure that `$GOPATH/bin` is in your `$PATH`, otherwise, you may get an error running the commands below. To do that, run the command: `export PATH=$PATH:$GOROOT/bin:$GOPATH/bin`
Download the following prerequisites into your `$GOPATH`:
* Git Clone the repository (Subnet-EVM or Precompile-EVM)
* Git Clone [AvalancheGo](https://github.com/ava-labs/avalanchego) repository
* Install [Avalanche Network Runner](/docs/tooling/avalanche-network-runner/introduction)
* Install [solc](https://github.com/ethereum/solc-js#usage-on-the-command-line)
* Install [Node.js and NPM](https://nodejs.org/en/download) For easy copy paste, use the below commands:
```bash
cd $GOPATH
mkdir -p src/github.com/ava-labs
cd src/github.com/ava-labs
```
Clone the repository:
```bash
git clone git@github.com:ava-labs/subnet-evm.git
```
Then run the following commands:
```bash
git clone git@github.com:ava-labs/avalanchego.git
curl -sSfL https://raw.githubusercontent.com/ava-labs/avalanche-network-runner/main/scripts/install.sh | sh -s
npm install -g solc
```
```bash
git clone git@github.com:ava-labs/precompile-evm.git
```
Alternatively you can use it as a template repo from github.
Then run the following commands:
```bash
git clone git@github.com:ava-labs/avalanchego.git
curl -sSfL https://raw.githubusercontent.com/ava-labs/avalanche-network-runner/main/scripts/install.sh | sh -s
npm install -g solc
```
## Complete Code
You can inspect example pull request for the complete code.
[Subnet-EVM Hello World Pull Request](https://github.com/ava-labs/subnet-evm/pull/565/)
[Precompile-EVM Hello World Pull Request](https://github.com/ava-labs/precompile-evm/pull/12/)
For a full-fledged example, you can also check out the [Reward Manager Precompile](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/precompile/contracts/rewardmanager/).
# Generating Your Precompile
URL: /docs/virtual-machines/custom-precompiles/create-precompile
In this section, we will go over the process for automatically generating the template code which you can configure accordingly for your stateful precompile.
First, we must create the Solidity interface that we want our precompile to implement. This will be the HelloWorld Interface. It will have two simple functions, `sayHello()`, `setGreeting()` and an event `GreetingChanged`. These two functions will demonstrate the getting and setting respectively of a value stored in the precompile's state space.
The `sayHello()` function is a `view` function, meaning it does not modify the state of the precompile and returns a string result. The `setGreeting()` function is a state changer function, meaning it modifies the state of the precompile. The `HelloWorld` interface inherits `IAllowList` interface to use the allow list functionality.
For this tutorial, we will be working in a new branch in Subnet-EVM/Precompile-EVM repo.
```bash
cd $GOPATH/src/github.com/ava-labs/subnet-evm
```
We will start off in this directory `./contracts/`:
```bash
cd contracts/
```
Create a new file called `IHelloWorld.sol` and copy and paste the below code:
```solidity title="contracts/IHelloWorld.sol"
// (c) 2022-2023, Ava Labs, Inc. All rights reserved.
// See the file LICENSE for licensing terms.
// SPDX-License-Identifier: MIT
pragma solidity >=0.8.0;
import "./IAllowList.sol";
interface IHelloWorld is IAllowList {
event GreetingChanged(
address indexed sender,
string oldGreeting,
string newGreeting
);
// sayHello returns the stored greeting string
function sayHello() external view returns (string calldata result);
// setGreeting stores the greeting string
function setGreeting(string calldata response) external;
}
```
Now we have an interface that our precompile can implement! Let's create an [ABI](https://docs.soliditylang.org/en/v0.8.13/abi-spec.html#contract-abi-specification) of our Solidity interface.
In the same directory, let's run:
```bash
solc --abi ./contracts/interfaces/IHelloWorld.sol -o ./abis
```
This generates the ABI code under `./abis/contracts_interfaces_IHelloWorld_sol_IHelloWorld.abi`.
```
[
{
"anonymous": false,
"inputs": [
{
"indexed": true,
"internalType": "address",
"name": "sender",
"type": "address"
},
{
"indexed": false,
"internalType": "string",
"name": "oldGreeting",
"type": "string"
},
{
"indexed": false,
"internalType": "string",
"name": "newGreeting",
"type": "string"
}
],
"name": "GreetingChanged",
"type": "event"
},
{
"anonymous": false,
"inputs": [
{
"indexed": true,
"internalType": "uint256",
"name": "role",
"type": "uint256"
},
{
"indexed": true,
"internalType": "address",
"name": "account",
"type": "address"
},
{
"indexed": true,
"internalType": "address",
"name": "sender",
"type": "address"
},
{
"indexed": false,
"internalType": "uint256",
"name": "oldRole",
"type": "uint256"
}
],
"name": "RoleSet",
"type": "event"
},
{
"inputs": [
{ "internalType": "address", "name": "addr", "type": "address" }
],
"name": "readAllowList",
"outputs": [
{ "internalType": "uint256", "name": "role", "type": "uint256" }
],
"stateMutability": "view",
"type": "function"
},
{
"inputs": [],
"name": "sayHello",
"outputs": [
{ "internalType": "string", "name": "result", "type": "string" }
],
"stateMutability": "view",
"type": "function"
},
{
"inputs": [
{ "internalType": "address", "name": "addr", "type": "address" }
],
"name": "setAdmin",
"outputs": [],
"stateMutability": "nonpayable",
"type": "function"
},
{
"inputs": [
{ "internalType": "address", "name": "addr", "type": "address" }
],
"name": "setEnabled",
"outputs": [],
"stateMutability": "nonpayable",
"type": "function"
},
{
"inputs": [
{ "internalType": "string", "name": "response", "type": "string" }
],
"name": "setGreeting",
"outputs": [],
"stateMutability": "nonpayable",
"type": "function"
},
{
"inputs": [
{ "internalType": "address", "name": "addr", "type": "address" }
],
"name": "setManager",
"outputs": [],
"stateMutability": "nonpayable",
"type": "function"
},
{
"inputs": [
{ "internalType": "address", "name": "addr", "type": "address" }
],
"name": "setNone",
"outputs": [],
"stateMutability": "nonpayable",
"type": "function"
}
]
```
As you can see the ABI also contains the `IAllowList` interface functions. This is because the `IHelloWorld` interface inherits from the `IAllowList` interface.
Note: The ABI must have named outputs in order to generate the precompile template.
Now that we have an ABI for the precompile gen tool to interact with, we can run the following command to generate our HelloWorld precompile files!
Let's go back to the root of the repository and run the PrecompileGen script helper:
```bash
cd ..
```
Both of these Subnet-EVM and Precompile-EVM have the same `generate_precompile.sh` script. The one in Precompile-EVM installs the script from Subnet-EVM and runs it.
```bash
./scripts/generate_precompile.sh --help
# output
Using branch: precompile-tutorial
NAME:
precompilegen - subnet-evm precompile generator tool
USAGE:
main [global options] command [command options] [arguments...]
VERSION:
1.10.26-stable
COMMANDS:
help, h Shows a list of commands or help for one command
GLOBAL OPTIONS:
--abi value
Path to the contract ABI json to generate, - for STDIN
--out value
Output folder for the generated precompile files, - for STDOUT (default =
./precompile/contracts/{pkg}). Test files won't be generated if STDOUT is used
--pkg value
Go package name to generate the precompile into (default = {type})
--type value
Struct name for the precompile (default = {abi file name})
MISC
--help, -h (default: false)
show help
--version, -v (default: false)
print the version
COPYRIGHT:
Copyright 2013-2022 The go-ethereum Authors
```
Now let's generate the precompile template files!
```bash
cd $GOPATH/src/github.com/ava-labs/precompile-evm
```
We will start off in this directory `./contracts/`:
```bash
cd contracts/
```
For Precompile-EVM interfaces and other contracts in Subnet-EVM can be accessible through `@avalabs/subnet-evm-contracts` package. This is already added to the `package.json` file. You can install it by running `npm install`. In order to import `IAllowList` interface, you can use the following import statement:
```solidity
import "@avalabs/subnet-evm-contracts/contracts/interfaces/IAllowList.sol";
```
The full file looks like this:
```solidity
// SPDX-License-Identifier: MIT
pragma solidity >=0.8.0;
import "@avalabs/subnet-evm-contracts/contracts/interfaces/IAllowList.sol";
interface IHelloWorld is IAllowList {
event GreetingChanged(
address indexed sender,
string oldGreeting,
string newGreeting
);
// sayHello returns the stored greeting string
function sayHello() external view returns (string calldata result);
// setGreeting stores the greeting string
function setGreeting(string calldata response) external;
}
```
Now we have an interface that our precompile can implement! Let's create an ABI of our Solidity interface.
In Precompile-EVM we import contracts from `@avalabs/subnet-evm-contracts` package. In order to generate the ABI in Precompile-EVM we need to include the `node_modules` folder to find imported contracts with following flags:
* `--abi`: ABI specification of the contracts.
* `--base-path path`: Use the given path as the root of the source tree instead of the root of the filesystem.
* `--include-path path`: Make an additional source directory available to the default import callback. Use this option if you want to import contracts whose location is not fixed in relation to your main source tree; for example third-party libraries installed using a package manager. Can be used multiple times. Can only be used if base path has a non-empty value.
* `--output-dir path`: If given, creates one file per output component and contract/file at the specified directory.
* `--overwrite`: Overwrite existing files (used together with` --output-dir`).
```bash
solc --abi ./contracts/interfaces/IHelloWorld.sol -o ./abis --base-path . --include-path ./node_modules
```
This generates the ABI code under `./abis/contracts_interfaces_IHelloWorld_sol_IHelloWorld.abi`.
```
[
{
"anonymous": false,
"inputs": [
{
"indexed": true,
"internalType": "address",
"name": "sender",
"type": "address"
},
{
"indexed": false,
"internalType": "string",
"name": "oldGreeting",
"type": "string"
},
{
"indexed": false,
"internalType": "string",
"name": "newGreeting",
"type": "string"
}
],
"name": "GreetingChanged",
"type": "event"
},
{
"anonymous": false,
"inputs": [
{
"indexed": true,
"internalType": "uint256",
"name": "role",
"type": "uint256"
},
{
"indexed": true,
"internalType": "address",
"name": "account",
"type": "address"
},
{
"indexed": true,
"internalType": "address",
"name": "sender",
"type": "address"
},
{
"indexed": false,
"internalType": "uint256",
"name": "oldRole",
"type": "uint256"
}
],
"name": "RoleSet",
"type": "event"
},
{
"inputs": [
{ "internalType": "address", "name": "addr", "type": "address" }
],
"name": "readAllowList",
"outputs": [
{ "internalType": "uint256", "name": "role", "type": "uint256" }
],
"stateMutability": "view",
"type": "function"
},
{
"inputs": [],
"name": "sayHello",
"outputs": [
{ "internalType": "string", "name": "result", "type": "string" }
],
"stateMutability": "view",
"type": "function"
},
{
"inputs": [
{ "internalType": "address", "name": "addr", "type": "address" }
],
"name": "setAdmin",
"outputs": [],
"stateMutability": "nonpayable",
"type": "function"
},
{
"inputs": [
{ "internalType": "address", "name": "addr", "type": "address" }
],
"name": "setEnabled",
"outputs": [],
"stateMutability": "nonpayable",
"type": "function"
},
{
"inputs": [
{ "internalType": "string", "name": "response", "type": "string" }
],
"name": "setGreeting",
"outputs": [],
"stateMutability": "nonpayable",
"type": "function"
},
{
"inputs": [
{ "internalType": "address", "name": "addr", "type": "address" }
],
"name": "setManager",
"outputs": [],
"stateMutability": "nonpayable",
"type": "function"
},
{
"inputs": [
{ "internalType": "address", "name": "addr", "type": "address" }
],
"name": "setNone",
"outputs": [],
"stateMutability": "nonpayable",
"type": "function"
}
]
```
As you can see the ABI also contains the `IAllowList` interface functions. This is because the `IHelloWorld` interface inherits from the `IAllowList` interface.
Note: The ABI must have named outputs in order to generate the precompile template.
Now that we have an ABI for the precompile gen tool to interact with, we can run the following command to generate our HelloWorld precompile files!
Let's go back to the root of the repository and run the PrecompileGen script helper:
```bash
cd ..
```
Both of these Subnet-EVM and Precompile-EVM have the same generate\_precompile.sh script. The one in Precompile-EVM installs the script from Subnet-EVM and runs it.
```bash
./scripts/generate_precompile.sh --help
# output
Using branch: precompile-tutorial
NAME:
precompilegen - subnet-evm precompile generator tool
USAGE:
main [global options] command [command options] [arguments...]
VERSION:
1.10.26-stable
COMMANDS:
help, h Shows a list of commands or help for one command
GLOBAL OPTIONS:
--abi value
Path to the contract ABI json to generate, - for STDIN
--out value
Output folder for the generated precompile files, - for STDOUT (default =
./precompile/contracts/{pkg}). Test files won't be generated if STDOUT is used
--pkg value
Go package name to generate the precompile into (default = {type})
--type value
Struct name for the precompile (default = {abi file name})
MISC
--help, -h (default: false)
show help
--version, -v (default: false)
print the version
COPYRIGHT:
Copyright 2013-2022 The go-ethereum Authors
```
Now let's generate the precompile template files!
In Subnet-EVM precompile implementations reside under the `./precompile/contracts` directory. Let's generate our precompile template in the `./precompile/contracts/helloworld` directory, where `helloworld` is the name of the Go package we want to generate the precompile into.
```bash
./scripts/generate_precompile.sh --abi ./contracts/abis/contracts_interfaces_IHelloWorld_sol_IHelloWorld.abi --type HelloWorld --pkg helloworld
```
This generates a precompile template files `contract.go`, `contract.abi`, `config.go`, `module.go`, `event.go` and `README.md` files. `README.md` explains general guidelines for precompile development. You should carefully read this file before modifying the precompile template.
```
There are some must-be-done changes waiting in the generated file. Each area requiring you to add your code is marked with CUSTOM CODE to make them easy to find and modify.
Additionally there are other files you need to edit to activate your precompile.
These areas are highlighted with comments "ADD YOUR PRECOMPILE HERE".
For testing take a look at other precompile tests in contract_test.go and config_test.go in other precompile folders.
General guidelines for precompile development:
1- Set a suitable config key in generated module.go. E.g: "yourPrecompileConfig"
2- Read the comment and set a suitable contract address in generated module.go. E.g:
ContractAddress = common.HexToAddress("ASUITABLEHEXADDRESS")
3- It is recommended to only modify code in the highlighted areas marked with "CUSTOM CODE STARTS HERE". Typically, custom codes are required in only those areas.
Modifying code outside of these areas should be done with caution and with a deep understanding of how these changes may impact the EVM.
4- If you have any event defined in your precompile, review the generated event.go file and set your event gas costs. You should also emit your event in your function in the contract.go file.
5- Set gas costs in generated contract.go
6- Force import your precompile package in precompile/registry/registry.go
7- Add your config unit tests under generated package config_test.go
8- Add your contract unit tests under generated package contract_test.go
9- Additionally you can add a full-fledged VM test for your precompile under plugin/vm/vm_test.go. See existing precompile tests for examples.
10- Add your solidity interface and test contract to contracts/contracts
11- Write solidity contract tests for your precompile in contracts/contracts/test
12- Write TypeScript DS-Test counterparts for your solidity tests in contracts/test
13- Create your genesis with your precompile enabled in tests/precompile/genesis/
14- Create e2e test for your solidity test in tests/precompile/solidity/suites.go
15- Run your e2e precompile Solidity tests with './scripts/run_ginkgo.sh`
```
Let's follow these steps and create our HelloWorld precompile.
For Precompile-EVM we don't need to put files under a deep directory structure. We can just generate the precompile template under its own directory via `--out ./helloworld` flag.
```bash
./scripts/generate_precompile.sh --abi ./contracts/abis/contracts_interfaces_IHelloWorld_sol_IHelloWorld.abi --type HelloWorld --pkg helloworld --out ./helloworld
```
This generates a precompile template files `contract.go`, `contract.abi`, `config.go`, `module.go`, `event.go` and `README.md` files. `README.md` explains general guidelines for precompile development. You should carefully read this file before modifying the precompile template.
```
There are some must-be-done changes waiting in the generated file. Each area requiring you to add your code is marked with CUSTOM CODE to make them easy to find and modify.
Additionally there are other files you need to edit to activate your precompile.
These areas are highlighted with comments "ADD YOUR PRECOMPILE HERE".
For testing take a look at other precompile tests in contract_test.go and config_test.go in other precompile folders.
General guidelines for precompile development:
1- Set a suitable config key in generated module.go. E.g: "yourPrecompileConfig"
2- Read the comment and set a suitable contract address in generated module.go. E.g:
ContractAddress = common.HexToAddress("ASUITABLEHEXADDRESS")
3- It is recommended to only modify code in the highlighted areas marked with "CUSTOM CODE STARTS HERE". Typically, custom codes are required in only those areas.
Modifying code outside of these areas should be done with caution and with a deep understanding of how these changes may impact the EVM.
4- If you have any event defined in your precompile, review the generated event.go file and set your event gas costs. You should also emit your event in your function in the contract.go file.
5- Set gas costs in generated contract.go
6- Force import your precompile package in precompile/registry/registry.go
7- Add your config unit tests under generated package config_test.go
8- Add your contract unit tests under generated package contract_test.go
9- Additionally you can add a full-fledged VM test for your precompile under plugin/vm/vm_test.go. See existing precompile tests for examples.
10- Add your solidity interface and test contract to contracts/contracts
11- Write solidity contract tests for your precompile in contracts/contracts/test
12- Write TypeScript DS-Test counterparts for your solidity tests in contracts/test
13- Create your genesis with your precompile enabled in tests/precompile/genesis/
14- Create e2e test for your solidity test in tests/precompile/solidity/suites.go
15- Run your e2e precompile Solidity tests with './scripts/run_ginkgo.sh`
```
Let's follow these steps and create our HelloWorld precompile!
# Defining Your Precompile
URL: /docs/virtual-machines/custom-precompiles/defining-precompile
Now that we have autogenerated the template code required for our precompile, let's actually write the logic for the precompile itself.
## Setting Config Key
Let's jump to `helloworld/module.go` file first. This file contains the module definition for our precompile. You can see the `ConfigKey` is set to some default value of `helloWorldConfig`. This key should be unique to the precompile.
This config key determines which JSON key to use when reading the precompile's config from the JSON upgrade/genesis file. In this case, the config key is `helloWorldConfig` and the JSON config should look like this:
```json
{
"helloWorldConfig": {
"blockTimestamp": 0
...
}
}
```
## Setting Contract Address
In the `helloworld/module.go` you can see the `ContractAddress` is set to some default value. This should be changed to a suitable address for your precompile. The address should be unique to the precompile. There is a registry of precompile addresses under [`precompile/registry/registry.go`](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/precompile/registry/registry.go).
A list of addresses is specified in the comments under this file. Modify the default value to be the next user available stateful precompile address. For forks of Subnet-EVM or Precompile-EVM, users should start at `0x0300000000000000000000000000000000000000` to ensure that their own modifications do not conflict with stateful precompiles that may be added to Subnet-EVM in the future. You should pick an address that is not already taken.
```go title="helloworld/module.go"
// This list is kept just for reference. The actual addresses defined in respective packages of precompiles.
// Note: it is important that none of these addresses conflict with each other or any other precompiles
// in core/vm/contracts.go.
// The first stateful precompiles were added in coreth to support nativeAssetCall and nativeAssetBalance. New stateful precompiles
// originating in coreth will continue at this prefix, so we reserve this range in subnet-evm so that they can be migrated into
// subnet-evm without issue.
// These start at the address: 0x0100000000000000000000000000000000000000 and will increment by 1.
// Optional precompiles implemented in subnet-evm start at 0x0200000000000000000000000000000000000000 and will increment by 1
// from here to reduce the risk of conflicts.
// For forks of subnet-evm, users should start at 0x0300000000000000000000000000000000000000 to ensure
// that their own modifications do not conflict with stateful precompiles that may be added to subnet-evm
// in the future.
// ContractDeployerAllowListAddress = common.HexToAddress("0x0200000000000000000000000000000000000000")
// ContractNativeMinterAddress = common.HexToAddress("0x0200000000000000000000000000000000000001")
// TxAllowListAddress = common.HexToAddress("0x0200000000000000000000000000000000000002")
// FeeManagerAddress = common.HexToAddress("0x0200000000000000000000000000000000000003")
// RewardManagerAddress = common.HexToAddress("0x0200000000000000000000000000000000000004")
// HelloWorldAddress = common.HexToAddress("0x0300000000000000000000000000000000000000")
// ADD YOUR PRECOMPILE HERE
// {YourPrecompile}Address = common.HexToAddress("0x03000000000000000000000000000000000000??")
```
Don't forget to update the actual variable `ContractAddress` in `module.go` to the address you chose. It should look like this:
```go title="helloworld/module.go"
// ContractAddress is the defined address of the precompile contract.
// This should be unique across all precompile contracts.
// See params/precompile_modules.go for registered precompile contracts and more information.
var ContractAddress = common.HexToAddress("0x0300000000000000000000000000000000000000")
```
Now when Subnet-EVM sees the `helloworld.ContractAddress` as input when executing [`CALL`](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/core/vm/evm.go#L251), [`CALLCODE`](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/core/vm/evm.go#L341), [`DELEGATECALL`](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/core/vm/evm.go#L392), [`STATICCALL`](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/core/vm/evm.go#L435), it can run the precompile if the precompile is enabled.
## Adding Custom Code
Search (`CTRL F`) throughout the file with `CUSTOM CODE STARTS HERE` to find the areas in the precompile package that you need to modify. You should start with the reference imports code block.
### Module File
The module file contains fundamental information about the precompile. This includes the key for the precompile, the address of the precompile, and a configurator. This file is located at [`./precompile/helloworld/module.go`](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/precompile/contracts/helloworld/module.go) for Subnet-EVM and [./helloworld/module.go](https://github.com/ava-labs/precompile-evm/blob/hello-world-example/helloworld/module.go) for Precompile-EVM.
This file defines the module for the precompile. The module is used to register the precompile to the precompile registry. The precompile registry is used to read configs and enable the precompile. Registration is done in the `init()` function of the module file. `MakeConfig()` is used to create a new instance for the precompile config. This will be used in custom Unmarshal/Marshal logic. You don't need to override these functions.
#### Configure()
Module file contains a `configurator` which implements the `contract.Configurator` interface. This interface includes a `Configure()` function used to configure the precompile and set the initial state of the precompile. This function is called when the precompile is enabled. This is typically used to read from a given config in upgrade/genesis JSON and sets the initial state of the precompile accordingly. This function also calls `AllowListConfig.Configure()` to invoke AllowList configuration as the last step. You should keep it as it is if you want to use AllowList. You can modify this function for your custom logic. You can circle back to this function later after you have finalized the implementation of the precompile config.
### Config File
The config file contains the config for the precompile. This file is located at [`./precompile/helloworld/config.go`](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/precompile/contracts/helloworld/config.go) for Subnet-EVM and [./helloworld/config.go](https://github.com/ava-labs/precompile-evm/blob/hello-world-example/helloworld/config.go) for Precompile-EVM. This file contains the `Config` struct, which implements `precompileconfig.Config` interface. It has some embedded structs like `precompileconfig.Upgrade`. `Upgrade` is used to enable upgrades for the precompile. It contains the `BlockTimestamp` and `Disable` to enable/disable upgrades. `BlockTimestamp` is the timestamp of the block when the upgrade will be activated. `Disable` is used to disable the upgrade. If you use `AllowList` for the precompile, there is also `allowlist.AllowListConfig` embedded in the `Config` struct. `AllowListConfig` is used to specify initial roles for specified addresses. If you have any custom fields in your precompile config, you can add them here. These custom fields will be read from upgrade/genesis JSON and set in the precompile config.
```go title="precompile/helloworld/config.go"
// Config implements the precompileconfig.Config interface and
// adds specific configuration for HelloWorld.
type Config struct {
allowlist.AllowListConfig
precompileconfig.Upgrade
}
```
#### Verify()
`Verify()` is called on startup and an error is treated as fatal. Generated code contains a call to `AllowListConfig.Verify()` to verify the `AllowListConfig`. You can leave that as is and start adding your own custom verify code after that.
We can leave this function as is right now because there is no invalid custom configuration for the `Config`.
```go title="precompile/helloworld/config.go"
// Verify tries to verify Config and returns an error accordingly.
func (c *Config) Verify() error {
// Verify AllowList first
if err := c.AllowListConfig.Verify(); err != nil {
return err
}
// CUSTOM CODE STARTS HERE
// Add your own custom verify code for Config here
// and return an error accordingly
return nil
}
```
#### Equal()
Next, we see is `Equal()`. This function determines if two precompile configs are equal. This is used to determine if the precompile needs to be upgraded. There is some default code that is generated for checking `Upgrade` and `AllowListConfig` equality.
```go title="precompile/helloworld/config.go"
// Equal returns true if [s] is a [*Config] and it has been configured identical to [c].
func (c *Config) Equal(s precompileconfig.Config) bool {
// typecast before comparison
other, ok := (s).(*Config)
if !ok {
return false
}
// CUSTOM CODE STARTS HERE
// modify this boolean accordingly with your custom Config, to check if [other] and the current [c] are equal
// if Config contains only Upgrade and AllowListConfig you can skip modifying it.
equals := c.Upgrade.Equal(&other.Upgrade) && c.AllowListConfig.Equal(&other.AllowListConfig)
return equals
}
```
We can leave this function as is since we check `Upgrade` and `AllowListConfig` for equality which are the only fields that `Config` struct has.
### Modify Configure()
We can now circle back to `Configure()` in `module.go` as we finished implementing `Config` struct. This function configures the `state` with the initial configuration at`blockTimestamp` when the precompile is enabled.
In the HelloWorld example, we want to set up a default key-value mapping in the state where the key is `storageKey` and the value is `Hello World!`. The `StateDB` allows us to store a key-value mapping of 32-byte hashes. The below code snippet can be copied and pasted to overwrite the default `Configure()` code.
```go title="precompile/helloworld/module.go"
const defaultGreeting = "Hello World!"
// Configure configures [state] with the given [cfg] precompileconfig.
// This function is called by the EVM once per precompile contract activation.
// You can use this function to set up your precompile contract's initial state,
// by using the [cfg] config and [state] stateDB.
func (*configurator) Configure(chainConfig contract.ChainConfig, cfg precompileconfig.Config, state contract.StateDB, _ contract.BlockContext) error {
config, ok := cfg.(*Config)
if !ok {
return fmt.Errorf("incorrect config %T: %v", config, config)
}
// CUSTOM CODE STARTS HERE
// This will be called in the first block where HelloWorld stateful precompile is enabled.
// 1) If BlockTimestamp is nil, this will not be called
// 2) If BlockTimestamp is 0, this will be called while setting up the genesis block
// 3) If BlockTimestamp is 1000, this will be called while processing the first block
// whose timestamp is >= 1000
//
// Set the initial value under [common.BytesToHash([]byte("storageKey")] to "Hello World!"
StoreGreeting(state, defaultGreeting)
// AllowList is activated for this precompile. Configuring allowlist addresses here.
return config.AllowListConfig.Configure(state, ContractAddress)
}
```
### Event File
The event file contains the events that the precompile can emit. This file is located at [`./precompile/helloworld/event.go`](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/precompile/contracts/helloworld/event.go) for Subnet-EVM and [./helloworld/event.go](https://github.com/ava-labs/precompile-evm/blob/hello-world-example/helloworld/event.go) for Precompile-EVM. The file begins with a comment about events and how they can be emitted:
```go title="precompile/helloworld/event.go"
/* NOTE: Events can only be emitted in state-changing functions. So you cannot use events in read-only (view) functions.
Events are generally emitted at the end of a state-changing function with AddLog method of the StateDB. The AddLog method takes 4 arguments:
1. Address of the contract that emitted the event.
2. Topic hashes of the event.
3. Encoded non-indexed data of the event.
4. Block number at which the event was emitted.
The first argument is the address of the contract that emitted the event.
Topics can be at most 4 elements, the first topic is the hash of the event signature and the rest are the indexed event arguments. There can be at most 3 indexed arguments.
Topics cannot be fully unpacked into their original values since they're 32-bytes hashes.
The non-indexed arguments are encoded using the ABI encoding scheme. The non-indexed arguments can be unpacked into their original values.
Before packing the event, you need to calculate the gas cost of the event. The gas cost of an event is the base gas cost + the gas cost of the topics + the gas cost of the non-indexed data.
See Get{EvetName}EventGasCost functions for more details.
You can use the following code to emit an event in your state-changing precompile functions (generated packer might be different):*/
topics, data, err := PackMyEvent(
topic1,
topic2,
data1,
data2,
)
if err != nil {
return nil, remainingGas, err
}
accessibleState.GetStateDB().AddLog(&types.Log{
Address: ContractAddress,
Topics: topics,
Data: data,
BlockNumber: accessibleState.GetBlockContext().Number().Uint64(),
})
```
```go title="precompile/helloworld/event.go"
/* NOTE: Events can only be emitted in state-changing functions. So you cannot use events in read-only (view) functions.
Events are generally emitted at the end of a state-changing function with AddLog method of the StateDB. The AddLog method takes 4 arguments:
1. Address of the contract that emitted the event.
2. Topic hashes of the event.
3. Encoded non-indexed data of the event.
4. Block number at which the event was emitted.
The first argument is the address of the contract that emitted the event.
Topics can be at most 4 elements, the first topic is the hash of the event signature and the rest are the indexed event arguments. There can be at most 3 indexed arguments.
Topics cannot be fully unpacked into their original values since they're 32-bytes hashes.
The non-indexed arguments are encoded using the ABI encoding scheme. The non-indexed arguments can be unpacked into their original values.
Before packing the event, you need to calculate the gas cost of the event. The gas cost of an event is the base gas cost + the gas cost of the topics + the gas cost of the non-indexed data.
See Get{EvetName}EventGasCost functions for more details.
You can use the following code to emit an event in your state-changing precompile functions (generated packer might be different):*/
topics, data, err := PackMyEvent(
topic1,
topic2,
data1,
data2,
)
if err != nil {
return nil, remainingGas, err
}
accessibleState.GetStateDB().AddLog(
ContractAddress,
topics,
data,
accessibleState.GetBlockContext().Number().Uint64(),
)
```
In this file you should set your event's gas cost and implement the `Get{EventName}EventGasCost` function. This function should take the data you want to emit and calculate the gas cost. In this example we defined our event as follow, and plan to emit it in the `setGreeting` function:
```go
event GreetingChanged(address indexed sender, string oldGreeting, string newGreeting);
```
We used arbitrary strings as non-indexed event data, remind that each emitted event is stored on chain, thus charging right amount is critical. We calculated gas cost according to the length of the string to make sure we're charging right amount of gas. If you're sure that you're dealing with a fixed length data, you can use a fixed gas cost for your event. We will show how events can be emitted under the Contract File section.
### Contract File
The contract file contains the functions of the precompile contract that will be called by the EVM. The file is located at [`./precompile/helloworld/contract.go`](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/precompile/contracts/helloworld/contract.go) for Subnet-EVM and [./helloworld/contract.go](https://github.com/ava-labs/precompile-evm/blob/hello-world-example/helloworld/contract.go) for Precompile-EVM. Since we use `IAllowList` interface there will be auto-generated code for `AllowList` functions like below:
```go title="precompile/helloworld/contract.go"
// GetHelloWorldAllowListStatus returns the role of [address] for the HelloWorld list.
func GetHelloWorldAllowListStatus(stateDB contract.StateDB, address common.Address) allowlist.Role {
return allowlist.GetAllowListStatus(stateDB, ContractAddress, address)
}
// SetHelloWorldAllowListStatus sets the permissions of [address] to [role] for the
// HelloWorld list. Assumes [role] has already been verified as valid.
// This stores the [role] in the contract storage with address [ContractAddress]
// and [address] hash. It means that any reusage of the [address] key for different value
// conflicts with the same slot [role] is stored.
// Precompile implementations must use a different key than [address] for their storage.
func SetHelloWorldAllowListStatus(stateDB contract.StateDB, address common.Address, role allowlist.Role) {
allowlist.SetAllowListRole(stateDB, ContractAddress, address, role)
}
```
These will be helpful to use AllowList precompile helper in our functions.
#### Packers and Unpackers
There are also auto-generated Packers and Unpackers for the ABI. These will be used in `sayHello` and `setGreeting` functions to comfort the ABI. These functions are auto-generated and will be used in necessary places accordingly. You don't need to worry about how to deal with them, but it's good to know what they are.
Note: There were few changes to precompile packers with Durango. In this example we assumed that the HelloWorld precompile contract has been deployed before Durango. We need to activate this condition only after Durango. If this is a new precompile and never deployed before Durango, you can activate it immediately by removing the if condition.
Each input to a precompile contract function has it's own `Unpacker` function as follows (if deployed before Durango):
```go title="precompile/helloworld/contract.go"
// UnpackSetGreetingInput attempts to unpack [input] into the string type argument
// assumes that [input] does not include selector (omits first 4 func signature bytes)
// if [useStrictMode] is true, it will return an error if the length of [input] is not [common.HashLength]
func UnpackSetGreetingInput(input []byte, useStrictMode bool) (string, error) {
// Initially we had this check to ensure that the input was the correct length.
// However solidity does not always pack the input to the correct length, and allows
// for extra padding bytes to be added to the end of the input. Therefore, we have removed
// this check with the Durango. We still need to keep this check for backwards compatibility.
if useStrictMode && len(input) > common.HashLength {
return "", ErrInputExceedsLimit
}
res, err := HelloWorldABI.UnpackInput("setGreeting", input, useStrictMode)
if err != nil {
return "", err
}
unpacked := *abi.ConvertType(res[0], new(string)).(*string)
return unpacked, nil
}
```
If this is a new precompile that will be deployed after Durango, you can skip strict mode handling and use false:
```go title="precompile/helloworld/contract.go"
func UnpackSetGreetingInput(input []byte) (string, error) {
res, err := HelloWorldABI.UnpackInput("setGreeting", input, false)
if err != nil {
return "", err
}
unpacked := *abi.ConvertType(res[0], new(string)).(*string)
return unpacked, nil
}
```
The ABI is a binary format and the input to the precompile contract function is a byte array. The `Unpacker` function converts this input to a more easy-to-use format so that we can use it in our function.
Similarly, there is a `Packer` function for each output of a precompile contract function as follows:
```go title="precompile/helloworld/contract.go"
// PackSayHelloOutput attempts to pack given result of type string
// to conform the ABI outputs.
func PackSayHelloOutput(result string) ([]byte, error) {
return HelloWorldABI.PackOutput("sayHello", result)
}
```
This function converts the output of the function to a byte array that conforms to the ABI and can be returned to the EVM as a result.
#### Modify sayHello()
The next place to modify is in our `sayHello()` function. In a previous step, we created the `IHelloWorld.sol` interface with two functions `sayHello()` and `setGreeting()`. We finally get to implement them here. If any contract calls these functions from the interface, the below function gets executed. This function is a simple getter function.
In `Configure()` we set up a mapping with the key as `storageKey` and the value as `Hello World!`. In this function, we will be returning whatever value is at `storageKey`. The below code snippet can be copied and pasted to overwrite the default `setGreeting` code.
First, we add a helper function to get the greeting value from the stateDB, this will be helpful when we test our contract. We will use the `storageKeyHash` to store the value in the Contract's reserved storage in the stateDB.
```go title="precompile/helloworld/contract.go"
var (
// storageKeyHash is the hash of the storage key "storageKey" in the contract storage.
// This is used to store the value of the greeting in the contract storage.
// It is important to use a unique key here to avoid conflicts with other storage keys
// like addresses, AllowList, etc.
storageKeyHash = common.BytesToHash([]byte("storageKey"))
)
// GetGreeting returns the value of the storage key "storageKey" in the contract storage,
// with leading zeroes trimmed.
// This function is mostly used for tests.
func GetGreeting(stateDB contract.StateDB) string {
// Get the value set at recipient
value := stateDB.GetState(ContractAddress, storageKeyHash)
return string(common.TrimLeftZeroes(value.Bytes()))
}
```
Now we can modify the `sayHello` function to return the stored value.
```go title="precompile/helloworld/contract.go"
func sayHello(accessibleState contract.AccessibleState, caller common.Address, addr common.Address, input []byte, suppliedGas uint64, readOnly bool) (ret []byte, remainingGas uint64, err error) {
if remainingGas, err = contract.DeductGas(suppliedGas, SayHelloGasCost); err != nil {
return nil, 0, err
}
// CUSTOM CODE STARTS HERE
// Get the current state
currentState := accessibleState.GetStateDB()
// Get the value set at recipient
value := GetGreeting(currentState)
packedOutput, err := PackSayHelloOutput(value)
if err != nil {
return nil, remainingGas, err
}
// Return the packed output and the remaining gas
return packedOutput, remainingGas, nil
}
```
#### Modify setGreeting()
`setGreeting()` function is a simple setter function. It takes in `input` and we will set that as the value in the state mapping with the key as `storageKey`. It also checks if the VM running the precompile is in read-only mode. If it is, it returns an error. At the end of a successful execution, it will emit `GreetingChanged` event.
There is also a generated `AllowList` code in that function. This generated code checks if the caller address is eligible to perform this state-changing operation. If not, it returns an error.
Let's add the helper function to set the greeting value in the stateDB, this will be helpful when we test our contract.
```go title="precompile/helloworld/contract.go"
// StoreGreeting sets the value of the storage key "storageKey" in the contract storage.
func StoreGreeting(stateDB contract.StateDB, input string) {
inputPadded := common.LeftPadBytes([]byte(input), common.HashLength)
inputHash := common.BytesToHash(inputPadded)
stateDB.SetState(ContractAddress, storageKeyHash, inputHash)
}
```
The below code snippet can be copied and pasted to overwrite the default `setGreeting()` code.
```go title="precompile/helloworld/contract.go"
func setGreeting(accessibleState contract.AccessibleState, caller common.Address, addr common.Address, input []byte, suppliedGas uint64, readOnly bool) (ret []byte, remainingGas uint64, err error) {
if remainingGas, err = contract.DeductGas(suppliedGas, SetGreetingGasCost); err != nil {
return nil, 0, err
}
if readOnly {
return nil, remainingGas, vmerrs.ErrWriteProtection
}
// do not use strict mode after Durango
useStrictMode := !contract.IsDurangoActivated(accessibleState)
// attempts to unpack [input] into the arguments to the SetGreetingInput.
// Assumes that [input] does not include selector
// You can use unpacked [inputStruct] variable in your code
inputStruct, err := UnpackSetGreetingInput(input, useStrictMode)
if err != nil {
return nil, remainingGas, err
}
// Allow list is enabled and SetGreeting is a state-changer function.
// This part of the code restricts the function to be called only by enabled/admin addresses in the allow list.
// You can modify/delete this code if you don't want this function to be restricted by the allow list.
stateDB := accessibleState.GetStateDB()
// Verify that the caller is in the allow list and therefore has the right to call this function.
callerStatus := allowlist.GetAllowListStatus(stateDB, ContractAddress, caller)
if !callerStatus.IsEnabled() {
return nil, remainingGas, fmt.Errorf("%w: %s", ErrCannotSetGreeting, caller)
}
// allow list code ends here.
// CUSTOM CODE STARTS HERE
// With Durango, you can emit an event in your state-changing precompile functions.
// Note: If you have been using the precompile before Durango, you should activate it only after Durango.
// Activating this code before Durango will result in a consensus failure.
// If this is a new precompile and never deployed before Durango, you can activate it immediately by removing
// the if condition.
// We will first read the old greeting. So we should charge the gas for reading the storage.
if remainingGas, err = contract.DeductGas(remainingGas, contract.ReadGasCostPerSlot); err != nil {
return nil, 0, err
}
oldGreeting := GetGreeting(stateDB)
eventData := GreetingChangedEventData{
OldGreeting: oldGreeting,
NewGreeting: inputStruct,
}
topics, data, err := PackGreetingChangedEvent(caller, eventData)
if err != nil {
return nil, remainingGas, err
}
// Charge the gas for emitting the event.
eventGasCost := GetGreetingChangedEventGasCost(eventData)
if remainingGas, err = contract.DeductGas(remainingGas, eventGasCost); err != nil {
return nil, 0, err
}
// Emit the event
stateDB.AddLog(&types.Log{
Address: ContractAddress,
Topics: topics,
Data: data,
BlockNumber: accessibleState.GetBlockContext().Number().Uint64(),
})
// setGreeting is the execution function
// "SetGreeting(name string)" and sets the storageKey
// in the string returned by hello world
StoreGreeting(stateDB, inputStruct)
// This function does not return an output, leave this one as is
packedOutput := []byte{}
// Return the packed output and the remaining gas
return packedOutput, remainingGas, nil
}
```
```go title="precompile/helloworld/contract.go"
func setGreeting(accessibleState contract.AccessibleState, caller common.Address, addr common.Address, input []byte, suppliedGas uint64, readOnly bool) (ret []byte, remainingGas uint64, err error) {
if remainingGas, err = contract.DeductGas(suppliedGas, SetGreetingGasCost); err != nil {
return nil, 0, err
}
if readOnly {
return nil, remainingGas, vmerrs.ErrWriteProtection
}
// do not use strict mode after Durango
useStrictMode := !contract.IsDurangoActivated(accessibleState)
// attempts to unpack [input] into the arguments to the SetGreetingInput.
// Assumes that [input] does not include selector
// You can use unpacked [inputStruct] variable in your code
inputStruct, err := UnpackSetGreetingInput(input, useStrictMode)
if err != nil {
return nil, remainingGas, err
}
// Allow list is enabled and SetGreeting is a state-changer function.
// This part of the code restricts the function to be called only by enabled/admin addresses in the allow list.
// You can modify/delete this code if you don't want this function to be restricted by the allow list.
stateDB := accessibleState.GetStateDB()
// Verify that the caller is in the allow list and therefore has the right to call this function.
callerStatus := allowlist.GetAllowListStatus(stateDB, ContractAddress, caller)
if !callerStatus.IsEnabled() {
return nil, remainingGas, fmt.Errorf("%w: %s", ErrCannotSetGreeting, caller)
}
// allow list code ends here.
// CUSTOM CODE STARTS HERE
// With Durango, you can emit an event in your state-changing precompile functions.
// Note: If you have been using the precompile before Durango, you should activate it only after Durango.
// Activating this code before Durango will result in a consensus failure.
// If this is a new precompile and never deployed before Durango, you can activate it immediately by removing
// the if condition.
// We will first read the old greeting. So we should charge the gas for reading the storage.
if remainingGas, err = contract.DeductGas(remainingGas, contract.ReadGasCostPerSlot); err != nil {
return nil, 0, err
}
oldGreeting := GetGreeting(stateDB)
eventData := GreetingChangedEventData{
OldGreeting: oldGreeting,
NewGreeting: inputStruct,
}
topics, data, err := PackGreetingChangedEvent(caller, eventData)
if err != nil {
return nil, remainingGas, err
}
// Charge the gas for emitting the event.
eventGasCost := GetGreetingChangedEventGasCost(eventData)
if remainingGas, err = contract.DeductGas(remainingGas, eventGasCost); err != nil {
return nil, 0, err
}
// Emit the event
stateDB.AddLog(&types.Log{
Address: ContractAddress,
Topics: topics,
Data: data,
BlockNumber: accessibleState.GetBlockContext().Number().Uint64(),
})
// setGreeting is the execution function
// "SetGreeting(name string)" and sets the storageKey
// in the string returned by hello world
StoreGreeting(stateDB, inputStruct)
// This function does not return an output, leave this one as is
packedOutput := []byte{}
// Return the packed output and the remaining gas
return packedOutput, remainingGas, nil
}
```
Precompile events introduced with Durango. In this example we assumed that the `HelloWorld` precompile contract has been deployed before Durango.
If this is a new precompile and it will be deployed after Durango, you can activate it immediately by removing the Durango if condition (`contract.IsDurangoActivated(accessibleState)`).
### Setting Gas Costs
Setting gas costs for functions is very important and should be done carefully. If the gas costs are set too low, then functions can be abused and can cause DoS attacks. If the gas costs are set too high, then the contract will be too expensive to run.
Subnet-EVM has some predefined gas costs for write and read operations in [`precompile/contract/utils.go`](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/precompile/contract/utils.go#L19-L20). In order to provide a baseline for gas costs, we have set the following gas costs.
```go title="precompile/contract/utils.go"
// Gas costs for stateful precompiles
const (
WriteGasCostPerSlot = 20_000
ReadGasCostPerSlot = 5_000
)
```
* `WriteGasCostPerSlot` is the cost of one write such as modifying a state storage slot.
* `ReadGasCostPerSlot` is the cost of reading a state storage slot.
This should be in your gas cost estimations based on how many times the precompile function does a read or a write. For example, if the precompile modifies the state slot of its precompile address twice then the gas cost for that function would be `40_000`. However, if the precompile does additional operations and requires more computational power, then you should increase the gas costs accordingly.
On top of these gas costs, we also have to account for the gas costs of AllowList gas costs. These are the gas costs of reading and writing permissions for addresses in AllowList. These are defined under Subnet-EVM's [`precompile/allowlist/allowlist.go`](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/precompile/allowlist/allowlist.go#L28-L29).
By default, these are added to the default gas costs of the state-change functions (SetGreeting) of the precompile. Meaning that these functions will cost an additional `ReadAllowListGasCost` in order to read permissions from the storage. If you don't plan to read permissions from the storage then you can omit these.
Now going back to our `/helloworld/contract.go`, we can modify our precompile function gas costs. Please search (`CTRL F`) `SET A GAS COST HERE` to locate the default gas cost code.
```go title="helloworld/contract.go"
SayHelloGasCost uint64 = 0 // SET A GAS COST HERE
SetGreetingGasCost uint64 = 0 + allowlist.ReadAllowListGasCost // SET A GAS COST HERE
```
We get and set our greeting with `sayHello()` and `setGreeting()` in one slot respectively so we can define the gas costs as follows. We also read permissions from the AllowList in `setGreeting()` so we keep `allowlist.ReadAllowListGasCost`.
```go title="helloworld/contract.go"
SayHelloGasCost uint64 = contract.ReadGasCostPerSlot
SetGreetingGasCost uint64 = contract.WriteGasCostPerSlot + allowlist.ReadAllowListGasCost
```
## Registering Your Precompile
We should register our precompile package to the Subnet-EVM to be discovered by other packages. Our `Module` file contains an `init()` function that registers our precompile. `init()` is called when the package is imported. We should register our precompile in a common package so that it can be imported by other packages.
For Subnet-EVM we have a precompile registry under [`/precompile/registry/registry.go`](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/precompile/registry/registry.go). This registry force-imports precompiles from other packages, for example:
```go title="precompile/registry/registry.go"
// Force imports of each precompile to ensure each precompile's init function runs and registers itself
// with the registry.
import (
_ "github.com/ava-labs/subnet-evm/precompile/contracts/deployerallowlist"
_ "github.com/ava-labs/subnet-evm/precompile/contracts/nativeminter"
_ "github.com/ava-labs/subnet-evm/precompile/contracts/txallowlist"
_ "github.com/ava-labs/subnet-evm/precompile/contracts/feemanager"
_ "github.com/ava-labs/subnet-evm/precompile/contracts/rewardmanager"
_ "github.com/ava-labs/subnet-evm/precompile/contracts/helloworld"
// ADD YOUR PRECOMPILE HERE
// _ "github.com/ava-labs/subnet-evm/precompile/contracts/yourprecompile"
)
```
The registry itself also force-imported by the [\`/plugin/evm/vm.go](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/plugin/evm/vm.go#L50). This ensures that the registry is imported and the precompiles are registered.
For Precompile-EVM there is a `plugin/main.go` file in Precompile-EVM that orchestrates this precompile registration.
```go title="plugin/main.go"
// (c) 2019-2023, Ava Labs, Inc. All rights reserved.
// See the file LICENSE for licensing terms.
package main
import (
"fmt"
"github.com/ava-labs/avalanchego/version"
"github.com/ava-labs/subnet-evm/plugin/evm"
"github.com/ava-labs/subnet-evm/plugin/runner"
// Each precompile generated by the precompilegen tool has a self-registering init function
// that registers the precompile with the subnet-evm. Importing the precompile package here
// will cause the precompile to be registered with the subnet-evm.
_ "github.com/ava-labs/precompile-evm/helloworld"
// ADD YOUR PRECOMPILE HERE
//_ "github.com/ava-labs/precompile-evm/{yourprecompilepkg}"
)
```
# Writing Test Cases
URL: /docs/virtual-machines/custom-precompiles/defining-test-cases
In this section, we will go over the different ways we can write test cases for our stateful precompile.
## Adding Config Tests
Precompile generation tool generates skeletons for unit tests as well. Generated config tests will be under [`./precompile/contracts/helloworld/config_test.go`](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/precompile/contracts/helloworld/config_test.go) for Subnet-EVM and [`./helloworld/config_test.go`](https://github.com/ava-labs/precompile-evm/blob/hello-world-example/helloworld/config_test.go) for Precompile-EVM. There are mainly two functions we need to test: `Verify` and `Equal`. `Verify` checks if the precompile is configured correctly. `Equal` checks if the precompile is equal to another precompile. Generated `Verify` tests contain a valid case.
You can add more invalid cases depending on your implementation. `Equal` tests generate some invalid cases to test different timestamps, types, and AllowList cases. You can check each `config_test.go` files for other precompiles under the Subnet-EVM's [`./precompile/contracts`](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/precompile/contracts/) directory for more examples.
## Adding Contract Tests
The tool also generates contract tests to make sure our precompile is working correctly. Generated tests include cases to test allow list capabilities, gas costs, and calling functions in read-only mode. You can check other `contract_test.go` files in the `/precompile/contracts`. Hello World contract tests will be under [`./precompile/contracts/helloworld/contract_test.go`](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/precompile/contracts/helloworld/contract_test.go) for Subnet-EVM and [`./helloworld/contract_test.go`](https://github.com/ava-labs/precompile-evm/blob/hello-world-example/helloworld/contract_test.go) for Precompile-EVM.
We will also add more test to cover functionalities of `sayHello()` and `setGreeting()`. Contract tests are defined in a standard structure that each test can customize to their needs. The test structure is as follows:
```go
// PrecompileTest is a test case for a precompile
type PrecompileTest struct {
// Caller is the address of the precompile caller
Caller common.Address
// Input the raw input bytes to the precompile
Input []byte
// InputFn is a function that returns the raw input bytes to the precompile
// If specified, Input will be ignored.
InputFn func(t *testing.T) []byte
// SuppliedGas is the amount of gas supplied to the precompile
SuppliedGas uint64
// ReadOnly is whether the precompile should be called in read only
// mode. If true, the precompile should not modify the state.
ReadOnly bool
// Config is the config to use for the precompile
// It should be the same precompile config that is used in the
// precompile's configurator.
// If nil, Configure will not be called.
Config precompileconfig.Config
// BeforeHook is called before the precompile is called.
BeforeHook func(t *testing.T, state contract.StateDB)
// AfterHook is called after the precompile is called.
AfterHook func(t *testing.T, state contract.StateDB)
// ExpectedRes is the expected raw byte result returned by the precompile
ExpectedRes []byte
// ExpectedErr is the expected error returned by the precompile
ExpectedErr string
// BlockNumber is the block number to use for the precompile's block context
BlockNumber int64
}
```
Each test can populate the fields of the `PrecompileTest` struct to customize the test. This test uses an AllowList helper function `allowlist.RunPrecompileWithAllowListTests(t, Module, state.NewTestStateDB, tests)` which can run all specified tests plus AllowList test suites. If you don't plan to use AllowList, you can directly run them as follows:
```go
for name, test := range tests {
t.Run(name, func(t *testing.T) {
test.Run(t, module, newStateDB(t))
})
}
```
## Adding VM Tests (Optional)
This is only applicable for direct Subnet-EVM forks as test files are not directly exported in Golang. If you use Precompile-EVM you can skip this step.
VM tests are tests that run the precompile by calling it through the Subnet-EVM. These are the most comprehensive tests that we can run. If your precompile modifies how the Subnet-EVM works, for example changing blockchain rules, you should add a VM test. For example, you can take a look at the `TestRewardManagerPrecompileSetRewardAddress` function in [here](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/plugin/evm/vm_test.go#L2772).
For this Hello World example, we don't modify any Subnet-EVM rules, so we don't need to add any VM tests.
## Adding Solidity Test Contracts
Let's add our test contract to `./contracts/contracts`. This smart contract lets us interact with our precompile! We cast the `HelloWorld` precompile address to the `IHelloWorld` interface. In doing so, `helloWorld` is now a contract of type `IHelloWorld` and when we call any functions on that contract, we will be redirected to the HelloWorld precompile address.
The below code snippet can be copied and pasted into a new file called `ExampleHelloWorld.sol`:
```go
//SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
import "./IHelloWorld.sol";
// ExampleHelloWorld shows how the HelloWorld precompile can be used in a smart contract.
contract ExampleHelloWorld {
address constant HELLO_WORLD_ADDRESS =
0x0300000000000000000000000000000000000000;
IHelloWorld helloWorld = IHelloWorld(HELLO_WORLD_ADDRESS);
function sayHello() public view returns (string memory) {
return helloWorld.sayHello();
}
function setGreeting(string calldata greeting) public {
helloWorld.setGreeting(greeting);
}
}
```
Hello World Precompile is a different contract than ExampleHelloWorld and has a different address. Since the precompile uses AllowList for a permissioned access, any call to the precompile including from ExampleHelloWorld will be denied unless the caller is added to the AllowList.
Please note that this contract is simply a wrapper and is calling the precompile functions. The reason why we add another example smart contract is to have a simpler stateless tests.
For the test contract we write our test in `./contracts/test/ExampleHelloWorldTest.sol`.
```solidity
//SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
import "../ExampleHelloWorld.sol";
import "../interfaces/IHelloWorld.sol";
import "./AllowListTest.sol";
contract ExampleHelloWorldTest is AllowListTest {
IHelloWorld helloWorld = IHelloWorld(HELLO_WORLD_ADDRESS);
function step_getDefaultHelloWorld() public {
ExampleHelloWorld example = new ExampleHelloWorld();
address exampleAddress = address(example);
assertRole(helloWorld.readAllowList(exampleAddress), AllowList.Role.None);
assertEq(example.sayHello(), "Hello World!");
}
function step_doesNotSetGreetingBeforeEnabled() public {
ExampleHelloWorld example = new ExampleHelloWorld();
address exampleAddress = address(example);
assertRole(helloWorld.readAllowList(exampleAddress), AllowList.Role.None);
try example.setGreeting("testing") {
assertTrue(false, "setGreeting should fail");
} catch {}
}
function step_setAndGetGreeting() public {
ExampleHelloWorld example = new ExampleHelloWorld();
address exampleAddress = address(example);
assertRole(helloWorld.readAllowList(exampleAddress), AllowList.Role.None);
helloWorld.setEnabled(exampleAddress);
assertRole(
helloWorld.readAllowList(exampleAddress),
AllowList.Role.Enabled
);
string memory greeting = "testgreeting";
example.setGreeting(greeting);
assertEq(example.sayHello(), greeting);
}
}
```
For Precompile-EVM, you should import AllowListTest with `@avalabs/subnet-evm-contracts` NPM package:
```solidity
//SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
import "../ExampleHelloWorld.sol";
import "../interfaces/IHelloWorld.sol";
import "@avalabs/subnet-evm-contracts/contracts/test/AllowListTest.sol";
contract ExampleHelloWorldTest is AllowListTest {
IHelloWorld helloWorld = IHelloWorld(HELLO_WORLD_ADDRESS);
function step_getDefaultHelloWorld() public {
ExampleHelloWorld example = new ExampleHelloWorld();
address exampleAddress = address(example);
assertRole(helloWorld.readAllowList(exampleAddress), AllowList.Role.None);
assertEq(example.sayHello(), "Hello World!");
}
function step_doesNotSetGreetingBeforeEnabled() public {
ExampleHelloWorld example = new ExampleHelloWorld();
address exampleAddress = address(example);
assertRole(helloWorld.readAllowList(exampleAddress), AllowList.Role.None);
try example.setGreeting("testing") {
assertTrue(false, "setGreeting should fail");
} catch {}
}
function step_setAndGetGreeting() public {
ExampleHelloWorld example = new ExampleHelloWorld();
address exampleAddress = address(example);
assertRole(helloWorld.readAllowList(exampleAddress), AllowList.Role.None);
helloWorld.setEnabled(exampleAddress);
assertRole(
helloWorld.readAllowList(exampleAddress),
AllowList.Role.Enabled
);
string memory greeting = "testgreeting";
example.setGreeting(greeting);
assertEq(example.sayHello(), greeting);
}
}
```
## Adding DS-Test Case
We can now trigger this test contract via `hardhat` tests. The test script uses Subnet-EVM's `test` framework test in `./contracts/test`. You can find more information about the test framework [here](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/contracts/test/utils.ts). We also can test the events emitted by the precompile. The test script looks like this:
The test script looks like this:
```go
// (c) 2019-2022, Ava Labs, Inc. All rights reserved.
// See the file LICENSE for licensing terms.
import { expect } from "chai";
import { SignerWithAddress } from "@nomiclabs/hardhat-ethers/signers";
import { Contract } from "ethers";
import { ethers } from "hardhat";
import { test } from "./utils";
// make sure this is always an admin for hello world precompile
const ADMIN_ADDRESS = "0x8db97C7cEcE249c2b98bDC0226Cc4C2A57BF52FC";
const HELLO_WORLD_ADDRESS = "0x0300000000000000000000000000000000000000";
describe("ExampleHelloWorldTest", function () {
this.timeout("30s");
beforeEach("Setup DS-Test contract", async function () {
const signer = await ethers.getSigner(ADMIN_ADDRESS);
const helloWorldPromise = ethers.getContractAt(
"IHelloWorld",
HELLO_WORLD_ADDRESS,
signer
);
return ethers
.getContractFactory("ExampleHelloWorldTest", { signer })
.then((factory) => factory.deploy())
.then((contract) => {
this.testContract = contract;
return contract.deployed().then(() => contract);
})
.then(() => Promise.all([helloWorldPromise]))
.then(([helloWorld]) => helloWorld.setAdmin(this.testContract.address))
.then((tx) => tx.wait());
});
test("should gets default hello world", ["step_getDefaultHelloWorld"]);
test(
"should not set greeting before enabled",
"step_doesNotSetGreetingBeforeEnabled"
);
test(
"should set and get greeting with enabled account",
"step_setAndGetGreeting"
);
});
describe("IHelloWorld events", function () {
let owner: SignerWithAddress;
let contract: Contract;
let defaultGreeting = "Hello, World!";
before(async function () {
owner = await ethers.getSigner(ADMIN_ADDRESS);
contract = await ethers.getContractAt(
"IHelloWorld",
HELLO_WORLD_ADDRESS,
owner
);
// reset greeting
let tx = await contract.setGreeting(defaultGreeting);
await tx.wait();
});
it("should emit GreetingChanged event", async function () {
let newGreeting = "helloprecompile";
await expect(contract.setGreeting(newGreeting))
.to.emit(contract, "GreetingChanged")
.withArgs(
owner.address,
// old greeting
defaultGreeting,
// new greeting
newGreeting
);
});
});
```
The test script looks like this:
```go
// (c) 2019-2022, Ava Labs, Inc. All rights reserved.
// See the file LICENSE for licensing terms.
import { expect } from "chai";
import { SignerWithAddress } from "@nomiclabs/hardhat-ethers/signers";
import { Contract } from "ethers";
import { ethers } from "hardhat";
import { test } from "@avalabs/subnet-evm-contracts";
// make sure this is always an admin for hello world precompile
const ADMIN_ADDRESS = "0x8db97C7cEcE249c2b98bDC0226Cc4C2A57BF52FC";
const HELLO_WORLD_ADDRESS = "0x0300000000000000000000000000000000000000";
describe("ExampleHelloWorldTest", function () {
this.timeout("30s");
beforeEach("Setup DS-Test contract", async function () {
const signer = await ethers.getSigner(ADMIN_ADDRESS);
const helloWorldPromise = ethers.getContractAt(
"IHelloWorld",
HELLO_WORLD_ADDRESS,
signer
);
return ethers
.getContractFactory("ExampleHelloWorldTest", { signer })
.then((factory) => factory.deploy())
.then((contract) => {
this.testContract = contract;
return contract.deployed().then(() => contract);
})
.then(() => Promise.all([helloWorldPromise]))
.then(([helloWorld]) => helloWorld.setAdmin(this.testContract.address))
.then((tx) => tx.wait());
});
test("should gets default hello world", ["step_getDefaultHelloWorld"]);
test(
"should not set greeting before enabled",
"step_doesNotSetGreetingBeforeEnabled"
);
test(
"should set and get greeting with enabled account",
"step_setAndGetGreeting"
);
});
describe("IHelloWorld events", function () {
let owner: SignerWithAddress;
let contract: Contract;
let defaultGreeting = "Hello, World!";
before(async function () {
owner = await ethers.getSigner(ADMIN_ADDRESS);
contract = await ethers.getContractAt(
"IHelloWorld",
HELLO_WORLD_ADDRESS,
owner
);
// reset greeting
let tx = await contract.setGreeting(defaultGreeting);
await tx.wait();
});
it("should emit GreetingChanged event", async function () {
let newGreeting = "helloprecompile";
await expect(contract.setGreeting(newGreeting))
.to.emit(contract, "GreetingChanged")
.withArgs(
owner.address,
// old greeting
defaultGreeting,
// new greeting
newGreeting
);
});
});
```
# Executing Test Cases
URL: /docs/virtual-machines/custom-precompiles/executing-test-cases
In this section, we will go over how to be able to execute the test cases you wrote in the last section.
## Adding the Test Genesis File
To run our e2e contract tests, we will need to create an Avalanche L1 that has the `Hello World` precompile activated, so we will copy and paste the below genesis file into: `/tests/precompile/genesis/hello_world.json`.
Note: it's important that this has the same name as the HardHat test file we created previously.
```json
{
"config": {
"chainId": 99999,
"homesteadBlock": 0,
"eip150Block": 0,
"eip150Hash": "0x2086799aeebeae135c246c65021c82b4e15a2c451340993aacfd2751886514f0",
"eip155Block": 0,
"eip158Block": 0,
"byzantiumBlock": 0,
"constantinopleBlock": 0,
"petersburgBlock": 0,
"istanbulBlock": 0,
"muirGlacierBlock": 0,
"feeConfig": {
"gasLimit": 20000000,
"minBaseFee": 1000000000,
"targetGas": 100000000,
"baseFeeChangeDenominator": 48,
"minBlockGasCost": 0,
"maxBlockGasCost": 10000000,
"targetBlockRate": 2,
"blockGasCostStep": 500000
},
"helloWorldConfig": {
"blockTimestamp": 0,
"adminAddresses": ["0x8db97C7cEcE249c2b98bDC0226Cc4C2A57BF52FC"]
}
},
"alloc": {
"8db97C7cEcE249c2b98bDC0226Cc4C2A57BF52FC": {
"balance": "0x52B7D2DCC80CD2E4000000"
},
"0x0Fa8EA536Be85F32724D57A37758761B86416123": {
"balance": "0x52B7D2DCC80CD2E4000000"
}
},
"nonce": "0x0",
"timestamp": "0x66321C34",
"extraData": "0x00",
"gasLimit": "0x1312D00",
"difficulty": "0x0",
"mixHash": "0x0000000000000000000000000000000000000000000000000000000000000000",
"coinbase": "0x0000000000000000000000000000000000000000",
"number": "0x0",
"gasUsed": "0x0",
"parentHash": "0x0000000000000000000000000000000000000000000000000000000000000000"
}
```
Adding this to our genesis enables our HelloWorld precompile at the genesis block (0th block), with `0x8db97C7cEcE249c2b98bDC0226Cc4C2A57BF52FC` as the admin address.
```json
{
"helloWorldConfig": {
"blockTimestamp": 0,
"adminAddresses": ["0x8db97C7cEcE249c2b98bDC0226Cc4C2A57BF52FC"]
}
}
```
## Declaring the HardHat E2E Test
Now that we have declared the HardHat test and corresponding `genesis.json` file. The last step to running the e2e test is to declare the new test in `/tests/precompile/solidity/suites.go`.
At the bottom of the file you will see the following code commented out:
```go title="suites.go"
// ADD YOUR PRECOMPILE HERE
/*
ginkgo.It("your precompile", ginkgo.Label("Precompile"), ginkgo.Label("YourPrecompile"), func() {
ctx, cancel := context.WithTimeout(context.Background(), time.Minute)
defer cancel()
// Specify the name shared by the genesis file in ./tests/precompile/genesis/{your_precompile}.json
// and the test file in ./contracts/tests/{your_precompile}.ts
blockchainID := subnetsSuite.GetBlockchainID("{your_precompile}")
runDefaultHardhatTests(ctx, blockchainID, "{your_precompile}")
*/
```
`runDefaultHardhatTests` will run the default Hardhat test command and use the default genesis path. If you want to use a different test command and genesis path than the defaults, you can use the `utils.CreateSubnet` and `utils.RunTestCMD`. See how they were used with default params [here](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/tests/utils/subnet.go#L113)
You should copy and paste the ginkgo `It` node and update from `{your_precompile}` to `hello_world`. The string passed in to `utils.RunDefaultHardhatTests(ctx, "your_precompile")` will be used to find both the HardHat test file to execute and the genesis file, which is why you need to use the same name for both.
After modifying the `It` node, it should look like the following (you can copy and paste this directly if you prefer):
```go
ginkgo.It("hello world", ginkgo.Label("Precompile"), ginkgo.Label("HelloWorld"), func() {
ctx, cancel := context.WithTimeout(context.Background(), time.Minute)
defer cancel()
blockchainID := subnetsSuite.GetBlockchainID("hello_world")
runDefaultHardhatTests(ctx, blockchainID, "hello_world")
})
```
Now that we've set up the new ginkgo test, we can run the ginkgo test that we want by using the `GINKGO_LABEL_FILTER`. This environment variable is passed as a flag to Ginkgo in `./scripts/run_ginkgo.sh` and restricts what tests will run to only the tests with a matching label.
## Running E2E Tests
Before we start testing, we will need to build the AvalancheGo binary and the custom Subnet-EVM binary.
Precompile-EVM bundles Subnet-EVM and runs it under the hood in the [`plugins/main.go`](https://github.com/ava-labs/precompile-evm/blob/hello-world-example/plugin/main.go#L24). Meaning that Precompile-EVM binary works the same way as Subnet-EVM binary. Precompile-EVM repo has also same scripts and the build process as Subnet-EVM. Following steps also apply to Precompile-EVM.
You should have cloned [AvalancheGo](https://github.com/ava-labs/avalanchego) within your `$GOPATH` in the [Background and Requirements](/docs/virtual-machines/custom-precompiles/background-requirements) section, so you can build AvalancheGo with the following command:
```bash
cd $GOPATH/src/github.com/ava-labs/avalanchego
./scripts/build.sh
```
Once you've built AvalancheGo, you can confirm that it was successful by printing the version:
```bash
./build/avalanchego --version
```
This should print something like the following (if you are running AvalancheGo v1.9.7):
```bash
avalanchego/1.11.0 [database=v1.4.5, rpcchainvm=33, commit=c60f7d2dd10c87f57382885b59d6fb2c763eded7, go=1.21.7]
```
This path will be used later as the environment variable `AVALANCHEGO_EXEC_PATH` in the network runner.
Please note that the RPCChainVM version of AvalancheGo and Subnet-EVM must match.
Once we've built AvalancheGo, we can navigate back to the repo and build the binary:
```bash
cd $GOPATH/src/github.com/ava-labs/subnet-evm
./scripts/build.sh
```
This will build the Subnet-EVM binary and place it in AvalancheGo's `build/plugins` directory by default at the file path: `$GOPATH/src/github.com/ava-labs/avalanchego/build/plugins/srEXiWaHuhNyGwPUi444Tu47ZEDwxTWrbQiuD7FmgSAQ6X7Dy`
To confirm that the Subnet-EVM binary is compatible with AvalancheGo, you can run the same version command and confirm the RPCChainVM version matches:
```bash
$GOPATH/src/github.com/ava-labs/avalanchego/build/plugins/srEXiWaHuhNyGwPUi444Tu47ZEDwxTWrbQiuD7FmgSAQ6X7Dy --version
```
This should give similar output:
```bash
Subnet-EVM/v0.6.1 [AvalancheGo=v1.11.1, rpcchainvm=33]
```
```bash
cd $GOPATH/src/github.com/ava-labs/precompile-evm
./scripts/build.sh
```
This will build the Precompile-EVM binary and place it in AvalancheGo's `build/plugins` directory by default at the file path: `$GOPATH/src/github.com/ava-labs/avalanchego/build/plugins/srEXiWaHuhNyGwPUi444Tu47ZEDwxTWrbQiuD7FmgSAQ6X7Dy`
To confirm that the Precompile-EVM binary is compatible with AvalancheGo, you can run the same version command and confirm the RPCChainVM version matches:
```bash
$GOPATH/src/github.com/ava-labs/avalanchego/build/plugins/srEXiWaHuhNyGwPUi444Tu47ZEDwxTWrbQiuD7FmgSAQ6X7Dy --version
```
This should give similar output:
```bash
Precompile-EVM/v0.2.0 Subnet-EVM/v0.6.1 [AvalancheGo=v1.11.1, rpcchainvm=33]
```
If the RPCChainVM Protocol version printed out does not match the one used in AvalancheGo then Subnet-EVM will not be able to talk to AvalancheGo and the blockchain will not start. You can find the compatibility table for AvalancheGo and Subnet-EVM [here](https://github.com/ava-labs/subnet-evm#avalanchego-compatibility).
The `build/plugins` directory will later be used as the `AVALANCHEGO_PLUGIN_PATH`.
### Running Ginkgo Tests
To run ONLY the HelloWorld precompile test, run the command:
```bash
cd $GOPATH/src/github.com/ava-labs/subnet-evm
```
```bash
cd $GOPATH/src/github.com/ava-labs/precompile-evm
```
use `GINKGO_LABEL_FILTER` env var to filter the test:
```bash
GINKGO_LABEL_FILTER=HelloWorld ./scripts/run_ginkgo.sh
```
You will first see the node starting up in the `BeforeSuite` section of the precompile test:
```bash
GINKGO_LABEL_FILTER=HelloWorld ./scripts/run_ginkgo.sh
# output
Using branch: hello-world-tutorial-walkthrough
building precompile.test
# github.com/ava-labs/subnet-evm/tests/precompile.test
ld: warning: could not create compact unwind for _blst_sha256_block_data_order: does not use RBP or RSP based frame
Compiled precompile.test
# github.com/ava-labs/subnet-evm/tests/load.test
ld: warning: could not create compact unwind for _blst_sha256_block_data_order: does not use RBP or RSP based frame
Compiled load.test
Running Suite: subnet-evm precompile ginkgo test suite - /Users/avalabs/go/src/github.com/ava-labs/subnet-evm
===================================================================================================================
Random Seed: 1674833631
Will run 1 of 7 specs
------------------------------
[BeforeSuite]
/Users/avalabs/go/src/github.com/ava-labs/subnet-evm/tests/precompile/precompile_test.go:31
> Enter [BeforeSuite] TOP-LEVEL - /Users/avalabs/go/src/github.com/ava-labs/subnet-evm/tests/precompile/precompile_test.go:31 @ 01/27/23 10:33:51.001
INFO [01-27|10:33:51.002] Starting AvalancheGo node wd=/Users/avalabs/go/src/github.com/ava-labs/subnet-evm
INFO [01-27|10:33:51.002] Executing cmd="./scripts/run.sh "
[streaming output] Using branch: hello-world-tutorial-walkthrough
...
[BeforeSuite] PASSED [15.002 seconds]
```
After the `BeforeSuite` completes successfully, it will skip all but the `HelloWorld` labeled precompile test:
```bash
S [SKIPPED]
[Precompiles]
/Users/avalabs/go/src/github.com/ava-labs/subnet-evm/tests/precompile/solidity/suites.go:26
contract native minter [Precompile, ContractNativeMinter]
/Users/avalabs/go/src/github.com/ava-labs/subnet-evm/tests/precompile/solidity/suites.go:29
------------------------------
S [SKIPPED]
[Precompiles]
/Users/avalabs/go/src/github.com/ava-labs/subnet-evm/tests/precompile/solidity/suites.go:26
tx allow list [Precompile, TxAllowList]
/Users/avalabs/go/src/github.com/ava-labs/subnet-evm/tests/precompile/solidity/suites.go:36
------------------------------
...
Combined output:
Compiling 2 files with 0.8.0
Compilation finished successfully
ExampleHelloWorldTest
✓ should gets default hello world (4057ms)
✓ should not set greeting before enabled (4067ms)
✓ should set and get greeting with enabled account (4074ms)
3 passing (33s)
< Exit [It] hello world - /Users/avalabs/go/src/github.com/ava-labs/subnet-evm/tests/precompile/solidity/suites.go:64 @ 01/27/23 10:34:17.484 (11.48s)
• [11.480 seconds]
------------------------------
```
Finally, you will see the load test being skipped as well:
```bash
Running Suite: subnet-evm small load simulator test suite - /Users/avalabs/go/src/github.com/ava-labs/subnet-evm
======================================================================================================================
Random Seed: 1674833658
Will run 0 of 1 specs
S [SKIPPED]
[Load Simulator]
/Users/avalabs/go/src/github.com/ava-labs/subnet-evm/tests/load/load_test.go:49
basic subnet load test [load]
/Users/avalabs/go/src/github.com/ava-labs/subnet-evm/tests/load/load_test.go:50
------------------------------
Ran 0 of 1 Specs in 0.000 seconds
SUCCESS! -- 0 Passed | 0 Failed | 0 Pending | 1 Skipped
PASS
```
Looks like the tests are passing!
If your tests failed, please retrace your steps. Most likely the error is that the precompile was not enabled and some code is missing. Try running `npm install` in the contracts directory to ensure that hardhat and other packages are installed.
You may also use the [official tutorial implementation](https://github.com/ava-labs/subnet-evm/tree/helloworld-official-tutorial-v2) to double-check your work as well.
# Custom Precompiles
URL: /docs/virtual-machines/custom-precompiles
In this tutorial, we are going to walk through how we can generate a stateful precompile from scratch. Before we start, let's brush up on what a precompile is, what a stateful precompile is, and why this is extremely useful.
## Background
### Precompiled Contracts
Ethereum uses precompiles to efficiently implement cryptographic primitives within the EVM instead of re-implementing the same primitives in Solidity. The following precompiles are currently included: ecrecover, sha256, blake2f, ripemd-160, Bn256Add, Bn256Mul, Bn256Pairing, the identity function, and modular exponentiation.
We can see these [precompile](https://github.com/ethereum/go-ethereum/blob/v1.11.1/core/vm/contracts.go#L82) mappings from address to function here in the Ethereum VM:
```go
// PrecompiledContractsBerlin contains the default set of pre-compiled Ethereum
// contracts used in the Berlin release.
var PrecompiledContractsBerlin = map[common.Address]PrecompiledContract{
common.BytesToAddress([]byte{1}): &ecrecover{},
common.BytesToAddress([]byte{2}): &sha256hash{},
common.BytesToAddress([]byte{3}): &ripemd160hash{},
common.BytesToAddress([]byte{4}): &dataCopy{},
common.BytesToAddress([]byte{5}): &bigModExp{eip2565: true},
common.BytesToAddress([]byte{6}): &bn256AddIstanbul{},
common.BytesToAddress([]byte{7}): &bn256ScalarMulIstanbul{},
common.BytesToAddress([]byte{8}): &bn256PairingIstanbul{},
common.BytesToAddress([]byte{9}): &blake2F{},
}
```
These precompile addresses start from `0x0000000000000000000000000000000000000001` and increment by 1.
A [precompile](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/core/vm/contracts.go#L54-L57) follows this interface:
```go
// PrecompiledContract is the basic interface for native Go contracts. The implementation
// requires a deterministic gas count based on the input size of the Run method of the
// contract.
type PrecompiledContract interface {
RequiredGas(input []byte) uint64 // RequiredPrice calculates the contract gas use
Run(input []byte) ([]byte, error) // Run runs the precompiled contract
}
```
Here is an example of the [sha256 precompile](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/core/vm/contracts.go#L237-L250) function.
```go
type sha256hash struct{}
// RequiredGas returns the gas required to execute the pre-compiled contract.
//
// This method does not require any overflow checking as the input size gas costs
// required for anything significant is so high it's impossible to pay for.
func (c *sha256hash) RequiredGas(input []byte) uint64 {
return uint64(len(input)+31)/32*params.Sha256PerWordGas + params.Sha256BaseGas
}
func (c *sha256hash) Run(input []byte) ([]byte, error) {
h := sha256.Sum256(input)
return h[:], nil
}
```
The CALL opcode (CALL, STATICCALL, DELEGATECALL, and CALLCODE) allows us to invoke this precompile.
The function signature of CALL in the EVM is as follows:
```go
Call(
caller ContractRef,
addr common.Address,
input []byte,
gas uint64,
value *big.Int,
)(ret []byte, leftOverGas uint64, err error)
```
Precompiles are a shortcut to execute a function implemented by the EVM itself, rather than an actual contract. A precompile is associated with a fixed address defined in the EVM. There is no byte code associated with that address.
When a precompile is called, the EVM checks if the input address is a precompile address, and if so it executes the precompile. Otherwise, it loads the smart contract at the input address and runs it on the EVM interpreter with the specified input data.
### Stateful Precompiled Contracts
A stateful precompile builds on a precompile in that it adds state access. Stateful precompiles are not available in the default EVM, and are specific to Avalanche EVMs such as [Coreth](https://github.com/ava-labs/coreth) and [Subnet-EVM](https://github.com/ava-labs/subnet-evm).
A stateful precompile follows this [interface](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/precompile/contract/interfaces.go#L17-L20):
```go
// StatefulPrecompiledContract is the interface for executing a precompiled contract
type StatefulPrecompiledContract interface {
// Run executes the precompiled contract.
Run(accessibleState PrecompileAccessibleState,
caller common.Address,
addr common.Address,
input []byte,
suppliedGas uint64,
readOnly bool)
(ret []byte, remainingGas uint64, err error)
}
```
A stateful precompile injects state access through the `PrecompileAccessibleState` interface to provide access to the EVM state including the ability to modify balances and read/write storage.
This way we can provide even more customization of the EVM through Stateful Precompiles than we can with the original precompile interface!
### AllowList
The AllowList enables a precompile to enforce permissions on addresses. The AllowList is not a contract itself, but a helper structure to provide a control mechanism for wrapping contracts. It provides an `AllowListConfig` to the precompile so that it can take an initial configuration from genesis/upgrade. It also provides functions to set/read the permissions. In this tutorial, we used `IAllowList` interface to provide permission control to the `HelloWorld` precompile. `IAllowList` is defined in Subnet-EVM under [`./contracts/contracts/interfaces/IAllowList.sol`](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/contracts/contracts/interfaces/IAllowList.sol). The interface is as follows:
```go
//SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
interface IAllowList {
event RoleSet(
uint256 indexed role,
address indexed account,
address indexed sender,
uint256 oldRole
);
// Set [addr] to have the admin role over the precompile contract.
function setAdmin(address addr) external;
// Set [addr] to be enabled on the precompile contract.
function setEnabled(address addr) external;
// Set [addr] to have the manager role over the precompile contract.
function setManager(address addr) external;
// Set [addr] to have no role for the precompile contract.
function setNone(address addr) external;
// Read the status of [addr].
function readAllowList(address addr) external view returns (uint256 role);
}
```
You can find more information about the AllowList interface [here](/docs/avalanche-l1s/upgrade/customize-avalanche-l1#allowlist-interface).
# Deploying Your Precompile
URL: /docs/virtual-machines/custom-precompiles/precompile-deployment
Now that we have defined our precompile, let's deploy it to a local network.
We made it! Everything works in our Ginkgo tests, and now we want to spin up a local network with the Hello World precompile activated.
Start the server in a terminal in a new tab using avalanche-network-runner. Please check out [this link](/docs/tooling/avalanche-network-runner/introduction) for more information on Avalanche Network Runner, how to download it, and how to use it. The server will be in "listening" mode waiting for API calls.
We will start the server from the Subnet-EVM directory so that we can use a relative file path to the genesis JSON file:
```bash
cd $GOPATH/src/github.com/ava-labs/subnet-evm
```
```bash
cd $GOPATH/src/github.com/ava-labs/precompile-evm
```
Then run ANR:
```bash
avalanche-network-runner server \
--log-level debug \
--port=":8080" \
--grpc-gateway-port=":8081"
```
Since we already compiled AvalancheGo and Subnet-EVM/Precompile-EVM in a previous step, we should have the AvalancheGo and Subnet-EVM binaries ready to go.
We can now set the following paths. `AVALANCHEGO_EXEC_PATH` points to the latest AvalancheGo binary we have just built. `AVALANCHEGO_PLUGIN_PATH` points to the plugins path which should have the Subnet-EVM binary we have just built:
```bash
export AVALANCHEGO_EXEC_PATH="${GOPATH}/src/github.com/ava-labs/avalanchego/build/avalanchego"
export AVALANCHEGO_PLUGIN_PATH="${HOME}/.avalanchego/plugins"
```
The following command will "issue requests" to the server we just spun up. We can use avalanche-network-runner to spin up some nodes that run the latest version of Subnet-EVM:
```bash
avalanche-network-runner control start \
--log-level debug \
--endpoint="0.0.0.0:8080" \
--number-of-nodes=5 \
--avalanchego-path ${AVALANCHEGO_EXEC_PATH} \
--plugin-dir ${AVALANCHEGO_PLUGIN_PATH} \
--blockchain-specs '[{"vm_name": "subnetevm", "genesis": "./tests/precompile/genesis/hello_world.json"}]'
```
We can look at the server terminal tab and see it booting up the local network. If the network startup is successful then you should see something like this:
```bash
[blockchain RPC for "srEXiWaHuhNyGwPUi444Tu47ZEDwxTWrbQiuD7FmgSAQ6X7Dy"] "http://127.0.0.1:9650/ext/bc/2jDWMrF9yKK8gZfJaaaSfACKeMasiNgHmuZip5mWxUfhKaYoEU"
[blockchain RPC for "srEXiWaHuhNyGwPUi444Tu47ZEDwxTWrbQiuD7FmgSAQ6X7Dy"] "http://127.0.0.1:9652/ext/bc/2jDWMrF9yKK8gZfJaaaSfACKeMasiNgHmuZip5mWxUfhKaYoEU"
[blockchain RPC for "srEXiWaHuhNyGwPUi444Tu47ZEDwxTWrbQiuD7FmgSAQ6X7Dy"] "http://127.0.0.1:9654/ext/bc/2jDWMrF9yKK8gZfJaaaSfACKeMasiNgHmuZip5mWxUfhKaYoEU"
[blockchain RPC for "srEXiWaHuhNyGwPUi444Tu47ZEDwxTWrbQiuD7FmgSAQ6X7Dy"] "http://127.0.0.1:9656/ext/bc/2jDWMrF9yKK8gZfJaaaSfACKeMasiNgHmuZip5mWxUfhKaYoEU"
[blockchain RPC for "srEXiWaHuhNyGwPUi444Tu47ZEDwxTWrbQiuD7FmgSAQ6X7Dy"] "http://127.0.0.1:9658/ext/bc/2jDWMrF9yKK8gZfJaaaSfACKeMasiNgHmuZip5mWxUfhKaYoEU"
```
This shows the extension to the API server on AvalancheGo that's specific to the Subnet-EVM Blockchain instance. To interact with it, you will want to append the `/rpc` extension, which will supply the standard Ethereum API calls.
For example, you can use the RPC URL: `http://127.0.0.1:9650/ext/bc/2jDWMrF9yKK8gZfJaaaSfACKeMasiNgHmuZip5mWxUfhKaYoEU/rpc`
## Maintenance
You should always keep your fork up to date with the latest changes in the official Subnet-EVM repo. If you have forked the Subnet-EVM repo, there could be conflicts and you may need to manually resolve them.
If you used Precompile-EVM, you can update your repo by bumping Subnet-EVM versions in [`go.mod`](https://github.com/ava-labs/precompile-evm/blob/hello-world-example/go.mod#L7) and [`version.sh`](https://github.com/ava-labs/precompile-evm/blob/hello-world-example/scripts/versions.sh#L4)
## Conclusion
We have now created a stateful precompile from scratch with the precompile generation tool. We hope you had fun and learned a little more about the Subnet-EVM. Now that you have created a simple stateful precompile, we urge you to create one of your own.
If you have an idea for a stateful precompile that may be useful to the community, feel free to create a fork of [Subnet-EVM](https://github.com/ava-labs/subnet-evm) and create a pull request.
# Installing Your VM
URL: /docs/virtual-machines/rust-vms/installing-vm
Learn how to install your VM on your node.
AvalancheGo searches for and registers VM plugins under the `plugins` [directory](/docs/nodes/configure/configs-flags#--plugin-dir-string).
To install the virtual machine onto your node, you need to move the built virtual machine binary under this directory. Virtual machine executable names must be either a full virtual machine ID (encoded in CB58), or a VM alias.
Copy the binary into the plugins directory.
```bash
cp -n $GOPATH/src/github.com/ava-labs/avalanchego/build/plugins/
```
## Node Is Not Running
If your node isn't running yet, you can install all virtual machines under your `plugin` directory by starting the node.
## Node Is Already Running
Load the binary with the `loadVMs` API.
```bash
curl -sX POST --data '{
"jsonrpc":"2.0",
"id" :1,
"method" :"admin.loadVMs",
"params" :{}
}' -H 'content-type:application/json;' 127.0.0.1:9650/ext/admin
```
Confirm the response of `loadVMs` contains the newly installed virtual machine `tGas3T58KzdjcJ32c6GpePhtqo9rrHJ1oR9wFBtCcMgaosthX`. You'll see this virtual machine as well as any others that weren't already installed previously in the response.
```json
{
"jsonrpc": "2.0",
"result": {
"newVMs": {
"tGas3T58KzdjcJ32c6GpePhtqo9rrHJ1oR9wFBtCcMgaosthX": [
"timestampvm-rs",
"timestamp-rs"
],
"spdxUxVJQbX85MGxMHbKw1sHxMnSqJ3QBzDyDYEP3h6TLuxqQ": []
}
},
"id": 1
}
```
Now, this VM's static API can be accessed at endpoints `/ext/vm/timestampvm-rs` and `/ext/vm/timestamp-rs`. For more details about VM configs, see [here](/docs/nodes/configure/configs-flags#virtual-machine-vm-configs).
In this tutorial, we used the VM's ID as the executable name to simplify the process. However, AvalancheGo would also accept `timestampvm-rs` or `timestamp-rs` since those are registered aliases in previous step.
# Introduction to Avalanche-RS
URL: /docs/virtual-machines/rust-vms/intro-avalanche-rs
Learn how to write a simple virtual machine in Rust using Avalanche-RS.
Since Rust is a language which we can write and implement Proto interfaces, this implies that we can also use Rust to write VMs which can then be deployed on Avalanche.
However, rather than build Rust-based from the ground-up, we can utilize Avalanche-RS, a developer toolkit comprised of powerful building blocks and primitive types which allow us to focus exclusively on the business logic of our VM rather than working on low-level logic.
## Structure of Avalanche-RS
Although Avalanche-RS is currently primarily used to build Rust-based VMs, Avalanche-RS actually consists of three different frameworks; as per the [GitHub](https://github.com/ava-labs/avalanche-rs) description of the Avalanche-RS repository, the three frameworks are as follows:
* Core: framework for core networking components for a P2P Avalanche node
* Avalanche-Consensus: a Rust implementation of the novel Avalanche consensus protocol
* Avalanche-Types: implements foundational types used in Avalanche and provides an SDK for building Rust-based VMs
As the above might make it obvious, the Avalanche-Types crate is the main framework that one would use to build Rust-based VMs.
## Documentation
For the most up-to-date information regarding the Avalache-Types library, please refer to the associated [crates.io](https://crates.io/crates/avalanche-types) page for the Avalanche-Types crate.
# Setting Up Your Environment
URL: /docs/virtual-machines/rust-vms/setting-up-environment
Learn how to set up your environment to build a Rust VM.
In this section, we will focus on getting set up with the Rust environment necessary to build with the `avalanche-types` crates (recall that `avalanche-types` contains the SDK we want to use to build our Rust VM).
## Installing Rust
First and foremost, we will need to have Rust installed locally. If you do not have Rust installed, you can install `rustup` (the tool that manages your Rust installation) [here](https://www.rust-lang.org/tools/install).
## Adding `avalanche-types` to Your Project
Once you have Rust installed and are ready to build, you will want to add the Avalanche-Types crate to your project. Below is a baseline example of how you can do this:
```toml title="Cargo.toml"
[dependencies]
avalanche-types = "0.1.4"
```
However, if you want to use the [TimestampVM](https://github.com/ava-labs/timestampvm-rs) as a reference for your project, a more appropriate import would be the following:
```toml title="Cargo.toml"
[dependencies]
avalanche-types = { version = "0.1.4", features = ["subnet", "codec_base64"] }
```
# APIs
URL: /docs/virtual-machines/timestamp-vm/apis
Learn how to interact with TimestampVM.
Throughout this case study, we have been focusing of the functionality of the TimestampVM. However, one thing we haven't discussed is how external users can interact with an instance of TimestampVM.
Without a way for users to interact with TimestampVM, the blockchain itself will be stagnant. In this section, we will go over the two types of APIs used in TimestampVM:
* Static APIs
* Chain APIs
## Precursor: Static and Instance Methods
When understanding the static and chain APIs used in TimestampVM, a good way to think about these APIs is to compare them to static and instance methods in object-oriented programming. That is,
* **Static Methods**: functions which belong to the class itself, and not any instance of the class
* **Instance Methods**: functions which belong to the instance of a class
## Static APIs
We can think of the static APIs in TimestampVM as functions which call the VM and are not associated with any specific instance of the TimestampVM. Within TimestampVM, we have just one static API function - the ping function:
```rust title="timestampvm/src/api/static_handlers.rs"
/// Defines static handler RPCs for this VM.
#[rpc]
pub trait Rpc {
#[rpc(name = "ping", alias("timestampvm.ping"))]
fn ping(&self) -> BoxFuture>;
}
```
## Chain APIs
In contrast to the static API, the chain API of TimestampVM is much more rich in the sense that we have functions with read from and write to an instance of TimestampVM. In this case, we have four functions defined in the chain API:
* `ping`: when called, this function pings an instance of TimestampVM
* `propose_Block`: write function which passes a block to TimestampVM for consideration to be appended to the blockchain
* `last_accepted`: read function which returns the last accepted block (that is, the block at the tip of the blockchain)
* `get_block`: read function which fetches the requested block
We can see the functions included in the chain API here:
```rust title="timestampvm/src/api/chain_handlers.rs"
/// Defines RPCs specific to the chain.
#[rpc]
pub trait Rpc {
/// Pings th e VM.
#[rpc(name = "ping", alias("timestampvm.ping"))]
fn ping(&self) -> BoxFuture
 ***
We introduce "acceptance proofs", so that a peer can verify any block accepted by consensus. In the aforementioned use-case, if a P-Chain block is unknown by a peer, it can request the block and proof at the provided height from a peer. If a block's proof is valid, the block can be executed to advance the local P-Chain and verify the proposed subnet block. Peers can request blocks from any peer without requiring consensus locally or communication with a validator. This has the added benefit of reducing the number of required connections and p2p message load served by P-Chain validators.
***
Figure 2: A Validator is verifying a subnet’s block `Z` which references an unknown P-Chain block `C` in its block header
***
We introduce "acceptance proofs", so that a peer can verify any block accepted by consensus. In the aforementioned use-case, if a P-Chain block is unknown by a peer, it can request the block and proof at the provided height from a peer. If a block's proof is valid, the block can be executed to advance the local P-Chain and verify the proposed subnet block. Peers can request blocks from any peer without requiring consensus locally or communication with a validator. This has the added benefit of reducing the number of required connections and p2p message load served by P-Chain validators.
***
Figure 2: A Validator is verifying a subnet’s block `Z` which references an unknown P-Chain block `C` in its block header
 Figure 3: A Validator requests the blocks and proofs for `B` and `C` from a peer
Figure 3: A Validator requests the blocks and proofs for `B` and `C` from a peer
 Figure 4: The Validator accepts the P-Chain blocks and is now able to verify `Z`
Figure 4: The Validator accepts the P-Chain blocks and is now able to verify `Z`
 ***
## Specification
Note: The following is pseudocode.
### P2P
#### Aggregation
```diff
+ message GetAcceptanceSignatureRequest {
+ bytes chain_id = 1;
+ uint32 request_id = 2;
+ bytes block_id = 3;
+ }
```
The `GetAcceptanceSignatureRequest` message is sent to a peer to request their signature for a given block id.
```diff
+ message GetAcceptanceSignatureResponse {
+ bytes chain_id = 1;
+ uint32 request_id = 2;
+ bytes bls_signature = 3;
+ }
```
`GetAcceptanceSignatureResponse` is sent to a peer as a response for `GetAcceptanceSignatureRequest`. `bls_signature` is the peer’s signature using their registered primary network BLS staking key over the requested `block_id`. An empty `bls_signature` field indicates that the block was not accepted yet.
## Security Considerations
Nodes that bootstrap using state sync may not have the entire history of the
P-Chain and therefore will not be able to provide the entire history for a block
that is referenced in a block that they propose. This would be needed to unblock a node that is attempting to fast-forward their P-Chain, as they require the entire ancestry between their current accepted tip and the block they are attempting to forward to. It is assumed that nodes will have some minimum amount of recent state so that the requester can eventually be unblocked by retrying, as only one node with the requested ancestry is required to unblock the requester.
An alternative is to make a churn assumption and validate the proposed block's proof with a stale validator set to avoid complexity, but this introduces more security concerns.
## Copyright
Copyright and related rights waived via [CC0](https://creativecommons.org/publicdomain/zero/1.0/).
# ACP-77: Reinventing Subnets
URL: /docs/acps/77-reinventing-subnets
Details for Avalanche Community Proposal 77: Reinventing Subnets
| ACP | 77 |
| :------------ | :-------------------------------------------------------------------------------------------------------- |
| **Title** | Reinventing Subnets |
| **Author(s)** | Dhruba Basu ([@dhrubabasu](https://github.com/dhrubabasu)) |
| **Status** | Activated ([Discussion](https://github.com/avalanche-foundation/ACPs/discussions/78)) |
| **Track** | Standards |
| **Replaces** | [ACP-13](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/13-subnet-only-validators/README.md) |
## Abstract
Overhaul Subnet creation and management to unlock increased flexibility for Subnet creators by:
* Separating Subnet validators from Primary Network validators (Primary Network Partial Sync, Removal of 2000 \$AVAX requirement)
* Moving ownership of Subnet validator set management from P-Chain to Subnets (ERC-20/ERC-721/Arbitrary Staking, Staking Reward Management)
* Introducing a continuous P-Chain fee mechanism for Subnet validators (Continuous Subnet Staking)
This ACP supersedes [ACP-13](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/13-subnet-only-validators/README.md) and borrows some of its language.
## Motivation
Each node operator must stake at least 2000 $AVAX ($70k at time of writing) to first become a Primary Network validator before they qualify to become a Subnet validator. Most Subnets aim to launch with at least 8 Subnet validators, which requires staking 16000 $AVAX ($560k at time of writing). All Subnet validators, to satisfy their role as Primary Network validators, must also [allocate 8 AWS vCPU, 16 GB RAM, and 1 TB storage](https://github.com/ava-labs/avalanchego/blob/master/README.md#installation) to sync the entire Primary Network (X-Chain, P-Chain, and C-Chain) and participate in its consensus, in addition to whatever resources are required for each Subnet they are validating.
Regulated entities that are prohibited from validating permissionless, smart contract-enabled blockchains (like the C-Chain) cannot launch a Subnet because they cannot opt-out of Primary Network Validation. This deployment blocker prevents a large cohort of Real World Asset (RWA) issuers from bringing unique, valuable tokens to the Avalanche Ecosystem (that could move between C-Chain \<-> Subnets using Avalanche Warp Messaging/Teleporter).
A widely validated Subnet that is not properly metered could destabilize the Primary Network if usage spikes unexpectedly. Underprovisioned Primary Network validators running such a Subnet may exit with an OOM exception, see degraded disk performance, or find it difficult to allocate CPU time to P/X/C-Chain validation. The inverse also holds for Subnets with the Primary Network (where some undefined behavior could bring a Subnet offline).
Although the fee paid to the Primary Network to operate a Subnet does not go up with the amount of activity on the Subnet, the fixed, upfront cost of setting up a Subnet validator on the Primary Network deters new projects that prefer smaller, even variable, costs until demand is observed. *Unlike L2s that pay some increasing fee (usually denominated in units per transaction byte) to an external chain for data availability and security as activity scales, Subnets provide their own security/data availability and the only cost operators must pay from processing more activity is the hardware cost of supporting additional load.*
Elastic Subnets, introduced in [Banff](https://medium.com/avalancheavax/banff-elastic-subnets-44042f41e34c), enabled Subnet creators to activate Proof-of-Stake validation and uptime-based rewards using their own token. However, this token is required to be an ANT (created on the X-Chain) and locked on the P-Chain. All staking rewards were distributed on the P-Chain with the reward curve being defined in the `TransformSubnetTx` and, once set, was unable to be modified.
With no Elastic Subnets live on Mainnet, it is clear that Permissionless Subnets as they stand today could be more desirable. There are many successful Permissioned Subnets in production but many Subnet creators have raised the above as points of concern. In summary, the Avalanche community could benefit from a more flexible and affordable mechanism to launch Permissionless Subnets.
### A Note on Nomenclature
Avalanche Subnets are subnetworks validated by a subset of the Primary Network validator set. The new network creation flow outlined in this ACP does not require any intersection between the new network's validator set and the Primary Network's validator set. Moreover, the new networks have greater functionality and sovereignty than Subnets. To distinguish between these two kinds of networks, the community has been referring to these new networks as *Avalanche Layer 1s*, or L1s for short.
All networks created through the old network creation flow will continue to be referred to as Avalanche Subnets.
## Specification
At a high-level, L1s can manage their validator sets externally to the P-Chain by setting the blockchain ID and address of their *validator manager*. The P-Chain will consume Warp messages that modify the L1's validator set. To confirm modification of the L1's validator set, the P-Chain will also produce Warp messages. L1 validators are not required to validate the Primary Network, and do not have the same 2000 $AVAX stake requirement that Subnet validators have. To maintain an active L1 validator, a continuous fee denominated in $AVAX is assessed. L1 validators are only required to sync the P-Chain (not X/C-Chain) in order to track validator set changes and support cross-L1 communication.
### P-Chain Warp Message Payloads
To enable management of an L1's validator set externally to the P-Chain, Warp message verification will be added to the [`PlatformVM`](https://github.com/ava-labs/avalanchego/tree/master/vms/platformvm). For a Warp message to be considered valid by the P-Chain, at least 67% of the `sourceChainID`'s weight must have participated in the aggregate BLS signature. This is equivalent to the threshold set for the C-Chain. A future ACP may be proposed to support modification of this threshold on a per-L1 basis.
The following Warp message payloads are introduced on the P-Chain:
* `SubnetToL1ConversionMessage`
* `RegisterL1ValidatorMessage`
* `L1ValidatorRegistrationMessage`
* `L1ValidatorWeightMessage`
The method of requesting signatures for these messages is left unspecified. A viable option for supporting this functionality is laid out in [ACP-118](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/118-warp-signature-request/README.md) with the `SignatureRequest` message.
All node IDs contained within the message specifications are represented as variable length arrays such that they can support new node IDs types should the P-Chain add support for them in the future.
The serialization of each of these messages is as follows.
#### `SubnetToL1ConversionMessage`
The P-Chain can produce a `SubnetToL1ConversionMessage` for consumers (i.e. validator managers) to be aware of the initial validator set.
The following serialization is defined as the `ValidatorData`:
| Field | Type | Size |
| -------------: | ---------: | -----------------------: |
| `nodeID` | `[]byte` | 4 + len(`nodeID`) bytes |
| `blsPublicKey` | `[48]byte` | 48 bytes |
| `weight` | `uint64` | 8 bytes |
| | | 60 + len(`nodeID`) bytes |
The following serialization is defined as the `ConversionData`:
| Field | Type | Size |
| ---------------: | ----------------: | ---------------------------------------------------------: |
| `codecID` | `uint16` | 2 bytes |
| `subnetID` | `[32]byte` | 32 bytes |
| `managerChainID` | `[32]byte` | 32 bytes |
| `managerAddress` | `[]byte` | 4 + len(`managerAddress`) bytes |
| `validators` | `[]ValidatorData` | 4 + sum(`validatorLengths`) bytes |
| | | 74 + len(`managerAddress`) + sum(`validatorLengths`) bytes |
* `codecID` is the codec version used to serialize the payload, and is hardcoded to `0x0000`
* `sum(validatorLengths)` is the sum of the lengths of `ValidatorData` serializations included in `validators`.
* `subnetID` identifies the Subnet that is being converted to an L1 (described further below).
* `managerChainID` and `managerAddress` identify the validator manager for the newly created L1. This is the (blockchain ID, address) tuple allowed to send Warp messages to modify the L1's validator set.
* `validators` are the initial continuous-fee-paying validators for the given L1.
The `SubnetToL1ConversionMessage` is specified as an `AddressedCall` with `sourceChainID` set to the P-Chain ID, the `sourceAddress` set to an empty byte array, and a payload of:
| Field | Type | Size |
| -------------: | ---------: | -------: |
| `codecID` | `uint16` | 2 bytes |
| `typeID` | `uint32` | 4 bytes |
| `conversionID` | `[32]byte` | 32 bytes |
| | | 38 bytes |
* `codecID` is the codec version used to serialize the payload, and is hardcoded to `0x0000`
* `typeID` is the payload type identifier and is `0x00000000` for this message
* `conversionID` is the SHA256 hash of the `ConversionData` from a given `ConvertSubnetToL1Tx`
#### `RegisterL1ValidatorMessage`
The P-Chain can consume a `RegisterL1ValidatorMessage` from validator managers through a `RegisterL1ValidatorTx` to register an addition to the L1's validator set.
The following is the serialization of a `PChainOwner`:
| Field | Type | Size |
| ----------: | -----------: | ---------------------------------: |
| `threshold` | `uint32` | 4 bytes |
| `addresses` | `[][20]byte` | 4 + len(`addresses`) \\\* 20 bytes |
| | | 8 + len(`addresses`) \\\* 20 bytes |
* `threshold` is the number of `addresses` that must provide a signature for the `PChainOwner` to authorize an action.
* Validation criteria:
* If `threshold` is `0`, `addresses` must be empty
* `threshold` \<= len(`addresses`)
* Entries of `addresses` must be unique and sorted in ascending order
The `RegisterL1ValidatorMessage` is specified as an `AddressedCall` with a payload of:
| Field | Type | Size |
| ----------------------: | ------------: | --------------------------------------------------------------------------: |
| `codecID` | `uint16` | 2 bytes |
| `typeID` | `uint32` | 4 bytes |
| `subnetID` | `[32]byte` | 32 bytes |
| `nodeID` | `[]byte` | 4 + len(`nodeID`) bytes |
| `blsPublicKey` | `[48]byte` | 48 bytes |
| `expiry` | `uint64` | 8 bytes |
| `remainingBalanceOwner` | `PChainOwner` | 8 + len(`addresses`) \\\* 20 bytes |
| `disableOwner` | `PChainOwner` | 8 + len(`addresses`) \\\* 20 bytes |
| `weight` | `uint64` | 8 bytes |
| | | 122 + len(`nodeID`) + (len(`addresses1`) + len(`addresses2`)) \\\* 20 bytes |
* `codecID` is the codec version used to serialize the payload, and is hardcoded to `0x0000`
* `typeID` is the payload type identifier and is `0x00000001` for this payload
* `subnetID`, `nodeID`, `weight`, and `blsPublicKey` are for the validator being added
* `expiry` is the time at which this message becomes invalid. As of a P-Chain timestamp `>= expiry`, this Avalanche Warp Message can no longer be used to add the `nodeID` to the validator set of `subnetID`
* `remainingBalanceOwner` is the P-Chain owner where leftover \$AVAX from the validator's Balance will be issued to when this validator it is removed from the validator set.
* `disableOwner` is the only P-Chain owner allowed to disable the validator using `DisableL1ValidatorTx`, specified below.
#### `L1ValidatorRegistrationMessage`
The P-Chain can produce an `L1ValidatorRegistrationMessage` for consumers to verify that a validation period has either begun or has been invalidated.
The `L1ValidatorRegistrationMessage` is specified as an `AddressedCall` with `sourceChainID` set to the P-Chain ID, the `sourceAddress` set to an empty byte array, and a payload of:
| Field | Type | Size |
| -------------: | ---------: | -------: |
| `codecID` | `uint16` | 2 bytes |
| `typeID` | `uint32` | 4 bytes |
| `validationID` | `[32]byte` | 32 bytes |
| `registered` | `bool` | 1 byte |
| | | 39 bytes |
* `codecID` is the codec version used to serialize the payload, and is hardcoded to `0x0000`
* `typeID` is the payload type identifier and is `0x00000002` for this message
* `validationID` identifies the validator for the message
* `registered` is a boolean representing the status of the `validationID`. If true, the `validationID` corresponds to a validator in the current validator set. If false, the `validationID` does not correspond to a validator in the current validator set, and never will in the future.
#### `L1ValidatorWeightMessage`
The P-Chain can consume an `L1ValidatorWeightMessage` through a `SetL1ValidatorWeightTx` to update the weight of an existing validator. The P-Chain can also produce an `L1ValidatorWeightMessage` for consumers to verify that the validator weight update has been effectuated.
The `L1ValidatorWeightMessage` is specified as an `AddressedCall` with the following payload. When sent from the P-Chain, the `sourceChainID` is set to the P-Chain ID, and the `sourceAddress` is set to an empty byte array.
| Field | Type | Size |
| -------------: | ---------: | -------: |
| `codecID` | `uint16` | 2 bytes |
| `typeID` | `uint32` | 4 bytes |
| `validationID` | `[32]byte` | 32 bytes |
| `nonce` | `uint64` | 8 bytes |
| `weight` | `uint64` | 8 bytes |
| | | 54 bytes |
* `codecID` is the codec version used to serialize the payload, and is hardcoded to `0x0000`
* `typeID` is the payload type identifier and is `0x00000003` for this message
* `validationID` identifies the validator for the message
* `nonce` is a strictly increasing number that denotes the latest validator weight update and provides replay protection for this transaction
* `weight` is the new `weight` of the validator
### New P-Chain Transaction Types
Both before and after this ACP, to create a Subnet, a `CreateSubnetTx` must be issued on the P-Chain. This transaction includes an `Owner` field which defines the key that today can be used to authorize any validator set additions (`AddSubnetValidatorTx`) or removals (`RemoveSubnetValidatorTx`).
To be considered a permissionless network, or Avalanche Layer 1:
* This `Owner` key must no longer have the ability to modify the validator set.
* New transaction types must support modification of the validator set via Warp messages.
The following new transaction types are introduced on the P-Chain to support this functionality:
* `ConvertSubnetToL1Tx`
* `RegisterL1ValidatorTx`
* `SetL1ValidatorWeightTx`
* `DisableL1ValidatorTx`
* `IncreaseL1ValidatorBalanceTx`
#### `ConvertSubnetToL1Tx`
To convert a Subnet into an L1, a `ConvertSubnetToL1Tx` must be issued to set the `(chainID, address)` pair that will manage the L1's validator set. The `Owner` key defined in `CreateSubnetTx` must provide a signature to authorize this conversion.
The `ConvertSubnetToL1Tx` specification is:
```go
type PChainOwner struct {
// The threshold number of `Addresses` that must provide a signature in order for
// the `PChainOwner` to be considered valid.
Threshold uint32 `json:"threshold"`
// The 20-byte addresses that are allowed to sign to authenticate a `PChainOwner`.
// Note: It is required for:
// - len(Addresses) == 0 if `Threshold` is 0.
// - len(Addresses) >= `Threshold`
// - The values in Addresses to be sorted in ascending order.
Addresses []ids.ShortID `json:"addresses"`
}
type L1Validator struct {
// NodeID of this validator
NodeID []byte `json:"nodeID"`
// Weight of this validator used when sampling
Weight uint64 `json:"weight"`
// Initial balance for this validator
Balance uint64 `json:"balance"`
// [Signer] is the BLS public key and proof-of-possession for this validator.
// Note: We do not enforce that the BLS key is unique across all validators.
// This means that validators can share a key if they so choose.
// However, a NodeID + L1 does uniquely map to a BLS key
Signer signer.ProofOfPossession `json:"signer"`
// Leftover $AVAX from the [Balance] will be issued to this
// owner once it is removed from the validator set.
RemainingBalanceOwner PChainOwner `json:"remainingBalanceOwner"`
// The only owner allowed to disable this validator on the P-Chain.
DisableOwner PChainOwner `json:"disableOwner"`
}
type ConvertSubnetToL1Tx struct {
// Metadata, inputs and outputs
BaseTx
// ID of the Subnet to transform
// Restrictions:
// - Must not be the Primary Network ID
Subnet ids.ID `json:"subnetID"`
// BlockchainID where the validator manager lives
ChainID ids.ID `json:"chainID"`
// Address of the validator manager
Address []byte `json:"address"`
// Initial continuous-fee-paying validators for the L1
Validators []L1Validator `json:"validators"`
// Authorizes this conversion
SubnetAuth verify.Verifiable `json:"subnetAuthorization"`
}
```
After this transaction is accepted, `CreateChainTx` and `AddSubnetValidatorTx` are disabled on the Subnet. The only action that the `Owner` key is able to take is removing Subnet validators with `RemoveSubnetValidatorTx` that had been added using `AddSubnetValidatorTx`. Unless removed by the `Owner` key, any Subnet validators added previously with an `AddSubnetValidatorTx` will continue to validate the Subnet until their [`End`](https://github.com/ava-labs/avalanchego/blob/a1721541754f8ee23502b456af86fea8c766352a/vms/platformvm/txs/validator.go#L27) time is reached. Once all Subnet validators added with `AddSubnetValidatorTx` are no longer in the validator set, the `Owner` key is powerless. `RegisterL1ValidatorTx` and `SetL1ValidatorWeightTx` must be used to manage the L1's validator set.
The `validationID` for validators added through `ConvertSubnetToL1Tx` is defined as the SHA256 hash of the 36 bytes resulting from concatenating the 32 byte `subnetID` with the 4 byte `validatorIndex` (index in the `Validators` array within the transaction).
Once this transaction is accepted, the P-Chain must be willing sign a `SubnetToL1ConversionMessage` with a `conversionID` corresponding to `ConversionData` populated with the values from this transaction.
#### `RegisterL1ValidatorTx`
After a `ConvertSubnetToL1Tx` has been accepted, new validators can only be added by using a `RegisterL1ValidatorTx`. The specification of this transaction is:
```go
type RegisterL1ValidatorTx struct {
// Metadata, inputs and outputs
BaseTx
// Balance <= sum($AVAX inputs) - sum($AVAX outputs) - TxFee.
Balance uint64 `json:"balance"`
// [Signer] is a BLS signature proving ownership of the BLS public key specified
// below in `Message` for this validator.
// Note: We do not enforce that the BLS key is unique across all validators.
// This means that validators can share a key if they so choose.
// However, a NodeID + L1 does uniquely map to a BLS key
Signer [96]byte `json:"signer"`
// A RegisterL1ValidatorMessage payload
Message warp.Message `json:"message"`
}
```
The `validationID` of validators added via `RegisterL1ValidatorTx` is defined as the SHA256 hash of the `Payload` of the `AddressedCall` in `Message`.
When a `RegisterL1ValidatorTx` is accepted on the P-Chain, the validator is added to the L1's validator set. A `minNonce` field corresponding to the `validationID` will be stored on addition to the validator set (initially set to `0`). This field will be used when validating the `SetL1ValidatorWeightTx` defined below.
This `validationID` will be used for replay protection. Used `validationID`s will be stored on the P-Chain. If a `RegisterL1ValidatorTx`'s `validationID` has already been used, the transaction will be considered invalid. To prevent storing an unbounded number of `validationID`s, the `expiry` of the `RegisterL1ValidatorMessage` is required to be no more than 24 hours in the future of the time the transaction is issued on the P-Chain. Any `validationIDs` corresponding to an expired timestamp can be flushed from the P-Chain's state.
L1s are responsible for defining the procedure on how to retrieve the above information from prospective validators.
An EVM-compatible L1 may choose to implement this step like so:
* Use the number of tokens the user has staked into a smart contract on the L1 to determine the weight of their validator
* Require the user to submit an on-chain transaction with their validator information
* Generate the Warp message
For a `RegisterL1ValidatorTx` to be valid, `Signer` must be a valid proof-of-possession of the `blsPublicKey` defined in the `RegisterL1ValidatorMessage` contained in the transaction.
After a `RegisterL1ValidatorTx` is accepted, the P-Chain must be willing to sign an `L1ValidatorRegistrationMessage` for the given `validationID` with `registered` set to `true`. This remains the case until the time at which the validator is removed from the validator set using a `SetL1ValidatorWeightTx`, as described below.
When it is known that a given `validationID` *is not and never will be* registered, the P-Chain must be willing to sign an `L1ValidatorRegistrationMessage` for the `validationID` with `registered` set to `false`. This could be the case if the `expiry` time of the message has passed prior to the message being delivered in a `RegisterL1ValidatorTx`, or if the validator was successfully registered and then later removed. This enables the P-Chain to prove to validator managers that a validator has been removed or never added. The P-Chain must refuse to sign any `L1ValidatorRegistrationMessage` where the `validationID` does not correspond to an active validator and the `expiry` is in the future.
#### `SetL1ValidatorWeightTx`
`SetL1ValidatorWeightTx` is used to modify the voting weight of a validator. The specification of this transaction is:
```go
type SetL1ValidatorWeightTx struct {
// Metadata, inputs and outputs
BaseTx
// An L1ValidatorWeightMessage payload
Message warp.Message `json:"message"`
}
```
Applications of this transaction could include:
* Increase the voting weight of a validator if a delegation is made on the L1
* Increase the voting weight of a validator if the stake amount is increased (by staking rewards for example)
* Decrease the voting weight of a misbehaving validator
* Remove an inactive validator
The validation criteria for `L1ValidatorWeightMessage` is:
* `nonce >= minNonce`. Note that `nonce` is not required to be incremented by `1` with each successive validator weight update.
* When `minNonce == MaxUint64`, `nonce` must be `MaxUint64` and `weight` must be `0`. This prevents L1s from being unable to remove `nodeID` in a subsequent transaction.
* If `weight == 0`, the validator being removed must not be the last one in the set. If all validators are removed, there are no valid Warp messages that can be produced to register new validators through `RegisterL1ValidatorMessage`. With no validators, block production will halt and the L1 is unrecoverable. This validation criteria serves as a guardrail against this situation. A future ACP can remove this guardrail as users get more familiar with the new L1 mechanics and tooling matures to fork an L1.
When `weight != 0`, the weight of the validator is updated to `weight` and `minNonce` is updated to `nonce + 1`.
When `weight == 0`, the validator is removed from the validator set. All state related to the validator, including the `minNonce` and `validationID`, are reaped from the P-Chain state. Tracking these post-removal is not required since `validationID` can never be re-initialized due to the replay protection provided by `expiry` in `RegisterL1ValidatorTx`. Any unspent \$AVAX in the validator's `Balance` will be issued in a single UTXO to the `RemainingBalanceOwner` for this validator. Recall that `RemainingBalanceOwner` is specified when the validator is first added to the L1's validator set (in either `ConvertSubnetToL1Tx` or `RegisterL1ValidatorTx`).
Note: There is no explicit `EndTime` for L1 validators added in a `ConvertSubnetToL1Tx` or `RegisterL1ValidatorTx`. The only time when L1 validators are removed from the L1's validator set is through this transaction when `weight == 0`.
#### `DisableL1ValidatorTx`
L1 validators can use `DisableL1ValidatorTx` to mark their validator as inactive. The specification of this transaction is:
```go
type DisableL1ValidatorTx struct {
// Metadata, inputs and outputs
BaseTx
// ID corresponding to the validator
ValidationID ids.ID `json:"validationID"`
// Authorizes this validator to be disabled
DisableAuth verify.Verifiable `json:"disableAuthorization"`
}
```
The `DisableOwner` specified for this validator must sign the transaction. Any unspent \$AVAX in the validator's `Balance` will be issued in a single UTXO to the `RemainingBalanceOwner` for this validator. Recall that both `DisableOwner` and `RemainingBalanceOwner` are specified when the validator is first added to the L1's validator set (in either `ConvertSubnetToL1Tx` or `RegisterL1ValidatorTx`).
For full removal from an L1's validator set, a `SetL1ValidatorWeightTx` must be issued with weight `0`. To do so, a Warp message is required from the L1's validator manager. However, to support the ability to claim the unspent `Balance` for a validator without authorization is critical for failed L1s.
Note that this does not modify an L1's total staking weight. This transaction marks the validator as inactive, but does not remove it from the L1's validator set. Inactive validators can re-activate at any time by increasing their balance with an `IncreaseL1ValidatorBalanceTx`.
L1 creators should be aware that there is no notion of `MinStakeDuration` that is enforced by the P-Chain. It is expected that L1s who choose to enforce a `MinStakeDuration` will lock the validator's Stake for the L1's desired `MinStakeDuration`.
#### `IncreaseL1ValidatorBalanceTx`
L1 validators are required to maintain a non-zero balance used to pay the continuous fee on the P-Chain in order to be considered active. The `IncreaseL1ValidatorBalanceTx` can be used by anybody to add additional \$AVAX to the `Balance` to a validator. The specification of this transaction is:
```go
type IncreaseL1ValidatorBalanceTx struct {
// Metadata, inputs and outputs
BaseTx
// ID corresponding to the validator
ValidationID ids.ID `json:"validationID"`
// Balance <= sum($AVAX inputs) - sum($AVAX outputs) - TxFee
Balance uint64 `json:"balance"`
}
```
If the validator corresponding to `ValidationID` is currently inactive (`Balance` was exhausted or `DisableL1ValidatorTx` was issued), this transaction will move them back to the active validator set.
Note: The \$AVAX added to `Balance` can be claimed at any time by the validator using `DisableL1ValidatorTx`.
### Bootstrapping L1 Nodes
Bootstrapping a node/validator is the process of securely recreating the latest state of the blockchain locally. At the end of this process, the local state of a node/validator must be in sync with the local state of other virtuous nodes/validators. The node/validator can then verify new incoming transactions and reach consensus with other nodes/validators.
To bootstrap a node/validator, a few critical questions must be answered: How does one discover peers in the network? How does one determine that a discovered peer is honestly participating in the network?
For standalone networks like the Avalanche Primary Network, this is done by connecting to a hardcoded [set](https://github.com/ava-labs/avalanchego/blob/master/genesis/bootstrappers.json) of trusted bootstrappers to then discover new peers. Ethereum calls their set [bootnodes](https://ethereum.org/developers/docs/nodes-and-clients/bootnodes).
Since L1 validators are not required to be Primary Network validators, a list of validator IPs to connect to (the functional bootstrappers of the L1) cannot be provided by simply connecting to the Primary Network validators. However, the Primary Network can enable nodes tracking an L1 to seamlessly connect to the validators by tracking and gossiping L1 validator IPs. L1s will not need to operate and maintain a set of bootstrappers and can rely on the Primary Network for peer discovery.
### Sidebar: L1 Sovereignty
After this ACP is activated, the P-Chain will no longer support staking of any assets other than $AVAX for the Primary Network. The P-Chain will not support the distribution of staking rewards for L1s. All staking-related operations for L1 validation must be managed by the L1's validator manager. The P-Chain simply requires a continuous fee per validator. If an L1 would like to manage their validator's balances on the P-Chain, it can cover the cost for all L1 validators by posting the $AVAX balance on the P-Chain. L1s can implement any mechanism they want to pay the continuous fee charged by the P-Chain for its participants.
The L1 has full ownership over its validator set, not the P-Chain. There are no restrictions on what requirements an L1 can have for validators to join. Any stake that is required to join the L1's validator set is not locked on the P-Chain. If a validator is removed from the L1's validator set via a `SetL1ValidatorWeightTx` with weight `0`, the stake will continue to be locked outside of the P-Chain. How each L1 handles stake associated with the validator is entirely left up to the L1 and can be treated independently to what happens on the P-Chain.
The relationship between the P-Chain and L1s provides a dynamic where L1s can use the P-Chain as an impartial judge to modify parameters (in addition to its existing role of helping to validate incoming Avalanche Warp Messages). If a validator is misbehaving, the L1 validators can collectively generate a BLS multisig to reduce the voting weight of a misbehaving validator. This operation is fully secured by the Avalanche Primary Network (225M $AVAX or $8.325B at the time of writing).
Follow-up ACPs could extend the P-Chain \<-> L1 relationship to include parametrization of the 67% threshold to enable L1s to choose a different threshold based on their security model (e.g. a simple majority of 51%).
### Continuous Fee Mechanism
Every additional validator on the P-Chain adds persistent load to the Avalanche Network. When a validator transaction is issued on the P-Chain, it is charged for the computational cost of the transaction itself but is not charged for the cost of an active validator over the time they are validating on the network (which may be indefinitely). This is a common problem in blockchains, spawning many state rent proposals in the broader blockchain space to address it. The following fee mechanism takes advantage of the fact that each L1 validator uses the same amount of computation and charges each L1 validator the dynamic base fee for every discrete unit of time it is active.
To charge each L1 validator, the notion of a `Balance` is introduced. The `Balance` of a validator will be continuously charged during the time they are active to cover the cost of storing the associated validator properties (BLS key, weight, nonce) in memory and to track IPs (in addition to other services provided by the Primary Network). This `Balance` is initialized with the `RegisterL1ValidatorTx` that added them to the active validator set. `Balance` can be increased at any time using the `IncreaseL1ValidatorBalanceTx`. When this `Balance` reaches `0`, the validator will be considered "inactive" and will no longer participate in validating the L1. Inactive validators can be moved back to the active validator set at any time using the same `IncreaseL1ValidatorBalanceTx`. Once a validator is considered inactive, the P-Chain will remove these properties from memory and only retain them on disk. All messages from that validator will be considered invalid until it is revived using the `IncreaseL1ValidatorBalanceTx`. L1s can reduce the amount of inactive weight by removing inactive validators with the `SetL1ValidatorWeightTx` (`Weight` = 0).
Since each L1 validator is charged the same amount at each point in time, tracking the fees for the entire validator set is straight-forward. The accumulated dynamic base fee for the entire network is tracked in a single uint. This accumulated value should be equal to the fee charged if a validator was active from the time the accumulator was instantiated. The validator set is maintained in a priority queue. A pseudocode implementation of the continuous fee mechanism is provided below.
```python
# Pseudocode
class ValidatorQueue:
def __init__(self, fee_getter):
self.acc = 0
self.queue = PriorityQueue()
self.fee_getter = fee_getter
# At each time period, increment the accumulator and
# pop all validators from the top of the queue that
# ran out of funds.
# Note: The amount of work done in a single block
# should be bounded to prevent a large number of
# validator operations from happening at the same
# time.
def time_elapse(self, t):
self.acc = self.acc + self.fee_getter(t)
while True:
vdr = self.queue.peek()
if vdr.balance < self.acc:
self.queue.pop()
continue
return
# Validator was added
def validator_enter(self, vdr):
vdr.balance = vdr.balance + self.acc
self.queue.add(vdr)
# Validator was removed
def validator_remove(self, vdrNodeID):
vdr = find_and_remove(self.queue, vdrNodeID)
vdr.balance = vdr.balance - self.acc
vdr.refund() # Refund [vdr.balance] to [RemainingBalanceOwner]
self.queue.remove()
# Validator's balance was topped up
def validator_increase(self, vdrNodeID, balance):
vdr = find_and_remove(self.queue, vdrNodeID)
vdr.balance = vdr.balance + balance
self.queue.add(vdr)
```
#### Fee Algorithm
[ACP-103](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/103-dynamic-fees/README.md) proposes a dynamic fee mechanism for transactions on the P-Chain. This mechanism is repurposed with minor modifications for the active L1 validator continuous fee.
At activation, the number of excess active L1 validators $x$ is set to `0`.
The fee rate per second for an active L1 validator is:
$M \cdot \exp\left(\frac{x}{K}\right)$
Where:
* $M$ is the minimum price for an active L1 validator
* $\exp\left(x\right)$ is an approximation of $e^x$ following the EIP-4844 specification
```python
# Approximates factor * e ** (numerator / denominator) using Taylor expansion
def fake_exponential(factor: int, numerator: int, denominator: int) -> int:
i = 1
output = 0
numerator_accum = factor * denominator
while numerator_accum > 0:
output += numerator_accum
numerator_accum = (numerator_accum * numerator) // (denominator * i)
i += 1
return output // denominator
```
* $K$ is a constant to control the rate of change for the L1 validator price
After every second, $x$ will be updated:
$x = \max(x + (V - T), 0)$
Where:
* $V$ is the number of active L1 validators
* $T$ is the target number of active L1 validators
Whenever $x$ increases by $K$, the price per active L1 validator increases by a factor of `~2.7`. If the price per active L1 validator gets too expensive, some active L1 validators will exit the active validator set, decreasing $x$, dropping the price. The price per active L1 validator constantly adjusts to make sure that, on average, the P-Chain has no more than $T$ active L1 validators.
#### Block Processing
Before processing the transactions inside a block, all validators that no longer have a sufficient (non-zero) balance are deactivated.
After processing the transactions inside a block, all validators that do not have a sufficient balance for the next second are deactivated.
##### Block Timestamp Validity Change
To ensure that validators are charged accurately, blocks are only considered valid if advancing the chain times would not cause a validator to have a negative balance.
This upholds the expectation that the number of L1 validators remains constant between blocks.
The block building protocol is modified to account for this change by first checking if the wall clock time removes any validator due to a lack of funds. If the wall clock time does not remove any L1 validators, the wall clock time is used to build the block. If it does, the time at which the first validator gets removed is used.
##### Fee Calculation
The total validator fee assessed in $\Delta t$ is:
```python
# Calculate the fee to charge over Δt
def cost_over_time(V:int, T:int, x:int, Δt: int) -> int:
cost = 0
for _ in range(Δt):
x = max(x + V - T, 0)
cost += fake_exponential(M, x, K)
return cost
```
#### Parameters
The parameters at activation are:
| Parameter | Definition | Value |
| --------- | ------------------------------------------- | ---------------- |
| $T$ | target number of validators | 10\_000 |
| $C$ | capacity number of validators | 20\_000 |
| $M$ | minimum fee rate | 512 nAVAX/s |
| $K$ | constant to control the rate of fee changes | 1\_246\_488\_515 |
An $M$ of 512 nAVAX/s equates to \~1.33 AVAX/month to run an L1 validator, so long as the total number of continuous-fee-paying L1 validators stays at or below $T$.
$K$ was chosen to set the maximum fee doubling rate to \~24 hours. This is in the extreme case that the network has $C$ validators for prolonged periods of time; if the network has $T$+1 validators for example, the fee rate would double every \~27 years.
A future ACP can adjust the parameters to increase $T$, reduce $M$, and/or modify $K$.
#### User Experience
L1 validators are continuously charged a fee, albeit a small one. This poses a challenge for L1 validators: How do they maintain the balance over time?
Node clients should expose an API to track how much balance is remaining in the validator's account. This will provide a way for L1 validators to track how quickly it is going down and top-up when needed. A nice byproduct of the above design is the balance in the validator's account is claimable. This means users can top-up as much \$AVAX as they want and rest-assured knowing they can always retrieve it if there is an excessive amount.
The expectation is that most users will not interact with node clients or track when or how much they need to top-up their validator account. Wallet providers will abstract away most of this process. For users who desire more convenience, L1-as-a-Service providers will abstract away all of this process.
## Backwards Compatibility
This new design for Subnets proposes a large rework to all L1-related mechanics. Rollout should be done on a going-forward basis to not cause any service disruption for live Subnets. All current Subnet validators will be able to continue validating both the Primary Network and whatever Subnets they are validating.
Any state execution changes must be coordinated through a mandatory upgrade. Implementors must take care to continue to verify the existing ruleset until the upgrade is activated. After activation, nodes should verify the new ruleset. Implementors must take care to only verify the presence of 2000 \$AVAX prior to activation.
### Deactivated Transactions
* P-Chain
* `TransformSubnetTx`
After this ACP is activated, Elastic Subnets will be disabled. `TransformSubnetTx` will not be accepted post-activation. As there are no Mainnet Elastic Subnets, there should be no production impact with this deactivation.
### New Transactions
* P-Chain
* `ConvertSubnetToL1Tx`
* `RegisterL1ValidatorTx`
* `SetL1ValidatorWeightTx`
* `DisableL1ValidatorTx`
* `IncreaseL1ValidatorBalanceTx`
## Reference Implementation
ACP-77 was implemented and will be merged into AvalancheGo behind the `Etna` upgrade flag. The full body of work can be found tagged with the `acp77` label [here](https://github.com/ava-labs/avalanchego/issues?q=sort%3Aupdated-desc+label%3Aacp77).
Since Etna is not yet activated, all new transactions introduced in ACP-77 will be rejected by AvalancheGo. If any modifications are made to ACP-77 as part of the ACP process, the implementation must be updated prior to activation.
## Security Considerations
This ACP introduces Avalanche Layer 1s, a new network type that costs significantly less than Avalanche Subnets. This can lead to a large increase in the number of networks and, by extension, the number of validators. Each additional validator adds consistent RAM usage to the P-Chain. However, this should be appropriately metered by the continuous fee mechanism outlined above.
With the sovereignty L1s have from the P-Chain, L1 staking tokens are not locked on the P-Chain. This poses a security consideration for L1 validators: Malicious chains can choose to remove validators at will and take any funds that the validator has locked on the L1. The P-Chain only provides the guarantee that L1 validators can retrieve the remaining \$AVAX Balance for their validator via a `DisableL1ValidatorTx`. Any assets on the L1 is entirely under the purview of the L1. The onus is on L1 validators to vet the L1's security for any assets transferred onto the L1.
With a long window of expiry (24 hours) for the Warp message in `RegisterL1ValidatorTx`, spam of validator registration could lead to high memory pressure on the P-Chain. A future ACP can reduce the window of expiry if 24 hours proves to be a problem.
NodeIDs can be added to an L1's validator set involuntarily. However, it is important to note that any stake/rewards are *not* at risk. For a node operator who was added to a validator set involuntarily, they would only need to generate a new NodeID via key rotation as there is no lock-up of any stake to create a NodeID. This is an explicit tradeoff for easier on-boarding of NodeIDs. This mirrors the Primary Network validators guarantee of no stake/rewards at risk.
The continuous fee mechanism outlined above does not apply to inactive L1 validators since they are not stored in memory. However, inactive L1 validators are persisted on disk which can lead to persistent P-Chain state growth. A future ACP can introduce a mechanism to decrease the rate of P-Chain state growth or provide a state expiry path to reduce the amount of P-Chain state.
## Acknowledgements
Special thanks to [@StephenButtolph](https://github.com/StephenButtolph), [@aaronbuchwald](https://github.com/aaronbuchwald), and [@patrick-ogrady](https://github.com/patrick-ogrady) for their feedback on these ideas. Thank you to the broader Ava Labs Platform Engineering Group for their feedback on this ACP prior to publication.
## Copyright
Copyright and related rights waived via [CC0](https://creativecommons.org/publicdomain/zero/1.0/).
# ACP-83: Dynamic Multidimensional Fees
URL: /docs/acps/83-dynamic-multidimensional-fees
Details for Avalanche Community Proposal 83: Dynamic Multidimensional Fees
| ACP | 83 |
| :---------------- | :------------------------------------------------------------------------------------------------ |
| **Title** | Dynamic multidimensional fees for P-chain and X-chain |
| **Author(s)** | Alberto Benegiamo ([@abi87](https://github.com/abi87)) |
| **Status** | Stale |
| **Track** | Standards |
| **Superseded-By** | [ACP-103](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/103-dynamic-fees/README.md) |
## Abstract
Introduce a dynamic and multidimensional fees scheme for the P-chain and X-chain.
Dynamic fees helps to preserve the stability of the chain as it provides a feedback mechanism that increases the cost of resources when the network operates above its target utilization.
Multidimensional fees ensures that high demand for orthogonal resources does not drive up the price of underutilized resources. For example, networks provide and consume orthogonal resources including, but not limited to, bandwidth, chain state, read/write throughput, and CPU. By independently metering each resource, they can be granularly priced and stay closer to optimal resource utilization.
## Motivation
The P-Chain and X-Chain currently have fixed fees and in some cases those fees are fixed to zero.
This makes transaction issuance predictable, but does not provide feedback mechanism to preserve chain stability under high load. In contrast, the C-Chain, which has the highest and most regular load among the chains on the Primary Network, already supports dynamic fees. This ACP proposes to introduce a similar dynamic fee mechanism for the P-Chain and X-Chain to further improve the Primary Network's stability and resilience under load.
However, unlike the C-Chain, we propose a multidimensional fee scheme with an exponential update rule for each fee dimension. The [HyperSDK](https://github.com/ava-labs/hypersdk) already utilizes a multidimensional fee scheme with optional priority fees and its efficiency is backed by [academic research](https://arxiv.org/abs/2208.07919).
Finally, we split the fee into two parts: a `base fee` and a `priority fee`. The `base fee` is calculated by the network each block to accurately price each resource at a given point in time. Whatever amount greater than the base fee is burnt is treated as the `priority fee` to prioritize faster transaction inclusion.
## Specification
We introduce the multidimensional scheme first and then how to apply the dynamic fee update rule for each fee dimension. Finally we list the new block verification rules, valid once the new fee scheme activates.
### Multidimensional scheme components
We define four fee dimensions, `Bandwidth`, `Reads`, `Writes`, `Compute`, to describe transactions complexity. In more details:
* `Bandwidth` measures the transaction size in bytes, as encoded by the AvalancheGo codec. Byte length is a proxy for the network resources needed to disseminate the transaction.
* `Reads` measures the number of DB reads needed to verify the transactions. DB reads include UTXOs reads and any other state quantity relevant for the specific transaction.
* `Writes` measures the number of DB writes following the transaction verification. DB writes include UTXOs generated as outputs of the transactions and any other state quantity relevant for the specific transaction.
* `Compute` measures the number of signatures to be verified, including UTXOs ones and those related to authorization of specific operations.
For each fee dimension $i$, we define:
* *fee rate* $r_i$ as the price, denominated in AVAX, to be paid for a transaction with complexity $u_i$ along the fee dimension $i$.
* *base fee* as the minimal fee needed to accept a transaction. Base fee is given be the formula
$base \ fee = \sum_{i=0}^3 r_i \times u_i$
* *priority fee* as an optional fee paid on top of the base fee to speed up the transaction inclusion in a block.
### Dynamic scheme components
Fee rates are updated in time, to allow a fee increase when network is getting congested. Each new block is a potential source of congestion, as its transactions carry complexity that each validator must process to verify and eventually accept the block. The more complexity carries a block, and the more rapidly blocks are produced, the higher the congestion.
We seek a scheme that rapidly increases the fees when blocks complexity goes above a defined threshold and that equally rapidly decreases the fees once complexity goes down (because blocks carry less/simpler transactions, or because they are produced more slowly). We define the desired threshold as a *target complexity rate* $T$: we would want to process every second a block whose complexity is $T$. Any complexity more than that causes some congestion that we want to penalize via fees.
In order to update fees rates we track, per each block and each fee dimension, a parameter called cumulative excess complexity. Fee rates applied to a block will be defined in terms of cumulative excess complexity as we show in the following.
Suppose that a block $B_t$ is the current chain tip. $B_t$ has the following features:
* $t$ is its timestamp.
* $\Delta C_t$ is the cumulative excess complexity along fee dimension $i$.
Say a new block $B_{t + \Delta T}$ is built on top of $B$, with the following features:
* $t + \Delta T$ is its timestamp
* $C_{t + \Delta T}$ is its complexity along fee dimension $i$.
Then the fee rate $r_{t + \Delta T}$ applied for the block $B_{t + \Delta T}$ along dimension $i$ will be:
$r_{t + \Delta T} = r^{min} \times e^{\frac{max(0, \Delta C_t - T \times \Delta T)}{Denom}}$
where
* $r^{min}$ is the minimal fee rate along fee dimension $i$
* $T$ is the target complexity rate along fee dimension $i$
* $Denom$ is a normalization constant for the fee dimension $i$
Moreover, once the block $B_{t + \Delta T}$ is accepted, the cumulative excess complexity is updated as follows:
$\Delta C_{t + \Delta T} = max\large(0, \Delta C_{t} - T \times \Delta T\large) + C_{t + \Delta T}$
The fee rate update formula guarantees that fee rates increase if incoming blocks are complex (large $C_{t + \Delta T}$) and if blocks are emitted rapidly (small $\Delta T$). Symmetrically, fee rates decrease to the minimum if incoming blocks are less complex and if blocks are produced less frequently.\
The update formula has a few paramenters to be tuned, independently, for each fee dimension. We defer discussion about tuning to the [implementation section](#tuning-the-update-formula).
## Block verification rules
Upon activation of the dynamic multidimensional fees scheme we modify block processing as follows:
* **Bound block complexity**. For each fee dimension $i$, we define a *maximal block complexity* $Max$. A block is only valid if the block complexity $C$ is less than the maximum block complexity: $C \leq Max$.
* **Verify transaction fee**. When verifying each transaction in a block, we confirm that it can cover its own base fee. Note that both base fee and optional priority fees are burned.
## User Experience
### How will the wallets estimate the fees?
AvalancheGo nodes will provide new APIs exposing the current and expected fee rates, as they are likely to change block by block. Wallets can then use the fees rates to select UTXOs to pay the transaction fees. Moreover, the AvalancheGo implementation proposed above offers a `fees.Calculator` struct that can be reused by wallets and downstream projects to evaluate calculate fees.
### How will wallets be able to re-issue Txs at a higher fee?
Wallets should be able to simply re-issue the transaction since current AvalancheGo implementation drops mempool transactions whose fee rate is lower than current one. More specifically, a transaction may be valid the moment it enters the mempool and it won’t be re-verified as long as it stays in there. However, as soon as the transaction is selected to be included in the next block, it is re-verified against the latest preferred tip. If fees are not enough by this time, the transaction is dropped and the wallet can simply re-issue it at a higher fee, or wait for the fee rate to go down. Note that priority fees offer some buffer space against an increase in the fee rate. A transaction paying just the base fee will be evicted from the mempool in the face of a fee rate increase, while a transaction paying some extra priority fee may have enough buffer room to stay valid after some amount of fee increase.
### How does priority fees guarantee a faster block inclusion?
AvalancheGo mempool will be restructured to order transactions by priority fees. Transactions paying priority fees will be selected for block inclusion first, without violating any spend dependency.
## Backwards Compatibility
Modifying the fee scheme for P-Chain and X-Chain requires a mandatory upgrade for activation. Moreover, wallets must be modified to properly handle the new fee scheme once activated.
## Reference Implementation
The implementation is split across multiple PRs:
* P-Chain work is tracked in this issue: [https://github.com/ava-labs/avalanchego/issues/2707](https://github.com/ava-labs/avalanchego/issues/2707)
* X-Chain work is tracked in this issue: [https://github.com/ava-labs/avalanchego/issues/2708](https://github.com/ava-labs/avalanchego/issues/2708)
A very important implementation step is tuning the update formula parameters for each chain and each fee dimension. We show here the principles we followed for tuning and a simulation based on historical data.
### Tuning the update formula
The basic idea is to measure the complexity of blocks already accepted and derive the parameters from it. You can find the historical data in [this repo](https://github.com/abi87/complexities).\
To simplify the exposition I am purposefully ignoring chain specifics (like P-chain proposal blocks). We can account for chain specifics while processing the historical data. Here are the principles:
* **Target block complexity rate $T$**: calculate the distribution of block complexity and pick a high enough quantile.
* **Max block complexity $Max$**: this is probably the trickiest parameter to set.
Historically we had [pretty big transactions](https://subnets.avax.network/p-chain/tx/27pjHPRCvd3zaoQUYMesqtkVfZ188uP93zetNSqk3kSH1WjED1) (more than $1.000$ referenced utxos). Setting a max block complexity so high that these big transactions are allowed is akin to setting no complexity cap.
On the other side, we still want to allow, even encourage, UTXO consolidation, so we may want to allow transactions [like this](https://subnets.avax.network/p-chain/tx/2LxyHzbi2AGJ4GAcHXth6pj5DwVLWeVmog2SAfh4WrqSBdENhV).
A principled way to set max block complexity may be the following:
* calculate the target block complexity rate (see previous point)
* calculate the median time elapsed among consecutive blocks
* The product of these two quantities should gives us something like a target block complexity.
* Set the max block complexity to say $\times 50$ the target value.
* **Normalization coefficient $Denom$**: I suggest we size it as follows:
* Find the largest historical peak, i.e. the sequence of consecutive blocks which contained the most complexity in the shortest period of time
* Tune $Denom$ so that it would cause a $\times 10000$ increase in the fee rate for such a peak. This increase would push fees from the milliAVAX we normally pay under stable network condition up to tens of AVAX.
* **Minimal fee rates $r^{min}$**: we could size them so that transactions fees do not change very much with respect to the currently fixed values.
We simulate below how the update formula would behave on an peak period from Avalanche mainnet.
***
## Specification
Note: The following is pseudocode.
### P2P
#### Aggregation
```diff
+ message GetAcceptanceSignatureRequest {
+ bytes chain_id = 1;
+ uint32 request_id = 2;
+ bytes block_id = 3;
+ }
```
The `GetAcceptanceSignatureRequest` message is sent to a peer to request their signature for a given block id.
```diff
+ message GetAcceptanceSignatureResponse {
+ bytes chain_id = 1;
+ uint32 request_id = 2;
+ bytes bls_signature = 3;
+ }
```
`GetAcceptanceSignatureResponse` is sent to a peer as a response for `GetAcceptanceSignatureRequest`. `bls_signature` is the peer’s signature using their registered primary network BLS staking key over the requested `block_id`. An empty `bls_signature` field indicates that the block was not accepted yet.
## Security Considerations
Nodes that bootstrap using state sync may not have the entire history of the
P-Chain and therefore will not be able to provide the entire history for a block
that is referenced in a block that they propose. This would be needed to unblock a node that is attempting to fast-forward their P-Chain, as they require the entire ancestry between their current accepted tip and the block they are attempting to forward to. It is assumed that nodes will have some minimum amount of recent state so that the requester can eventually be unblocked by retrying, as only one node with the requested ancestry is required to unblock the requester.
An alternative is to make a churn assumption and validate the proposed block's proof with a stale validator set to avoid complexity, but this introduces more security concerns.
## Copyright
Copyright and related rights waived via [CC0](https://creativecommons.org/publicdomain/zero/1.0/).
# ACP-77: Reinventing Subnets
URL: /docs/acps/77-reinventing-subnets
Details for Avalanche Community Proposal 77: Reinventing Subnets
| ACP | 77 |
| :------------ | :-------------------------------------------------------------------------------------------------------- |
| **Title** | Reinventing Subnets |
| **Author(s)** | Dhruba Basu ([@dhrubabasu](https://github.com/dhrubabasu)) |
| **Status** | Activated ([Discussion](https://github.com/avalanche-foundation/ACPs/discussions/78)) |
| **Track** | Standards |
| **Replaces** | [ACP-13](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/13-subnet-only-validators/README.md) |
## Abstract
Overhaul Subnet creation and management to unlock increased flexibility for Subnet creators by:
* Separating Subnet validators from Primary Network validators (Primary Network Partial Sync, Removal of 2000 \$AVAX requirement)
* Moving ownership of Subnet validator set management from P-Chain to Subnets (ERC-20/ERC-721/Arbitrary Staking, Staking Reward Management)
* Introducing a continuous P-Chain fee mechanism for Subnet validators (Continuous Subnet Staking)
This ACP supersedes [ACP-13](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/13-subnet-only-validators/README.md) and borrows some of its language.
## Motivation
Each node operator must stake at least 2000 $AVAX ($70k at time of writing) to first become a Primary Network validator before they qualify to become a Subnet validator. Most Subnets aim to launch with at least 8 Subnet validators, which requires staking 16000 $AVAX ($560k at time of writing). All Subnet validators, to satisfy their role as Primary Network validators, must also [allocate 8 AWS vCPU, 16 GB RAM, and 1 TB storage](https://github.com/ava-labs/avalanchego/blob/master/README.md#installation) to sync the entire Primary Network (X-Chain, P-Chain, and C-Chain) and participate in its consensus, in addition to whatever resources are required for each Subnet they are validating.
Regulated entities that are prohibited from validating permissionless, smart contract-enabled blockchains (like the C-Chain) cannot launch a Subnet because they cannot opt-out of Primary Network Validation. This deployment blocker prevents a large cohort of Real World Asset (RWA) issuers from bringing unique, valuable tokens to the Avalanche Ecosystem (that could move between C-Chain \<-> Subnets using Avalanche Warp Messaging/Teleporter).
A widely validated Subnet that is not properly metered could destabilize the Primary Network if usage spikes unexpectedly. Underprovisioned Primary Network validators running such a Subnet may exit with an OOM exception, see degraded disk performance, or find it difficult to allocate CPU time to P/X/C-Chain validation. The inverse also holds for Subnets with the Primary Network (where some undefined behavior could bring a Subnet offline).
Although the fee paid to the Primary Network to operate a Subnet does not go up with the amount of activity on the Subnet, the fixed, upfront cost of setting up a Subnet validator on the Primary Network deters new projects that prefer smaller, even variable, costs until demand is observed. *Unlike L2s that pay some increasing fee (usually denominated in units per transaction byte) to an external chain for data availability and security as activity scales, Subnets provide their own security/data availability and the only cost operators must pay from processing more activity is the hardware cost of supporting additional load.*
Elastic Subnets, introduced in [Banff](https://medium.com/avalancheavax/banff-elastic-subnets-44042f41e34c), enabled Subnet creators to activate Proof-of-Stake validation and uptime-based rewards using their own token. However, this token is required to be an ANT (created on the X-Chain) and locked on the P-Chain. All staking rewards were distributed on the P-Chain with the reward curve being defined in the `TransformSubnetTx` and, once set, was unable to be modified.
With no Elastic Subnets live on Mainnet, it is clear that Permissionless Subnets as they stand today could be more desirable. There are many successful Permissioned Subnets in production but many Subnet creators have raised the above as points of concern. In summary, the Avalanche community could benefit from a more flexible and affordable mechanism to launch Permissionless Subnets.
### A Note on Nomenclature
Avalanche Subnets are subnetworks validated by a subset of the Primary Network validator set. The new network creation flow outlined in this ACP does not require any intersection between the new network's validator set and the Primary Network's validator set. Moreover, the new networks have greater functionality and sovereignty than Subnets. To distinguish between these two kinds of networks, the community has been referring to these new networks as *Avalanche Layer 1s*, or L1s for short.
All networks created through the old network creation flow will continue to be referred to as Avalanche Subnets.
## Specification
At a high-level, L1s can manage their validator sets externally to the P-Chain by setting the blockchain ID and address of their *validator manager*. The P-Chain will consume Warp messages that modify the L1's validator set. To confirm modification of the L1's validator set, the P-Chain will also produce Warp messages. L1 validators are not required to validate the Primary Network, and do not have the same 2000 $AVAX stake requirement that Subnet validators have. To maintain an active L1 validator, a continuous fee denominated in $AVAX is assessed. L1 validators are only required to sync the P-Chain (not X/C-Chain) in order to track validator set changes and support cross-L1 communication.
### P-Chain Warp Message Payloads
To enable management of an L1's validator set externally to the P-Chain, Warp message verification will be added to the [`PlatformVM`](https://github.com/ava-labs/avalanchego/tree/master/vms/platformvm). For a Warp message to be considered valid by the P-Chain, at least 67% of the `sourceChainID`'s weight must have participated in the aggregate BLS signature. This is equivalent to the threshold set for the C-Chain. A future ACP may be proposed to support modification of this threshold on a per-L1 basis.
The following Warp message payloads are introduced on the P-Chain:
* `SubnetToL1ConversionMessage`
* `RegisterL1ValidatorMessage`
* `L1ValidatorRegistrationMessage`
* `L1ValidatorWeightMessage`
The method of requesting signatures for these messages is left unspecified. A viable option for supporting this functionality is laid out in [ACP-118](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/118-warp-signature-request/README.md) with the `SignatureRequest` message.
All node IDs contained within the message specifications are represented as variable length arrays such that they can support new node IDs types should the P-Chain add support for them in the future.
The serialization of each of these messages is as follows.
#### `SubnetToL1ConversionMessage`
The P-Chain can produce a `SubnetToL1ConversionMessage` for consumers (i.e. validator managers) to be aware of the initial validator set.
The following serialization is defined as the `ValidatorData`:
| Field | Type | Size |
| -------------: | ---------: | -----------------------: |
| `nodeID` | `[]byte` | 4 + len(`nodeID`) bytes |
| `blsPublicKey` | `[48]byte` | 48 bytes |
| `weight` | `uint64` | 8 bytes |
| | | 60 + len(`nodeID`) bytes |
The following serialization is defined as the `ConversionData`:
| Field | Type | Size |
| ---------------: | ----------------: | ---------------------------------------------------------: |
| `codecID` | `uint16` | 2 bytes |
| `subnetID` | `[32]byte` | 32 bytes |
| `managerChainID` | `[32]byte` | 32 bytes |
| `managerAddress` | `[]byte` | 4 + len(`managerAddress`) bytes |
| `validators` | `[]ValidatorData` | 4 + sum(`validatorLengths`) bytes |
| | | 74 + len(`managerAddress`) + sum(`validatorLengths`) bytes |
* `codecID` is the codec version used to serialize the payload, and is hardcoded to `0x0000`
* `sum(validatorLengths)` is the sum of the lengths of `ValidatorData` serializations included in `validators`.
* `subnetID` identifies the Subnet that is being converted to an L1 (described further below).
* `managerChainID` and `managerAddress` identify the validator manager for the newly created L1. This is the (blockchain ID, address) tuple allowed to send Warp messages to modify the L1's validator set.
* `validators` are the initial continuous-fee-paying validators for the given L1.
The `SubnetToL1ConversionMessage` is specified as an `AddressedCall` with `sourceChainID` set to the P-Chain ID, the `sourceAddress` set to an empty byte array, and a payload of:
| Field | Type | Size |
| -------------: | ---------: | -------: |
| `codecID` | `uint16` | 2 bytes |
| `typeID` | `uint32` | 4 bytes |
| `conversionID` | `[32]byte` | 32 bytes |
| | | 38 bytes |
* `codecID` is the codec version used to serialize the payload, and is hardcoded to `0x0000`
* `typeID` is the payload type identifier and is `0x00000000` for this message
* `conversionID` is the SHA256 hash of the `ConversionData` from a given `ConvertSubnetToL1Tx`
#### `RegisterL1ValidatorMessage`
The P-Chain can consume a `RegisterL1ValidatorMessage` from validator managers through a `RegisterL1ValidatorTx` to register an addition to the L1's validator set.
The following is the serialization of a `PChainOwner`:
| Field | Type | Size |
| ----------: | -----------: | ---------------------------------: |
| `threshold` | `uint32` | 4 bytes |
| `addresses` | `[][20]byte` | 4 + len(`addresses`) \\\* 20 bytes |
| | | 8 + len(`addresses`) \\\* 20 bytes |
* `threshold` is the number of `addresses` that must provide a signature for the `PChainOwner` to authorize an action.
* Validation criteria:
* If `threshold` is `0`, `addresses` must be empty
* `threshold` \<= len(`addresses`)
* Entries of `addresses` must be unique and sorted in ascending order
The `RegisterL1ValidatorMessage` is specified as an `AddressedCall` with a payload of:
| Field | Type | Size |
| ----------------------: | ------------: | --------------------------------------------------------------------------: |
| `codecID` | `uint16` | 2 bytes |
| `typeID` | `uint32` | 4 bytes |
| `subnetID` | `[32]byte` | 32 bytes |
| `nodeID` | `[]byte` | 4 + len(`nodeID`) bytes |
| `blsPublicKey` | `[48]byte` | 48 bytes |
| `expiry` | `uint64` | 8 bytes |
| `remainingBalanceOwner` | `PChainOwner` | 8 + len(`addresses`) \\\* 20 bytes |
| `disableOwner` | `PChainOwner` | 8 + len(`addresses`) \\\* 20 bytes |
| `weight` | `uint64` | 8 bytes |
| | | 122 + len(`nodeID`) + (len(`addresses1`) + len(`addresses2`)) \\\* 20 bytes |
* `codecID` is the codec version used to serialize the payload, and is hardcoded to `0x0000`
* `typeID` is the payload type identifier and is `0x00000001` for this payload
* `subnetID`, `nodeID`, `weight`, and `blsPublicKey` are for the validator being added
* `expiry` is the time at which this message becomes invalid. As of a P-Chain timestamp `>= expiry`, this Avalanche Warp Message can no longer be used to add the `nodeID` to the validator set of `subnetID`
* `remainingBalanceOwner` is the P-Chain owner where leftover \$AVAX from the validator's Balance will be issued to when this validator it is removed from the validator set.
* `disableOwner` is the only P-Chain owner allowed to disable the validator using `DisableL1ValidatorTx`, specified below.
#### `L1ValidatorRegistrationMessage`
The P-Chain can produce an `L1ValidatorRegistrationMessage` for consumers to verify that a validation period has either begun or has been invalidated.
The `L1ValidatorRegistrationMessage` is specified as an `AddressedCall` with `sourceChainID` set to the P-Chain ID, the `sourceAddress` set to an empty byte array, and a payload of:
| Field | Type | Size |
| -------------: | ---------: | -------: |
| `codecID` | `uint16` | 2 bytes |
| `typeID` | `uint32` | 4 bytes |
| `validationID` | `[32]byte` | 32 bytes |
| `registered` | `bool` | 1 byte |
| | | 39 bytes |
* `codecID` is the codec version used to serialize the payload, and is hardcoded to `0x0000`
* `typeID` is the payload type identifier and is `0x00000002` for this message
* `validationID` identifies the validator for the message
* `registered` is a boolean representing the status of the `validationID`. If true, the `validationID` corresponds to a validator in the current validator set. If false, the `validationID` does not correspond to a validator in the current validator set, and never will in the future.
#### `L1ValidatorWeightMessage`
The P-Chain can consume an `L1ValidatorWeightMessage` through a `SetL1ValidatorWeightTx` to update the weight of an existing validator. The P-Chain can also produce an `L1ValidatorWeightMessage` for consumers to verify that the validator weight update has been effectuated.
The `L1ValidatorWeightMessage` is specified as an `AddressedCall` with the following payload. When sent from the P-Chain, the `sourceChainID` is set to the P-Chain ID, and the `sourceAddress` is set to an empty byte array.
| Field | Type | Size |
| -------------: | ---------: | -------: |
| `codecID` | `uint16` | 2 bytes |
| `typeID` | `uint32` | 4 bytes |
| `validationID` | `[32]byte` | 32 bytes |
| `nonce` | `uint64` | 8 bytes |
| `weight` | `uint64` | 8 bytes |
| | | 54 bytes |
* `codecID` is the codec version used to serialize the payload, and is hardcoded to `0x0000`
* `typeID` is the payload type identifier and is `0x00000003` for this message
* `validationID` identifies the validator for the message
* `nonce` is a strictly increasing number that denotes the latest validator weight update and provides replay protection for this transaction
* `weight` is the new `weight` of the validator
### New P-Chain Transaction Types
Both before and after this ACP, to create a Subnet, a `CreateSubnetTx` must be issued on the P-Chain. This transaction includes an `Owner` field which defines the key that today can be used to authorize any validator set additions (`AddSubnetValidatorTx`) or removals (`RemoveSubnetValidatorTx`).
To be considered a permissionless network, or Avalanche Layer 1:
* This `Owner` key must no longer have the ability to modify the validator set.
* New transaction types must support modification of the validator set via Warp messages.
The following new transaction types are introduced on the P-Chain to support this functionality:
* `ConvertSubnetToL1Tx`
* `RegisterL1ValidatorTx`
* `SetL1ValidatorWeightTx`
* `DisableL1ValidatorTx`
* `IncreaseL1ValidatorBalanceTx`
#### `ConvertSubnetToL1Tx`
To convert a Subnet into an L1, a `ConvertSubnetToL1Tx` must be issued to set the `(chainID, address)` pair that will manage the L1's validator set. The `Owner` key defined in `CreateSubnetTx` must provide a signature to authorize this conversion.
The `ConvertSubnetToL1Tx` specification is:
```go
type PChainOwner struct {
// The threshold number of `Addresses` that must provide a signature in order for
// the `PChainOwner` to be considered valid.
Threshold uint32 `json:"threshold"`
// The 20-byte addresses that are allowed to sign to authenticate a `PChainOwner`.
// Note: It is required for:
// - len(Addresses) == 0 if `Threshold` is 0.
// - len(Addresses) >= `Threshold`
// - The values in Addresses to be sorted in ascending order.
Addresses []ids.ShortID `json:"addresses"`
}
type L1Validator struct {
// NodeID of this validator
NodeID []byte `json:"nodeID"`
// Weight of this validator used when sampling
Weight uint64 `json:"weight"`
// Initial balance for this validator
Balance uint64 `json:"balance"`
// [Signer] is the BLS public key and proof-of-possession for this validator.
// Note: We do not enforce that the BLS key is unique across all validators.
// This means that validators can share a key if they so choose.
// However, a NodeID + L1 does uniquely map to a BLS key
Signer signer.ProofOfPossession `json:"signer"`
// Leftover $AVAX from the [Balance] will be issued to this
// owner once it is removed from the validator set.
RemainingBalanceOwner PChainOwner `json:"remainingBalanceOwner"`
// The only owner allowed to disable this validator on the P-Chain.
DisableOwner PChainOwner `json:"disableOwner"`
}
type ConvertSubnetToL1Tx struct {
// Metadata, inputs and outputs
BaseTx
// ID of the Subnet to transform
// Restrictions:
// - Must not be the Primary Network ID
Subnet ids.ID `json:"subnetID"`
// BlockchainID where the validator manager lives
ChainID ids.ID `json:"chainID"`
// Address of the validator manager
Address []byte `json:"address"`
// Initial continuous-fee-paying validators for the L1
Validators []L1Validator `json:"validators"`
// Authorizes this conversion
SubnetAuth verify.Verifiable `json:"subnetAuthorization"`
}
```
After this transaction is accepted, `CreateChainTx` and `AddSubnetValidatorTx` are disabled on the Subnet. The only action that the `Owner` key is able to take is removing Subnet validators with `RemoveSubnetValidatorTx` that had been added using `AddSubnetValidatorTx`. Unless removed by the `Owner` key, any Subnet validators added previously with an `AddSubnetValidatorTx` will continue to validate the Subnet until their [`End`](https://github.com/ava-labs/avalanchego/blob/a1721541754f8ee23502b456af86fea8c766352a/vms/platformvm/txs/validator.go#L27) time is reached. Once all Subnet validators added with `AddSubnetValidatorTx` are no longer in the validator set, the `Owner` key is powerless. `RegisterL1ValidatorTx` and `SetL1ValidatorWeightTx` must be used to manage the L1's validator set.
The `validationID` for validators added through `ConvertSubnetToL1Tx` is defined as the SHA256 hash of the 36 bytes resulting from concatenating the 32 byte `subnetID` with the 4 byte `validatorIndex` (index in the `Validators` array within the transaction).
Once this transaction is accepted, the P-Chain must be willing sign a `SubnetToL1ConversionMessage` with a `conversionID` corresponding to `ConversionData` populated with the values from this transaction.
#### `RegisterL1ValidatorTx`
After a `ConvertSubnetToL1Tx` has been accepted, new validators can only be added by using a `RegisterL1ValidatorTx`. The specification of this transaction is:
```go
type RegisterL1ValidatorTx struct {
// Metadata, inputs and outputs
BaseTx
// Balance <= sum($AVAX inputs) - sum($AVAX outputs) - TxFee.
Balance uint64 `json:"balance"`
// [Signer] is a BLS signature proving ownership of the BLS public key specified
// below in `Message` for this validator.
// Note: We do not enforce that the BLS key is unique across all validators.
// This means that validators can share a key if they so choose.
// However, a NodeID + L1 does uniquely map to a BLS key
Signer [96]byte `json:"signer"`
// A RegisterL1ValidatorMessage payload
Message warp.Message `json:"message"`
}
```
The `validationID` of validators added via `RegisterL1ValidatorTx` is defined as the SHA256 hash of the `Payload` of the `AddressedCall` in `Message`.
When a `RegisterL1ValidatorTx` is accepted on the P-Chain, the validator is added to the L1's validator set. A `minNonce` field corresponding to the `validationID` will be stored on addition to the validator set (initially set to `0`). This field will be used when validating the `SetL1ValidatorWeightTx` defined below.
This `validationID` will be used for replay protection. Used `validationID`s will be stored on the P-Chain. If a `RegisterL1ValidatorTx`'s `validationID` has already been used, the transaction will be considered invalid. To prevent storing an unbounded number of `validationID`s, the `expiry` of the `RegisterL1ValidatorMessage` is required to be no more than 24 hours in the future of the time the transaction is issued on the P-Chain. Any `validationIDs` corresponding to an expired timestamp can be flushed from the P-Chain's state.
L1s are responsible for defining the procedure on how to retrieve the above information from prospective validators.
An EVM-compatible L1 may choose to implement this step like so:
* Use the number of tokens the user has staked into a smart contract on the L1 to determine the weight of their validator
* Require the user to submit an on-chain transaction with their validator information
* Generate the Warp message
For a `RegisterL1ValidatorTx` to be valid, `Signer` must be a valid proof-of-possession of the `blsPublicKey` defined in the `RegisterL1ValidatorMessage` contained in the transaction.
After a `RegisterL1ValidatorTx` is accepted, the P-Chain must be willing to sign an `L1ValidatorRegistrationMessage` for the given `validationID` with `registered` set to `true`. This remains the case until the time at which the validator is removed from the validator set using a `SetL1ValidatorWeightTx`, as described below.
When it is known that a given `validationID` *is not and never will be* registered, the P-Chain must be willing to sign an `L1ValidatorRegistrationMessage` for the `validationID` with `registered` set to `false`. This could be the case if the `expiry` time of the message has passed prior to the message being delivered in a `RegisterL1ValidatorTx`, or if the validator was successfully registered and then later removed. This enables the P-Chain to prove to validator managers that a validator has been removed or never added. The P-Chain must refuse to sign any `L1ValidatorRegistrationMessage` where the `validationID` does not correspond to an active validator and the `expiry` is in the future.
#### `SetL1ValidatorWeightTx`
`SetL1ValidatorWeightTx` is used to modify the voting weight of a validator. The specification of this transaction is:
```go
type SetL1ValidatorWeightTx struct {
// Metadata, inputs and outputs
BaseTx
// An L1ValidatorWeightMessage payload
Message warp.Message `json:"message"`
}
```
Applications of this transaction could include:
* Increase the voting weight of a validator if a delegation is made on the L1
* Increase the voting weight of a validator if the stake amount is increased (by staking rewards for example)
* Decrease the voting weight of a misbehaving validator
* Remove an inactive validator
The validation criteria for `L1ValidatorWeightMessage` is:
* `nonce >= minNonce`. Note that `nonce` is not required to be incremented by `1` with each successive validator weight update.
* When `minNonce == MaxUint64`, `nonce` must be `MaxUint64` and `weight` must be `0`. This prevents L1s from being unable to remove `nodeID` in a subsequent transaction.
* If `weight == 0`, the validator being removed must not be the last one in the set. If all validators are removed, there are no valid Warp messages that can be produced to register new validators through `RegisterL1ValidatorMessage`. With no validators, block production will halt and the L1 is unrecoverable. This validation criteria serves as a guardrail against this situation. A future ACP can remove this guardrail as users get more familiar with the new L1 mechanics and tooling matures to fork an L1.
When `weight != 0`, the weight of the validator is updated to `weight` and `minNonce` is updated to `nonce + 1`.
When `weight == 0`, the validator is removed from the validator set. All state related to the validator, including the `minNonce` and `validationID`, are reaped from the P-Chain state. Tracking these post-removal is not required since `validationID` can never be re-initialized due to the replay protection provided by `expiry` in `RegisterL1ValidatorTx`. Any unspent \$AVAX in the validator's `Balance` will be issued in a single UTXO to the `RemainingBalanceOwner` for this validator. Recall that `RemainingBalanceOwner` is specified when the validator is first added to the L1's validator set (in either `ConvertSubnetToL1Tx` or `RegisterL1ValidatorTx`).
Note: There is no explicit `EndTime` for L1 validators added in a `ConvertSubnetToL1Tx` or `RegisterL1ValidatorTx`. The only time when L1 validators are removed from the L1's validator set is through this transaction when `weight == 0`.
#### `DisableL1ValidatorTx`
L1 validators can use `DisableL1ValidatorTx` to mark their validator as inactive. The specification of this transaction is:
```go
type DisableL1ValidatorTx struct {
// Metadata, inputs and outputs
BaseTx
// ID corresponding to the validator
ValidationID ids.ID `json:"validationID"`
// Authorizes this validator to be disabled
DisableAuth verify.Verifiable `json:"disableAuthorization"`
}
```
The `DisableOwner` specified for this validator must sign the transaction. Any unspent \$AVAX in the validator's `Balance` will be issued in a single UTXO to the `RemainingBalanceOwner` for this validator. Recall that both `DisableOwner` and `RemainingBalanceOwner` are specified when the validator is first added to the L1's validator set (in either `ConvertSubnetToL1Tx` or `RegisterL1ValidatorTx`).
For full removal from an L1's validator set, a `SetL1ValidatorWeightTx` must be issued with weight `0`. To do so, a Warp message is required from the L1's validator manager. However, to support the ability to claim the unspent `Balance` for a validator without authorization is critical for failed L1s.
Note that this does not modify an L1's total staking weight. This transaction marks the validator as inactive, but does not remove it from the L1's validator set. Inactive validators can re-activate at any time by increasing their balance with an `IncreaseL1ValidatorBalanceTx`.
L1 creators should be aware that there is no notion of `MinStakeDuration` that is enforced by the P-Chain. It is expected that L1s who choose to enforce a `MinStakeDuration` will lock the validator's Stake for the L1's desired `MinStakeDuration`.
#### `IncreaseL1ValidatorBalanceTx`
L1 validators are required to maintain a non-zero balance used to pay the continuous fee on the P-Chain in order to be considered active. The `IncreaseL1ValidatorBalanceTx` can be used by anybody to add additional \$AVAX to the `Balance` to a validator. The specification of this transaction is:
```go
type IncreaseL1ValidatorBalanceTx struct {
// Metadata, inputs and outputs
BaseTx
// ID corresponding to the validator
ValidationID ids.ID `json:"validationID"`
// Balance <= sum($AVAX inputs) - sum($AVAX outputs) - TxFee
Balance uint64 `json:"balance"`
}
```
If the validator corresponding to `ValidationID` is currently inactive (`Balance` was exhausted or `DisableL1ValidatorTx` was issued), this transaction will move them back to the active validator set.
Note: The \$AVAX added to `Balance` can be claimed at any time by the validator using `DisableL1ValidatorTx`.
### Bootstrapping L1 Nodes
Bootstrapping a node/validator is the process of securely recreating the latest state of the blockchain locally. At the end of this process, the local state of a node/validator must be in sync with the local state of other virtuous nodes/validators. The node/validator can then verify new incoming transactions and reach consensus with other nodes/validators.
To bootstrap a node/validator, a few critical questions must be answered: How does one discover peers in the network? How does one determine that a discovered peer is honestly participating in the network?
For standalone networks like the Avalanche Primary Network, this is done by connecting to a hardcoded [set](https://github.com/ava-labs/avalanchego/blob/master/genesis/bootstrappers.json) of trusted bootstrappers to then discover new peers. Ethereum calls their set [bootnodes](https://ethereum.org/developers/docs/nodes-and-clients/bootnodes).
Since L1 validators are not required to be Primary Network validators, a list of validator IPs to connect to (the functional bootstrappers of the L1) cannot be provided by simply connecting to the Primary Network validators. However, the Primary Network can enable nodes tracking an L1 to seamlessly connect to the validators by tracking and gossiping L1 validator IPs. L1s will not need to operate and maintain a set of bootstrappers and can rely on the Primary Network for peer discovery.
### Sidebar: L1 Sovereignty
After this ACP is activated, the P-Chain will no longer support staking of any assets other than $AVAX for the Primary Network. The P-Chain will not support the distribution of staking rewards for L1s. All staking-related operations for L1 validation must be managed by the L1's validator manager. The P-Chain simply requires a continuous fee per validator. If an L1 would like to manage their validator's balances on the P-Chain, it can cover the cost for all L1 validators by posting the $AVAX balance on the P-Chain. L1s can implement any mechanism they want to pay the continuous fee charged by the P-Chain for its participants.
The L1 has full ownership over its validator set, not the P-Chain. There are no restrictions on what requirements an L1 can have for validators to join. Any stake that is required to join the L1's validator set is not locked on the P-Chain. If a validator is removed from the L1's validator set via a `SetL1ValidatorWeightTx` with weight `0`, the stake will continue to be locked outside of the P-Chain. How each L1 handles stake associated with the validator is entirely left up to the L1 and can be treated independently to what happens on the P-Chain.
The relationship between the P-Chain and L1s provides a dynamic where L1s can use the P-Chain as an impartial judge to modify parameters (in addition to its existing role of helping to validate incoming Avalanche Warp Messages). If a validator is misbehaving, the L1 validators can collectively generate a BLS multisig to reduce the voting weight of a misbehaving validator. This operation is fully secured by the Avalanche Primary Network (225M $AVAX or $8.325B at the time of writing).
Follow-up ACPs could extend the P-Chain \<-> L1 relationship to include parametrization of the 67% threshold to enable L1s to choose a different threshold based on their security model (e.g. a simple majority of 51%).
### Continuous Fee Mechanism
Every additional validator on the P-Chain adds persistent load to the Avalanche Network. When a validator transaction is issued on the P-Chain, it is charged for the computational cost of the transaction itself but is not charged for the cost of an active validator over the time they are validating on the network (which may be indefinitely). This is a common problem in blockchains, spawning many state rent proposals in the broader blockchain space to address it. The following fee mechanism takes advantage of the fact that each L1 validator uses the same amount of computation and charges each L1 validator the dynamic base fee for every discrete unit of time it is active.
To charge each L1 validator, the notion of a `Balance` is introduced. The `Balance` of a validator will be continuously charged during the time they are active to cover the cost of storing the associated validator properties (BLS key, weight, nonce) in memory and to track IPs (in addition to other services provided by the Primary Network). This `Balance` is initialized with the `RegisterL1ValidatorTx` that added them to the active validator set. `Balance` can be increased at any time using the `IncreaseL1ValidatorBalanceTx`. When this `Balance` reaches `0`, the validator will be considered "inactive" and will no longer participate in validating the L1. Inactive validators can be moved back to the active validator set at any time using the same `IncreaseL1ValidatorBalanceTx`. Once a validator is considered inactive, the P-Chain will remove these properties from memory and only retain them on disk. All messages from that validator will be considered invalid until it is revived using the `IncreaseL1ValidatorBalanceTx`. L1s can reduce the amount of inactive weight by removing inactive validators with the `SetL1ValidatorWeightTx` (`Weight` = 0).
Since each L1 validator is charged the same amount at each point in time, tracking the fees for the entire validator set is straight-forward. The accumulated dynamic base fee for the entire network is tracked in a single uint. This accumulated value should be equal to the fee charged if a validator was active from the time the accumulator was instantiated. The validator set is maintained in a priority queue. A pseudocode implementation of the continuous fee mechanism is provided below.
```python
# Pseudocode
class ValidatorQueue:
def __init__(self, fee_getter):
self.acc = 0
self.queue = PriorityQueue()
self.fee_getter = fee_getter
# At each time period, increment the accumulator and
# pop all validators from the top of the queue that
# ran out of funds.
# Note: The amount of work done in a single block
# should be bounded to prevent a large number of
# validator operations from happening at the same
# time.
def time_elapse(self, t):
self.acc = self.acc + self.fee_getter(t)
while True:
vdr = self.queue.peek()
if vdr.balance < self.acc:
self.queue.pop()
continue
return
# Validator was added
def validator_enter(self, vdr):
vdr.balance = vdr.balance + self.acc
self.queue.add(vdr)
# Validator was removed
def validator_remove(self, vdrNodeID):
vdr = find_and_remove(self.queue, vdrNodeID)
vdr.balance = vdr.balance - self.acc
vdr.refund() # Refund [vdr.balance] to [RemainingBalanceOwner]
self.queue.remove()
# Validator's balance was topped up
def validator_increase(self, vdrNodeID, balance):
vdr = find_and_remove(self.queue, vdrNodeID)
vdr.balance = vdr.balance + balance
self.queue.add(vdr)
```
#### Fee Algorithm
[ACP-103](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/103-dynamic-fees/README.md) proposes a dynamic fee mechanism for transactions on the P-Chain. This mechanism is repurposed with minor modifications for the active L1 validator continuous fee.
At activation, the number of excess active L1 validators $x$ is set to `0`.
The fee rate per second for an active L1 validator is:
$M \cdot \exp\left(\frac{x}{K}\right)$
Where:
* $M$ is the minimum price for an active L1 validator
* $\exp\left(x\right)$ is an approximation of $e^x$ following the EIP-4844 specification
```python
# Approximates factor * e ** (numerator / denominator) using Taylor expansion
def fake_exponential(factor: int, numerator: int, denominator: int) -> int:
i = 1
output = 0
numerator_accum = factor * denominator
while numerator_accum > 0:
output += numerator_accum
numerator_accum = (numerator_accum * numerator) // (denominator * i)
i += 1
return output // denominator
```
* $K$ is a constant to control the rate of change for the L1 validator price
After every second, $x$ will be updated:
$x = \max(x + (V - T), 0)$
Where:
* $V$ is the number of active L1 validators
* $T$ is the target number of active L1 validators
Whenever $x$ increases by $K$, the price per active L1 validator increases by a factor of `~2.7`. If the price per active L1 validator gets too expensive, some active L1 validators will exit the active validator set, decreasing $x$, dropping the price. The price per active L1 validator constantly adjusts to make sure that, on average, the P-Chain has no more than $T$ active L1 validators.
#### Block Processing
Before processing the transactions inside a block, all validators that no longer have a sufficient (non-zero) balance are deactivated.
After processing the transactions inside a block, all validators that do not have a sufficient balance for the next second are deactivated.
##### Block Timestamp Validity Change
To ensure that validators are charged accurately, blocks are only considered valid if advancing the chain times would not cause a validator to have a negative balance.
This upholds the expectation that the number of L1 validators remains constant between blocks.
The block building protocol is modified to account for this change by first checking if the wall clock time removes any validator due to a lack of funds. If the wall clock time does not remove any L1 validators, the wall clock time is used to build the block. If it does, the time at which the first validator gets removed is used.
##### Fee Calculation
The total validator fee assessed in $\Delta t$ is:
```python
# Calculate the fee to charge over Δt
def cost_over_time(V:int, T:int, x:int, Δt: int) -> int:
cost = 0
for _ in range(Δt):
x = max(x + V - T, 0)
cost += fake_exponential(M, x, K)
return cost
```
#### Parameters
The parameters at activation are:
| Parameter | Definition | Value |
| --------- | ------------------------------------------- | ---------------- |
| $T$ | target number of validators | 10\_000 |
| $C$ | capacity number of validators | 20\_000 |
| $M$ | minimum fee rate | 512 nAVAX/s |
| $K$ | constant to control the rate of fee changes | 1\_246\_488\_515 |
An $M$ of 512 nAVAX/s equates to \~1.33 AVAX/month to run an L1 validator, so long as the total number of continuous-fee-paying L1 validators stays at or below $T$.
$K$ was chosen to set the maximum fee doubling rate to \~24 hours. This is in the extreme case that the network has $C$ validators for prolonged periods of time; if the network has $T$+1 validators for example, the fee rate would double every \~27 years.
A future ACP can adjust the parameters to increase $T$, reduce $M$, and/or modify $K$.
#### User Experience
L1 validators are continuously charged a fee, albeit a small one. This poses a challenge for L1 validators: How do they maintain the balance over time?
Node clients should expose an API to track how much balance is remaining in the validator's account. This will provide a way for L1 validators to track how quickly it is going down and top-up when needed. A nice byproduct of the above design is the balance in the validator's account is claimable. This means users can top-up as much \$AVAX as they want and rest-assured knowing they can always retrieve it if there is an excessive amount.
The expectation is that most users will not interact with node clients or track when or how much they need to top-up their validator account. Wallet providers will abstract away most of this process. For users who desire more convenience, L1-as-a-Service providers will abstract away all of this process.
## Backwards Compatibility
This new design for Subnets proposes a large rework to all L1-related mechanics. Rollout should be done on a going-forward basis to not cause any service disruption for live Subnets. All current Subnet validators will be able to continue validating both the Primary Network and whatever Subnets they are validating.
Any state execution changes must be coordinated through a mandatory upgrade. Implementors must take care to continue to verify the existing ruleset until the upgrade is activated. After activation, nodes should verify the new ruleset. Implementors must take care to only verify the presence of 2000 \$AVAX prior to activation.
### Deactivated Transactions
* P-Chain
* `TransformSubnetTx`
After this ACP is activated, Elastic Subnets will be disabled. `TransformSubnetTx` will not be accepted post-activation. As there are no Mainnet Elastic Subnets, there should be no production impact with this deactivation.
### New Transactions
* P-Chain
* `ConvertSubnetToL1Tx`
* `RegisterL1ValidatorTx`
* `SetL1ValidatorWeightTx`
* `DisableL1ValidatorTx`
* `IncreaseL1ValidatorBalanceTx`
## Reference Implementation
ACP-77 was implemented and will be merged into AvalancheGo behind the `Etna` upgrade flag. The full body of work can be found tagged with the `acp77` label [here](https://github.com/ava-labs/avalanchego/issues?q=sort%3Aupdated-desc+label%3Aacp77).
Since Etna is not yet activated, all new transactions introduced in ACP-77 will be rejected by AvalancheGo. If any modifications are made to ACP-77 as part of the ACP process, the implementation must be updated prior to activation.
## Security Considerations
This ACP introduces Avalanche Layer 1s, a new network type that costs significantly less than Avalanche Subnets. This can lead to a large increase in the number of networks and, by extension, the number of validators. Each additional validator adds consistent RAM usage to the P-Chain. However, this should be appropriately metered by the continuous fee mechanism outlined above.
With the sovereignty L1s have from the P-Chain, L1 staking tokens are not locked on the P-Chain. This poses a security consideration for L1 validators: Malicious chains can choose to remove validators at will and take any funds that the validator has locked on the L1. The P-Chain only provides the guarantee that L1 validators can retrieve the remaining \$AVAX Balance for their validator via a `DisableL1ValidatorTx`. Any assets on the L1 is entirely under the purview of the L1. The onus is on L1 validators to vet the L1's security for any assets transferred onto the L1.
With a long window of expiry (24 hours) for the Warp message in `RegisterL1ValidatorTx`, spam of validator registration could lead to high memory pressure on the P-Chain. A future ACP can reduce the window of expiry if 24 hours proves to be a problem.
NodeIDs can be added to an L1's validator set involuntarily. However, it is important to note that any stake/rewards are *not* at risk. For a node operator who was added to a validator set involuntarily, they would only need to generate a new NodeID via key rotation as there is no lock-up of any stake to create a NodeID. This is an explicit tradeoff for easier on-boarding of NodeIDs. This mirrors the Primary Network validators guarantee of no stake/rewards at risk.
The continuous fee mechanism outlined above does not apply to inactive L1 validators since they are not stored in memory. However, inactive L1 validators are persisted on disk which can lead to persistent P-Chain state growth. A future ACP can introduce a mechanism to decrease the rate of P-Chain state growth or provide a state expiry path to reduce the amount of P-Chain state.
## Acknowledgements
Special thanks to [@StephenButtolph](https://github.com/StephenButtolph), [@aaronbuchwald](https://github.com/aaronbuchwald), and [@patrick-ogrady](https://github.com/patrick-ogrady) for their feedback on these ideas. Thank you to the broader Ava Labs Platform Engineering Group for their feedback on this ACP prior to publication.
## Copyright
Copyright and related rights waived via [CC0](https://creativecommons.org/publicdomain/zero/1.0/).
# ACP-83: Dynamic Multidimensional Fees
URL: /docs/acps/83-dynamic-multidimensional-fees
Details for Avalanche Community Proposal 83: Dynamic Multidimensional Fees
| ACP | 83 |
| :---------------- | :------------------------------------------------------------------------------------------------ |
| **Title** | Dynamic multidimensional fees for P-chain and X-chain |
| **Author(s)** | Alberto Benegiamo ([@abi87](https://github.com/abi87)) |
| **Status** | Stale |
| **Track** | Standards |
| **Superseded-By** | [ACP-103](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/103-dynamic-fees/README.md) |
## Abstract
Introduce a dynamic and multidimensional fees scheme for the P-chain and X-chain.
Dynamic fees helps to preserve the stability of the chain as it provides a feedback mechanism that increases the cost of resources when the network operates above its target utilization.
Multidimensional fees ensures that high demand for orthogonal resources does not drive up the price of underutilized resources. For example, networks provide and consume orthogonal resources including, but not limited to, bandwidth, chain state, read/write throughput, and CPU. By independently metering each resource, they can be granularly priced and stay closer to optimal resource utilization.
## Motivation
The P-Chain and X-Chain currently have fixed fees and in some cases those fees are fixed to zero.
This makes transaction issuance predictable, but does not provide feedback mechanism to preserve chain stability under high load. In contrast, the C-Chain, which has the highest and most regular load among the chains on the Primary Network, already supports dynamic fees. This ACP proposes to introduce a similar dynamic fee mechanism for the P-Chain and X-Chain to further improve the Primary Network's stability and resilience under load.
However, unlike the C-Chain, we propose a multidimensional fee scheme with an exponential update rule for each fee dimension. The [HyperSDK](https://github.com/ava-labs/hypersdk) already utilizes a multidimensional fee scheme with optional priority fees and its efficiency is backed by [academic research](https://arxiv.org/abs/2208.07919).
Finally, we split the fee into two parts: a `base fee` and a `priority fee`. The `base fee` is calculated by the network each block to accurately price each resource at a given point in time. Whatever amount greater than the base fee is burnt is treated as the `priority fee` to prioritize faster transaction inclusion.
## Specification
We introduce the multidimensional scheme first and then how to apply the dynamic fee update rule for each fee dimension. Finally we list the new block verification rules, valid once the new fee scheme activates.
### Multidimensional scheme components
We define four fee dimensions, `Bandwidth`, `Reads`, `Writes`, `Compute`, to describe transactions complexity. In more details:
* `Bandwidth` measures the transaction size in bytes, as encoded by the AvalancheGo codec. Byte length is a proxy for the network resources needed to disseminate the transaction.
* `Reads` measures the number of DB reads needed to verify the transactions. DB reads include UTXOs reads and any other state quantity relevant for the specific transaction.
* `Writes` measures the number of DB writes following the transaction verification. DB writes include UTXOs generated as outputs of the transactions and any other state quantity relevant for the specific transaction.
* `Compute` measures the number of signatures to be verified, including UTXOs ones and those related to authorization of specific operations.
For each fee dimension $i$, we define:
* *fee rate* $r_i$ as the price, denominated in AVAX, to be paid for a transaction with complexity $u_i$ along the fee dimension $i$.
* *base fee* as the minimal fee needed to accept a transaction. Base fee is given be the formula
$base \ fee = \sum_{i=0}^3 r_i \times u_i$
* *priority fee* as an optional fee paid on top of the base fee to speed up the transaction inclusion in a block.
### Dynamic scheme components
Fee rates are updated in time, to allow a fee increase when network is getting congested. Each new block is a potential source of congestion, as its transactions carry complexity that each validator must process to verify and eventually accept the block. The more complexity carries a block, and the more rapidly blocks are produced, the higher the congestion.
We seek a scheme that rapidly increases the fees when blocks complexity goes above a defined threshold and that equally rapidly decreases the fees once complexity goes down (because blocks carry less/simpler transactions, or because they are produced more slowly). We define the desired threshold as a *target complexity rate* $T$: we would want to process every second a block whose complexity is $T$. Any complexity more than that causes some congestion that we want to penalize via fees.
In order to update fees rates we track, per each block and each fee dimension, a parameter called cumulative excess complexity. Fee rates applied to a block will be defined in terms of cumulative excess complexity as we show in the following.
Suppose that a block $B_t$ is the current chain tip. $B_t$ has the following features:
* $t$ is its timestamp.
* $\Delta C_t$ is the cumulative excess complexity along fee dimension $i$.
Say a new block $B_{t + \Delta T}$ is built on top of $B$, with the following features:
* $t + \Delta T$ is its timestamp
* $C_{t + \Delta T}$ is its complexity along fee dimension $i$.
Then the fee rate $r_{t + \Delta T}$ applied for the block $B_{t + \Delta T}$ along dimension $i$ will be:
$r_{t + \Delta T} = r^{min} \times e^{\frac{max(0, \Delta C_t - T \times \Delta T)}{Denom}}$
where
* $r^{min}$ is the minimal fee rate along fee dimension $i$
* $T$ is the target complexity rate along fee dimension $i$
* $Denom$ is a normalization constant for the fee dimension $i$
Moreover, once the block $B_{t + \Delta T}$ is accepted, the cumulative excess complexity is updated as follows:
$\Delta C_{t + \Delta T} = max\large(0, \Delta C_{t} - T \times \Delta T\large) + C_{t + \Delta T}$
The fee rate update formula guarantees that fee rates increase if incoming blocks are complex (large $C_{t + \Delta T}$) and if blocks are emitted rapidly (small $\Delta T$). Symmetrically, fee rates decrease to the minimum if incoming blocks are less complex and if blocks are produced less frequently.\
The update formula has a few paramenters to be tuned, independently, for each fee dimension. We defer discussion about tuning to the [implementation section](#tuning-the-update-formula).
## Block verification rules
Upon activation of the dynamic multidimensional fees scheme we modify block processing as follows:
* **Bound block complexity**. For each fee dimension $i$, we define a *maximal block complexity* $Max$. A block is only valid if the block complexity $C$ is less than the maximum block complexity: $C \leq Max$.
* **Verify transaction fee**. When verifying each transaction in a block, we confirm that it can cover its own base fee. Note that both base fee and optional priority fees are burned.
## User Experience
### How will the wallets estimate the fees?
AvalancheGo nodes will provide new APIs exposing the current and expected fee rates, as they are likely to change block by block. Wallets can then use the fees rates to select UTXOs to pay the transaction fees. Moreover, the AvalancheGo implementation proposed above offers a `fees.Calculator` struct that can be reused by wallets and downstream projects to evaluate calculate fees.
### How will wallets be able to re-issue Txs at a higher fee?
Wallets should be able to simply re-issue the transaction since current AvalancheGo implementation drops mempool transactions whose fee rate is lower than current one. More specifically, a transaction may be valid the moment it enters the mempool and it won’t be re-verified as long as it stays in there. However, as soon as the transaction is selected to be included in the next block, it is re-verified against the latest preferred tip. If fees are not enough by this time, the transaction is dropped and the wallet can simply re-issue it at a higher fee, or wait for the fee rate to go down. Note that priority fees offer some buffer space against an increase in the fee rate. A transaction paying just the base fee will be evicted from the mempool in the face of a fee rate increase, while a transaction paying some extra priority fee may have enough buffer room to stay valid after some amount of fee increase.
### How does priority fees guarantee a faster block inclusion?
AvalancheGo mempool will be restructured to order transactions by priority fees. Transactions paying priority fees will be selected for block inclusion first, without violating any spend dependency.
## Backwards Compatibility
Modifying the fee scheme for P-Chain and X-Chain requires a mandatory upgrade for activation. Moreover, wallets must be modified to properly handle the new fee scheme once activated.
## Reference Implementation
The implementation is split across multiple PRs:
* P-Chain work is tracked in this issue: [https://github.com/ava-labs/avalanchego/issues/2707](https://github.com/ava-labs/avalanchego/issues/2707)
* X-Chain work is tracked in this issue: [https://github.com/ava-labs/avalanchego/issues/2708](https://github.com/ava-labs/avalanchego/issues/2708)
A very important implementation step is tuning the update formula parameters for each chain and each fee dimension. We show here the principles we followed for tuning and a simulation based on historical data.
### Tuning the update formula
The basic idea is to measure the complexity of blocks already accepted and derive the parameters from it. You can find the historical data in [this repo](https://github.com/abi87/complexities).\
To simplify the exposition I am purposefully ignoring chain specifics (like P-chain proposal blocks). We can account for chain specifics while processing the historical data. Here are the principles:
* **Target block complexity rate $T$**: calculate the distribution of block complexity and pick a high enough quantile.
* **Max block complexity $Max$**: this is probably the trickiest parameter to set.
Historically we had [pretty big transactions](https://subnets.avax.network/p-chain/tx/27pjHPRCvd3zaoQUYMesqtkVfZ188uP93zetNSqk3kSH1WjED1) (more than $1.000$ referenced utxos). Setting a max block complexity so high that these big transactions are allowed is akin to setting no complexity cap.
On the other side, we still want to allow, even encourage, UTXO consolidation, so we may want to allow transactions [like this](https://subnets.avax.network/p-chain/tx/2LxyHzbi2AGJ4GAcHXth6pj5DwVLWeVmog2SAfh4WrqSBdENhV).
A principled way to set max block complexity may be the following:
* calculate the target block complexity rate (see previous point)
* calculate the median time elapsed among consecutive blocks
* The product of these two quantities should gives us something like a target block complexity.
* Set the max block complexity to say $\times 50$ the target value.
* **Normalization coefficient $Denom$**: I suggest we size it as follows:
* Find the largest historical peak, i.e. the sequence of consecutive blocks which contained the most complexity in the shortest period of time
* Tune $Denom$ so that it would cause a $\times 10000$ increase in the fee rate for such a peak. This increase would push fees from the milliAVAX we normally pay under stable network condition up to tens of AVAX.
* **Minimal fee rates $r^{min}$**: we could size them so that transactions fees do not change very much with respect to the currently fixed values.
We simulate below how the update formula would behave on an peak period from Avalanche mainnet.
 />
/>
 />
/>